Linux下的grep工具linux grep输出,我对它的初步了解是,它非常实用,在文本处理和数据分析领域有着重要作用。它能迅速从大量文本中挑选出所需信息。通过精确设定匹配标准,grep能够灵活展示所需内容。对于Linux用户而言linux grep输出,熟练掌握grep的输出功能,是一项非常重要的技能。
基本语法
grep 的用法并不复杂,通常遵循“grep [选项] 搜索词 [目标文件]”这样的格式。这里的“搜索词”就是我们想要查找的关键内容,“目标文件”则是grep将要扫描的文本。运用这样的命令组合中国linux,grep便能在指定的文件中找到包含该关键词的行。例如,若要在“test.txt”文件中寻找“example”这个词,只需输入“grep example test.txt”命令,就能得到相应的输出。掌握基本语法是使用grep的基础,只有打好基础,才能进行更高级的操作。
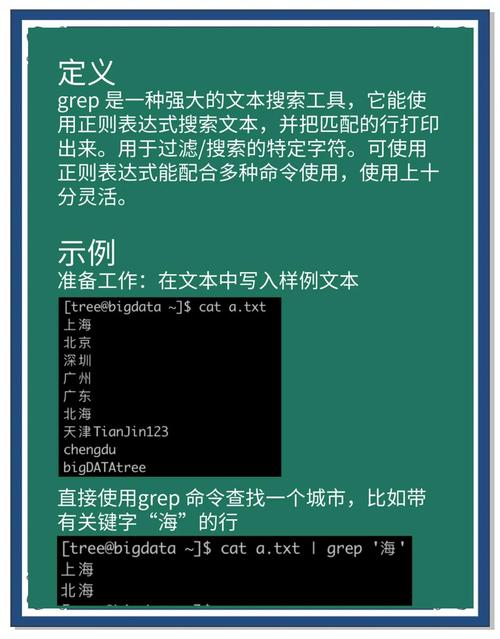
使用基础语法时,需留意“模式”的书写,力求精确且简洁,以免误匹配多余信息。如果不设定文件,grep会自动从标准输入读取。这在需要使用管道连接命令时特别有用。初学者可以通过操作简单文件来练习,以便迅速学会基础语法的运用。
常用选项
i 是grep命令的一个常用参数,它能实现不区分大小写的搜索功能。举例来说,若要在包含大小写差异的文档中查找“apple”,只需执行“grep -i apple file.txt”,不论文档中是“Apple”、“APPLE”还是“apple”,都能被检索到。而-v参数则用于反转搜索结果,用于筛选出不包含特定模式的行。当需要排除特定信息时,这个功能尤为有用。

此外,选择-n可以让我们在输出结果中看到匹配行的序号,这有助于我们更精确地找到文件中匹配内容的具体位置。若要计算匹配的行数,只需使用-c选项,即可直接获得结果。这些常用的选项极大地增强了grep的功能,使我们能够根据实际需求获得更加精确的输出信息。
正则表达式匹配
正则表达式赋予了grep命令强大的搜索功能。例如,符号“^”能识别行首位置。输入“grep ‘^hello’ test.txt”后,就能筛选出以“hello”开头的那些行。而符号“$”则用来识别行尾,“grep ‘world$’ test.txt”命令则能找到以“world”结尾的行。

通过正则表达式的字符集功能,可以实现更深入的匹配操作。例如,“[0-9]”能识别所有数字,“[a-zA-Z]”则能识别字母。将这些字符与量词相结合,比如“{n}”代表重复n次,用“grep ‘[0-9]{3}’ file.txt”命令就能筛选出含有三个连续数字的行。正则表达式使我们从简单的关键词搜索过渡到了基于规则的搜索。
与其他命令联用
grep 经常与管道符号“|”配合使用。例如,与“ls”结合,“ls -l | grep ‘.txt’”这一命令可以筛选出具有.txt后缀的文件。首先,“ls -l”命令会列出当前目录下的文件详细信息,然后通过管道将信息传递给grep命令进行筛选。同样,与“find”命令结合也十分实用,“find / -name ‘*.conf’ | grep ‘example’”可以在整个系统中搜索包含“example”字样的配置文件。
使用“sort”命令,结合“grep ‘keyword’ file.txt | sort”,可以筛选出包含特定关键词的行,并对这些行进行排列。若与“uniq”一同使用,即“grep ‘keyword’ file.txt | sort | uniq”,则能进一步消除重复的行。这种组合运用,将多个命令的功能整合,使得对文本的处理和分析变得更加高效。
彩色高亮输出

运行 grep 命令时,若启用彩色高亮功能,能帮助我们更直观地识别出匹配结果。只需在命令中加入 “--color=auto” 这一参数,例如 “grep --color=auto ‘关键词’ 文件名.txt”,这样匹配到的关键词就会以彩色呈现。这在浏览大量文本时特别有用,可以快速锁定重要信息。
若想使颜色更加醒目,调整环境变量是个好办法。比如,在“~/.bashrc”文件里加入“alias grep=’grep --color=always’”这一指令,那么每次调用grep时,结果都会以彩色形式高亮显示。这样的彩色高亮显示,能显著改善我们查看grep输出的体验,减少视觉上的疲劳感。
输出结果保存
运行 grep 命令后,输出的信息通常很有用。想要保存这些信息,操作十分简便linux命令详解词典,只需用大于号“>”做重定向即可。比如,“grep ‘info’ data.txt > result.txt”这条命令,就能将包含“info”的行存入“result.txt”文件中。若想往现有文件中继续添加内容,就应使用双大于号“>>”,像“grep ‘newinfo’ data.txt >> result.txt”这样,就能将新找到的匹配内容加入到文件末尾。
保存完毕后,便于后续的深入分析和查阅。若文件体积较大,我们可以在保存之前,通过其他指令对结果进行初步处理,比如进行排序或去除重复项,以确保保存的数据更加整齐。在日常工作操作中,大家要注意及时保存那些有价值的输出信息。
在使用 Linux grep 命令输出过程中,大家是否遇到过难以解决的匹配难题?若觉得本文对您有所帮助,请点赞并转发!
