【十五】逻辑备份(导入)与恢复(导出)
18.1传统的导出导入exp/imp:
18.1.1概述
传统的导入导出程序指的是exp/imp,用于施行数据库的逻辑备份和恢复,导入程序exp将数据库中对象的定义和数据备份到一个操作系统二补码文件中,导出程序imp读取二补码导入文件并将对象定义和数据载入数据库中。
18.1.2特性
传统的导入导出是基于顾客端设计的,在$ORACLE_HOME/bin下,导入和导出实用程序的特征有:
1)可以按时间保存表结构和数据
2)容许导入指定的表,并重新导出到新的数据库中
3)可以把数据库迁移到另外一台异构服务器上
4)在两个不同版本的Oracle数据库之间传输数据(顾客端版本不能低于服务器版本)
5)在联机状态下进行备份和恢复
6)可以重新组织表的储存结构,降低行迁移及c盘碎片
18.1.3交互方法
使用以下三种方式调用导入和导出实用程序:
1交互提示符:以交互的形式提示用户挨个输入参数的值。
3参数文件:准许用户将运行参数和参数值储存在参数文件中,便于重复使用参数。
18.1.4导出导入模式
导入和导出数据库对象的四种模式是:
1数据库模式:导入和导出整个数据库中的所有对象。
2表空间模式:导入和导出一个或多个指定的表空间中的所有对象,10g新增添可传输表空间。
3用户模式:导入和导出一个用户模式中的所有对象。
4表模式:导入和导出一个或多个指定的表或表分区。
18.2导出导入示例
18.2.1导出导入表
1)scott导出导入自己的表linux 中文字符集,通常是从服务器导入到顾客端(在cmd下操作)
SQL>create table emp1 as select * from emp;
SQL>create table dept1 as select * from dept;
C:>exp scott/scott@prod file=d:empdept1.dmp tables=(emp1,dept1)
再导入server里
SQL> drop table emp1 purge;
SQL> drop table dept1 purge;
C:>imp scott/scott@prod file=d:empdept1.dmp2)sys导入scott表
SYS用户可以exp/imp其他用户的object,是由于SYS富含EXP_FULL_DATABASE和IMP_FULL_DATABASE角色。
C:>exp 'sys/system@prod as sysdba' file=d:sysscott.dmp tables=(scott.emp1,scott.dept1)
scott导入(报错)
C:>imp scott/scott@prod file=d:sysscott.dmp
报错:IMP-00013: 只有 DBA 才能导入由其他 DBA 导出的文件
IMP-00000: 未成功终止导入
C:>imp 'sys/system@prod as sysdba' file=d:sysscott.dmp fromuser=scott18.2.2导出导入用户
当前用户scott导入自己的所有对象,注意仅仅导入的是schema的object,也就是说这个导入不包括数据字典中的信息,例如用户帐户,及原有的一些系统权限等等。
C:>exp scott/scott@prod file=d:scott.dmp owner=scott 所有segment name的表才能导出,注意deferred_segment_creation问题
SQL> drop user scott cascade;
SQL> grant connect,resource to scott identified by scott;
C:>imp scott/scott@prod file=d:scott.dmp
如果用sys来完成也可以使用如下命令:
C:>imp 'sys/system@prod as sysdba' file=d:scott.dmp fromuser=scott touser=scott
sys用户也可以将导出的scott的内容导入给其他用户
C:>imp 'sys/system@prod as sysdba' file=d:scott.dmp fromuser=scott touser=tim
18.2.3导出导入表空间
Oracle10g后,引入了导出导入可传输表空间技术,使表空间的迁移更推动速高效:
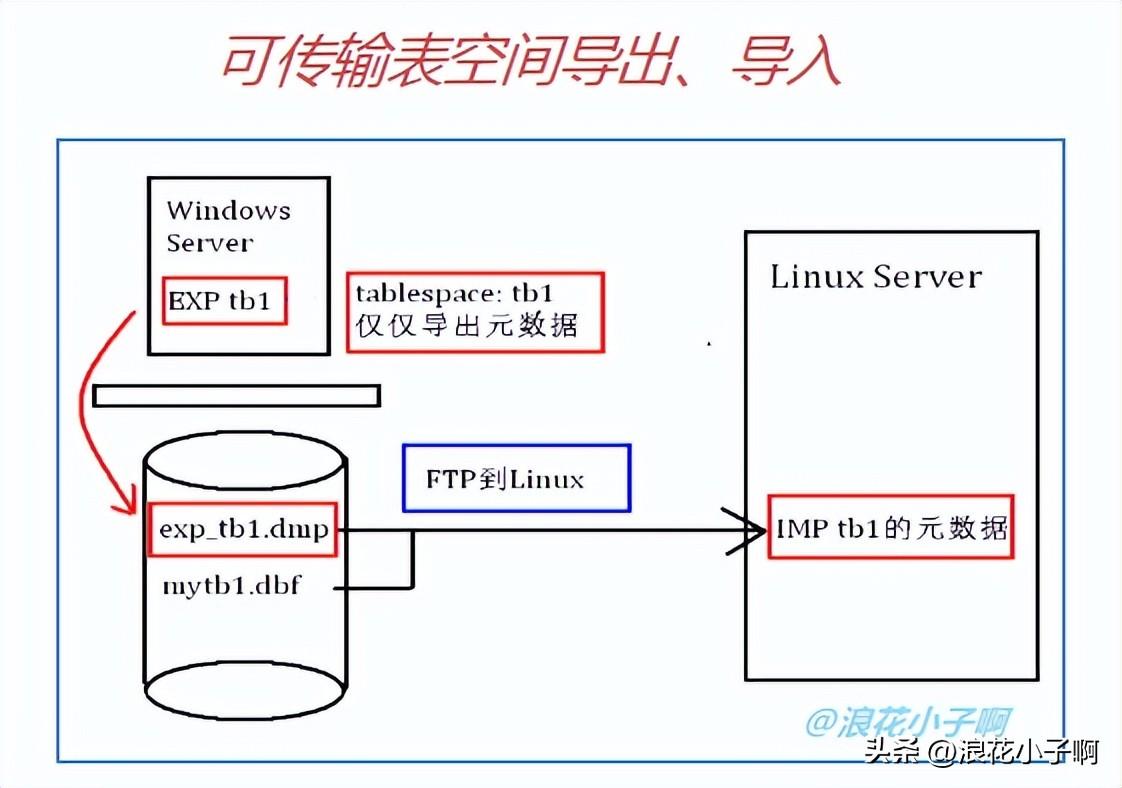
模拟场景:xp/orcl到linux/(英文字符集)可传输表空间的导出导入:
1)在xp/orcl上构建表空间
sys:
SQL>create tablespace tb1 datafile 'd:/mytb1.dbf' size 5m;
scott:
create table t1(year number(4),month number(2),amount number(2,1)) tablespace tb1;
insert into t1 values(1991,1,1.1);
insert into t1 values(1991,2,1.2);
insert into t1 values(1991,3,1.3);
insert into t1 values(1991,4,1.4);
commit;2)导入tb1表空间,先设为只读;
sys:
SQL>alter tablespace tb1 read only;
xp:cmd下
C:>exp '/ as sysdba' tablespaces=tb1 transport_tablespace=y file=d:exp_tb1.dmp3)以xmanager把exp_tb1.dmp和MYTB1.DBF都上传到linux/prod里
目录如下:/u01/oradata/prod4)在linux的$下执行导出
[oracle@prod ~]$ imp userid='/ as sysdba' tablespaces=tb1 transport_tablespace=y file=/u01/oradata/prod/exp_tb1.dmp datafiles=/u01/oradata/prod/MYTB1.DBF5)步入linux/prod下验证
sys:
SQL>select tablespace_name,status from dba_tablespaces;
SQL>select * from scott.t1;6)重设回读写方法
SQL>alter tablespace tb1 read write;说明:可传输表空间须要满足几个前提条件:
①原库和目标库字符集要一致。
②字符序有大端(bigendian)和小端(littleendian)之分,通过v$transportable_platform查看,倘若不一致可以使用rman转换。
③compatible10.0.0.或更高。
④迁移的表空间要自包含(selfcontained)。
哪些叫自包含:当前表空间中的对象不依赖该表空间之外的对象。
比如:有TEST表空间,上面有个表叫T1,假如在T1上建个索引叫T1_idx,而这个索引建在USERS表空间上,因为T1_idx索引是依赖T1表的,这么,TEST表空间是自包含的,可以迁移linux系统应用,但会赶走T1_idx索引,USERS表空间不是自包含的,不符合迁移条件。
检测表空间是否自包含可以使用程序包,如前面的事例:
SQL> execute dbms_tts.transport_set_check('TEST');
SQL> select * from TRANSPORT_SET_VIOLATIONS;
VIOLATIONS
------------------------------------------------------------------------------------------------------------------------
ORA-39907: 索引 SCOTT.EMP1_IDX (在表空间 TEST 中) 指向表 SCOTT.EMP1 (在表空间 USERS 中)。18.2.4导入整个数据库
C:>exp 'sys/system@prod as sysdba' file=d:full.dmp full=y18.3数据泵技术
18.3.1数据泵优点:
1)较传统的exp/imp速率提升1-2个数目级
2)重启作业能改进性能力
3)并行执行能力
4)关联运行作业能力
5)计算空间需求能力
6)操作网路形式
18.3.2数据泵组成部份:
①数据泵核心部份程序包:DBMS_DATAPUMP
②提供元数据的程序包:DBMS_MATADATA
③命令行顾客机(实用程序):EXPDP,IMPDP
18.3.3数据泵文件:
①转储文件:此文件包含对象数据
②日志文件:记录操作信息和结果
③SQL文件:将导出作业中的DDL句子写入SQLFILE指定的参数文件中
18.3.4数据泵的目录及文件位置
以sys或system用户完成数据泵的导出导入时,可以使用缺省的目录DATA_PUMP_DIR
SQL> select * from dba_directories;假如设置了环境变量ORACLE_BASE,则DATA_PUMP_DIR缺省目录位置是:
$ORACLE_BASE/admin/database_name/dpdump否则是:
$ORACLE_HOME/admin/database_name/dpdump18.4数据泵示例
18.4.1
①使用数据泵默认的directory
SYS@ prod>select * from dba_directories where directory_name='DATA_PUMP_DIR';
OWNER DIRECTORY_NAME DIRECTORY_PATH
------------------------------ ------------------------------ ------------------------------------------------------------
SYS DATA_PUMP_DIR /u01/admin/prod/dpdump/②为scott授予目录权限
SQL> grant read,write on directory DATA_PUMP_DIR to scott,tim;18.4.2数据泵导表
1)导入scott的empdept表,导入过程中在server端有MT表出现SYS_EXPORT_TABLE_01linux 中文字符集,导入完成后MT表手动消失
$expdp scott/scott directory=DATA_PUMP_DIR dumpfile=expdp_scott1.dmp tables=emp,dept瞧瞧目录下的导入的文件。
导出scott的表(导入的逆操作)
$impdp scott/scott directory=DATA_PUMP_DIR dumpfile=expdp_scott1.dmp2)导入scott的emp1的数据,但不导入结构:
$expdp scott/scott directory=DATA_PUMP_DIR dumpfile=expdp_scott1.dmp tables=emp1 content=data_only reuse_dumpfiles=y导出Scott的表(导出的逆操作)硬盘安装linux,只导出数据:
SQL> truncate table emp1;
$impdp scott/scott directory=DATA_PUMP_DIR dumpfile=expdp_scott1.dmp tables=emp1 content=data_only将scott.dept导出tim中
$ impdp userid='/ as sysdba' directory=data_pump_dir dumpfile=empdept.dmp tables=scott.dept remap_schema=scott:tim
18.4.3数据泵导用户
$ expdp system/oracle directory=DATA_PUMP_DIR dumpfile=scott.dmp schemas=scott注意与exp的区别,schemas取代了owner的写法
之后将所有对象导出tim
$ impdp system/oracle directory=DATA_PUMP_DIR dumpfile=scott.dmp remap_schema=scott:tim18.4.4数据泵可传输表空间(适用于大规模数据迁移)
①Win端须要directory早已构建了dir1
C:>expdp '/ as sysdba' directory=dir1 dumpfile=tb1.dmp transport_tablespaces=tb1②上传文件将TB1.DMP装入linux的/u01/admin/prod/dpdump/,MYTB1.DBF装入数据库目录/u01/oradata/prod/下。
③Linux端须要directory本例使用默认的数据泵directory
$impdp userid='/ as sysdba'
DIRECTORY=DATA_PUMP_DIR DUMPFILE=’TB1.DMP’ TRANSPORT_DATAFILES='/u01/oradata/prod/MYTB1.DBF'18.5数据泵直传示例
所谓直传就是通过网路在两个主机间导出导入(不落地),适用于大规模数据迁移
示例说明:将Linux端导出win端【可以表级、用户级、表空间级】。
步骤:
①需要构建一个dblink
②数据泵使用缺省的目录DATA_PUMP_DIR
③表空间直传比可传输表空间方法要慢的多,由于后者是select下来,insert进去,而前者是ftp传输数据文件
④设置flashback_scn参数,是当导入时假如数据库仍有读写操作,若希望得到某时间点的数据,这须要undo保证数据一致性
1)win端构建dblink,使顾客端能访问服务器端(win端指向Linux)
SQL> create public database link system_link connect to system identified by oracle using 'prod';2)win端直接使用impdp,不须要expdp。
①表级
C:UsersAdministrator>impdp system/oracle tables=tim.t1 network_link=system_link parallel=2 win端tim用户要存在②用户级
C:UsersAdministrator>impdp system/oracle schemas=tim network_link=system_link parallel=2 win端tim用户可以不存在,数据泵建立③表空间级
C:UsersAdministrator>impdp system/oracle tablespaces=test network_link=system_link parallel=2 相关用户和表空间要存在theend!!!
@jackman共筑美好!
