文章开始之前,我们首先得明晰几个问题:
问题1:哪些是数据库高可用(highavailability)
问题2:数据库高可用是必须的吗
问题3:PG的高可用是啥子模样
首先理一理高可用。如图所示,来自维基百科的释义:高可用性,IT术语,指系统无中断地执行其功能的能力,代表系统的可用性程度。
HA释义
简单来说,高可用就是当某一个服务(例如服务器)死掉了,对外提供的服务不能中断。通常是由诸多服务节点构成一个服务集群。普通用户是感知不到服务发生了中断。
那数据库须要高可用吗?其实是须要的,数据库也是重要的服务之一linux 删除文件,尽管它不是直接对外服务。试想一下,假若只有一个数据库,达不到高可用状态,发生意外挂掉了,这么所有服务都不能使用了。例如头条或微博的数据库挂了,这么我们就不能愉快地吃瓜打闹了。所以,数据库高可用是必须的。
作为大名鼎鼎的开源数据库linux培训学校,postgresql又是如何做到高可用呢。我们直接使用搜索引擎搜索一下。ps:关于技术查找,国外各类峰会是一锅炖,建议直接使用官网。
搜索结果
pgha
可见pg官方有自己的高可用解决方案。pg要如何解决高可用呢?
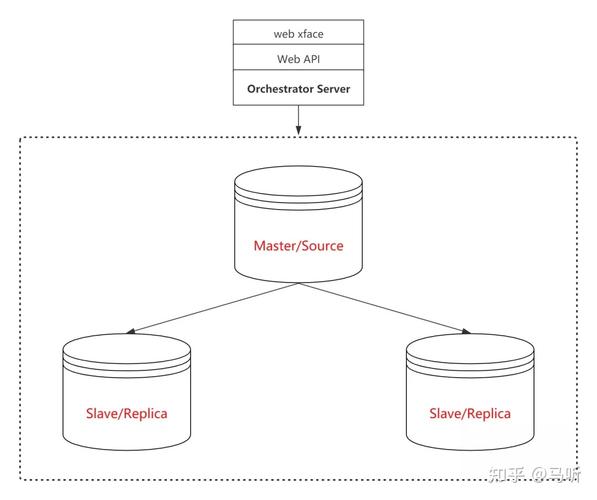
1)数据库集群,并保证数据一致性。
2)管理数据库集群,例如故障转移。
本文先学习PG数据库集群。数据库集群通常是主从模式,即是一个master,多个slave。主从的数据是一样的。这样同样可以做到读写分离。关于读写分离docker 高可用,暂时按下不表,前面专门写。pg有个StreamingReplication,即流复制。流复制是使用WAL(预读写日志文件)从主库传输到从库实现的。
复制方法分为同步流复制和异步流复制。同步流复制,主库须要等从库写完能够释放锁,因此对大量数据写入等情况不适宜,另外从库死掉了也会造成主库写入数据失败。而异步流复制则没有上述问题。延后一般也不会太多,网路良好的情况,通常不会超过一秒。
下边开始搭建两个数据库分别作为主库和从库,演示下配置异步流复制。
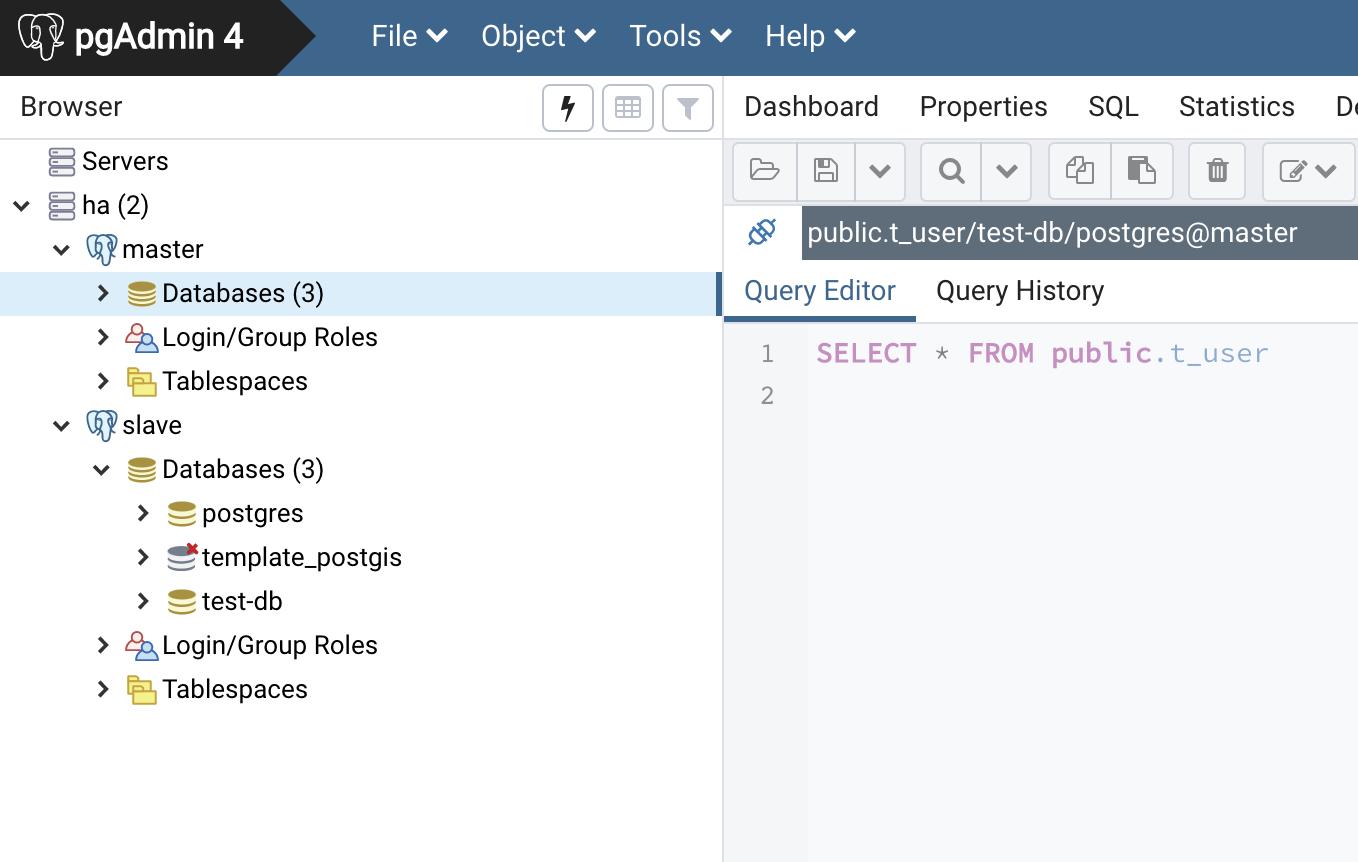
pgdb
上图是用docker快速搭建的两个数据库。首先配置下主库:
1)更改pg_hba.conf,容许从库从不同网路联接和复制
# allow replication
host replication all 0.0.0.0/0 md52)更改postgresql.conf,开启流复制模式
listen_addresses = '*'
wal_level = replica
max_wal_senders = 8 以上配置完成后须要重启下数据库。
接出来,配置下从库:
1)从主库获取现有的数据到从库
# pg_basebackup -h [ip] -U [username] -p [port] -F p -P -R -D [pgdata file path]
pg_basebackup -h 192.168.0.101 -U postgres -p 15446 -F p -P -R -D /home/master
2)拷贝到从库pg的data目录
cp -r /home/master/* /var/lib/postgresql/data/3)赋于权限
chown -R postgres:postgres /var/lib/postgresql/data/4)更改postgresql.conf
hot_standby = on以上配置完成后须要重启下数据库。
我们可以看见从库的数据和主库的数据是一样的。
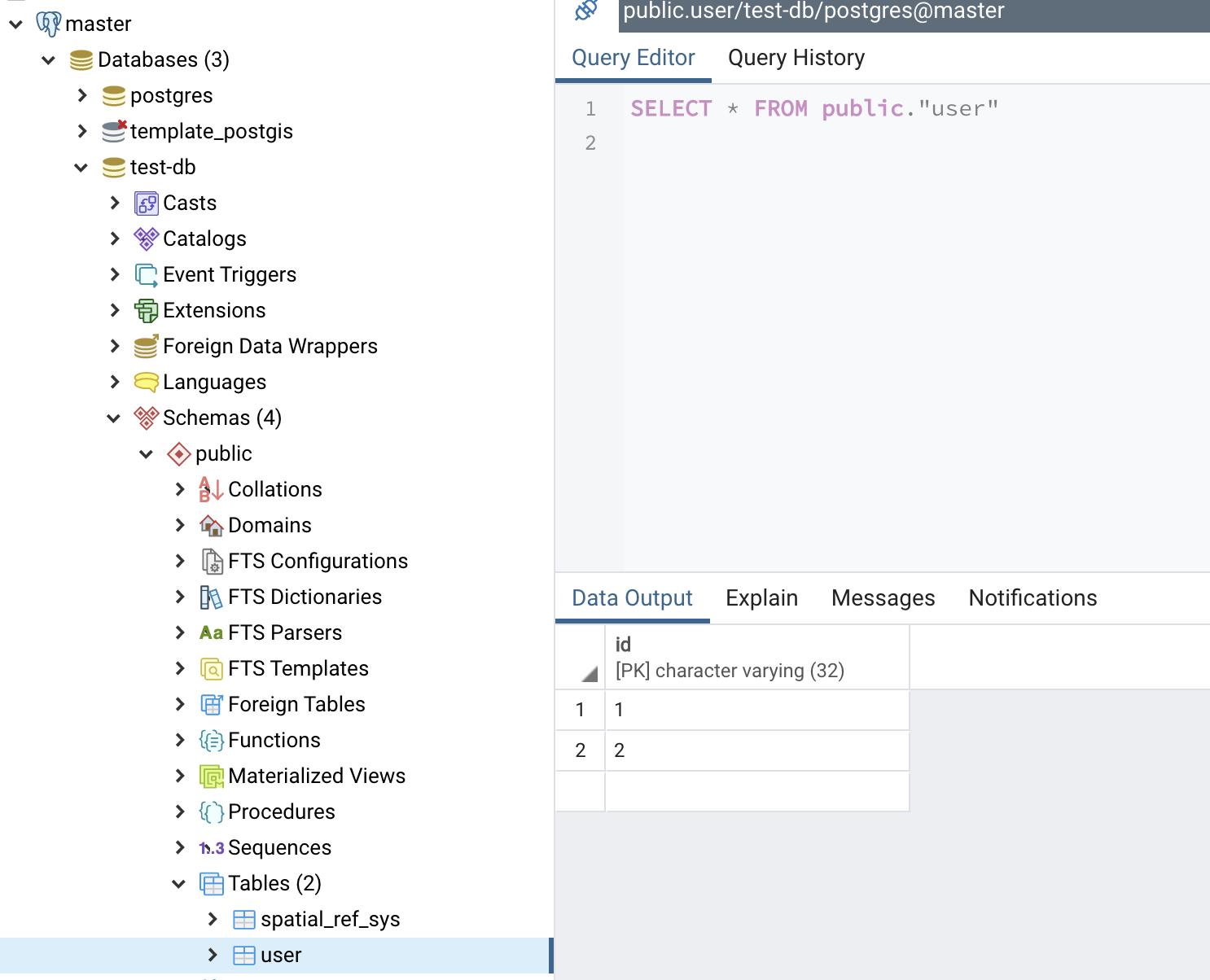
主库user表
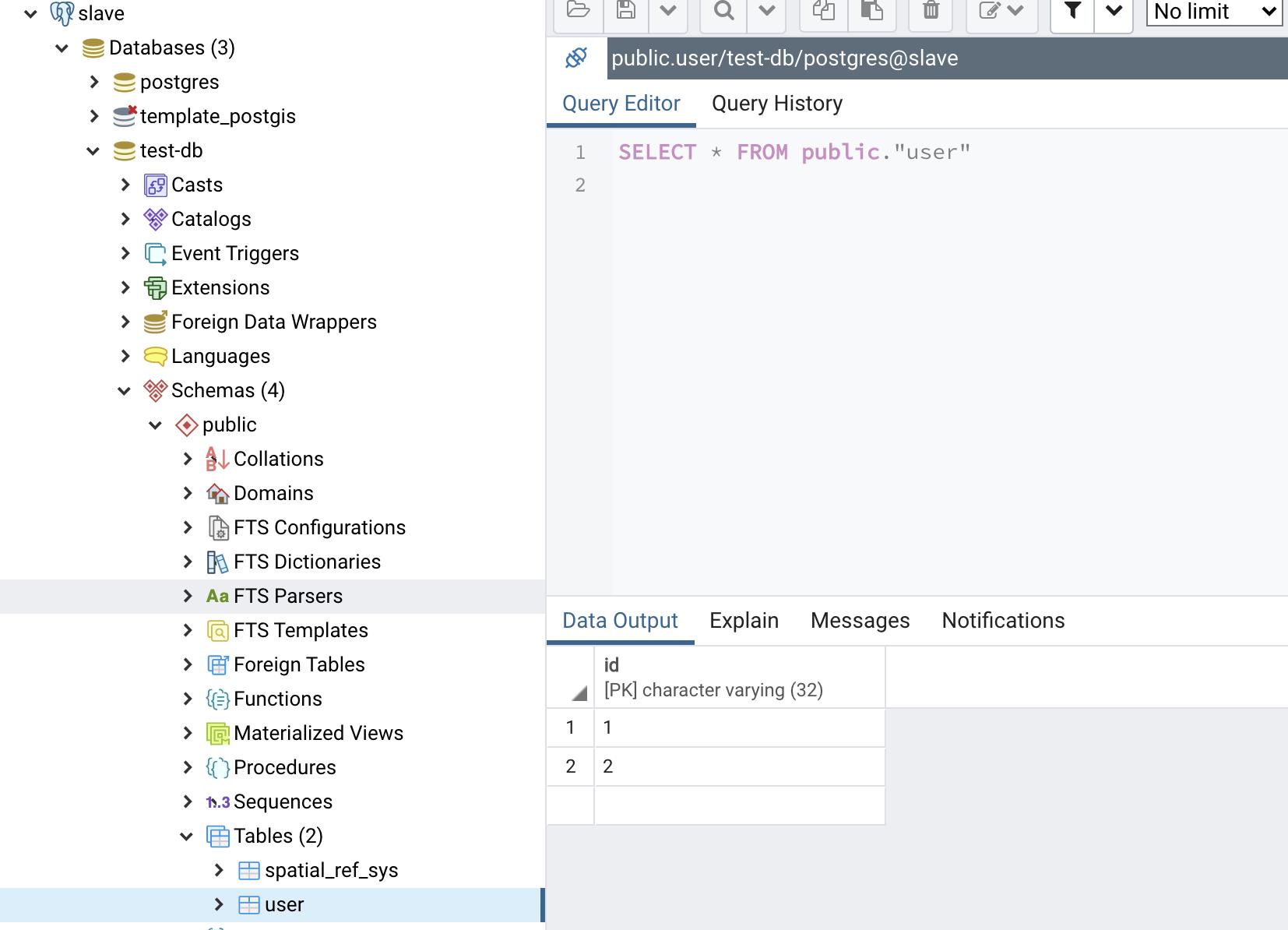
从库user表
我们新增下主库的数据,发觉从库也同步了。
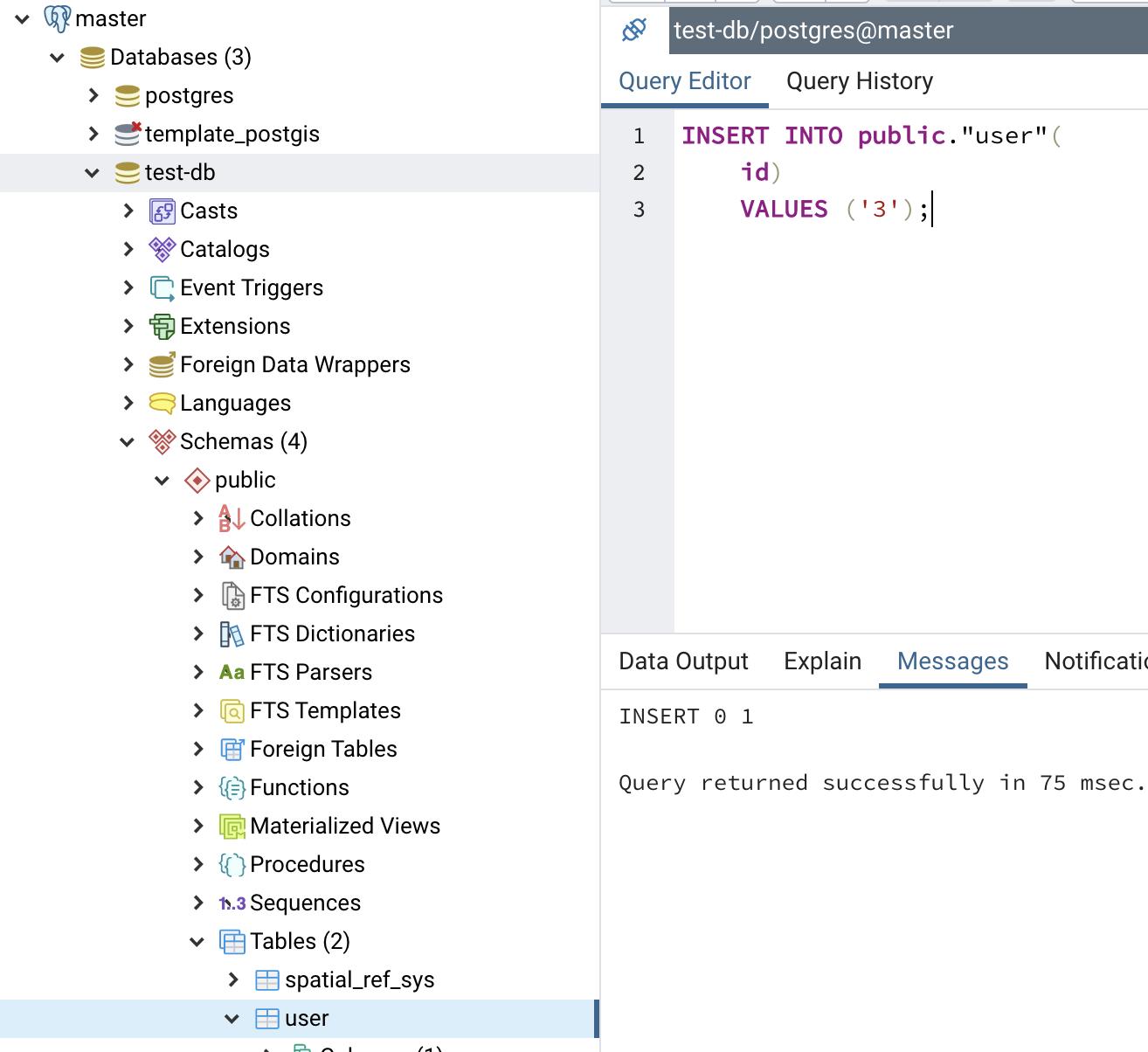
主库新增记录
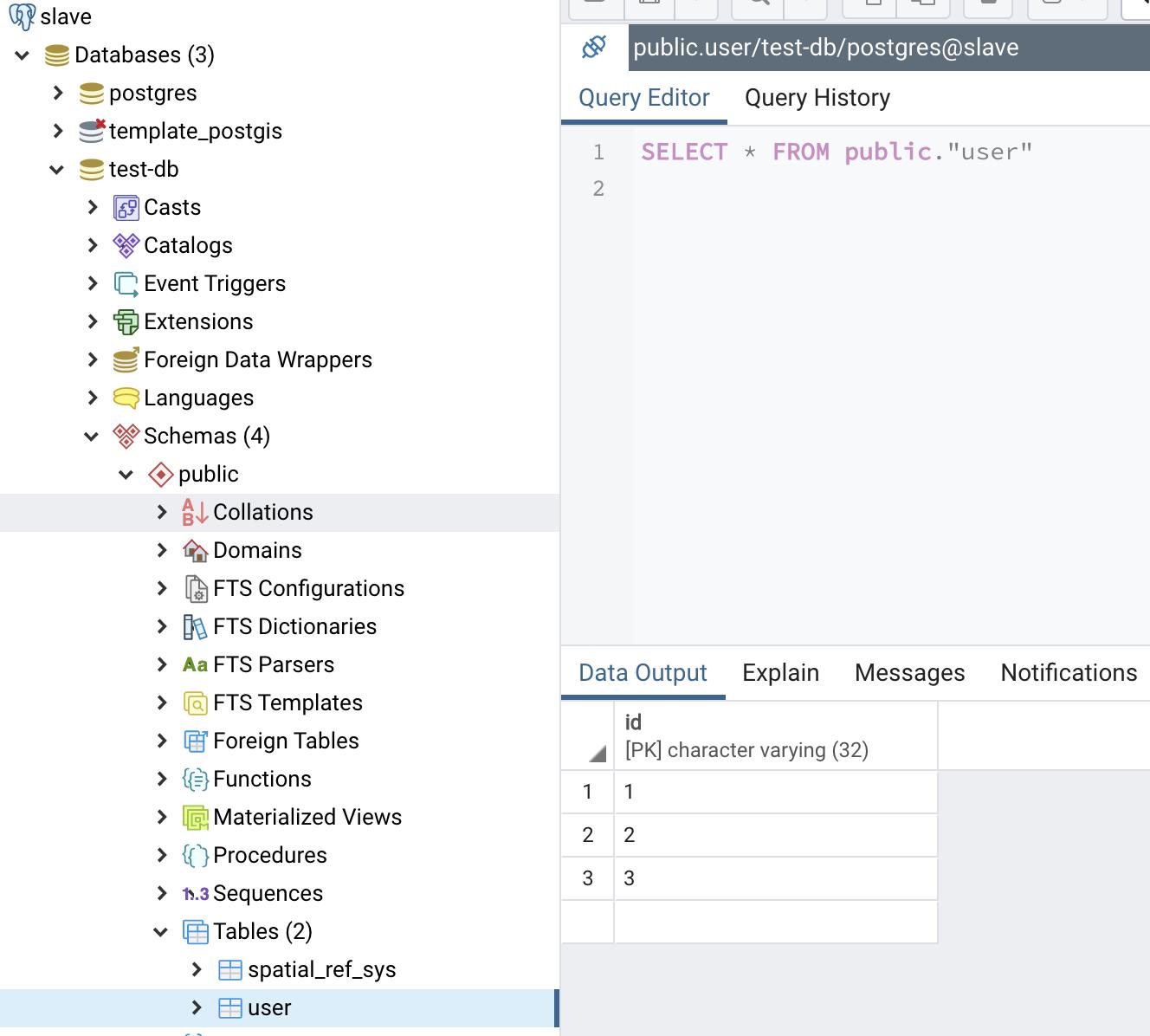
从库同步成功
至此,pg的异步流复制已完成。下一篇,我们将继续介绍和学习pg高可用的其它内容docker 高可用,敬请期盼。
