前言
《新设计团队Linux内核设计的艺术:图解Linux操作系统架构》这本书用大量直观的图解,把看似晦涩的内核源码和运行机制拆解得清清楚楚。我作为一名多年从事Linux系统开发的工程师,深知内核学习最大的痛点就是抽象的数据结构和复杂的调用关系,而图解方式恰好能突破这个障碍。本文将从实践角度,带你深入理解这本书揭示的Linux内核设计精髓。
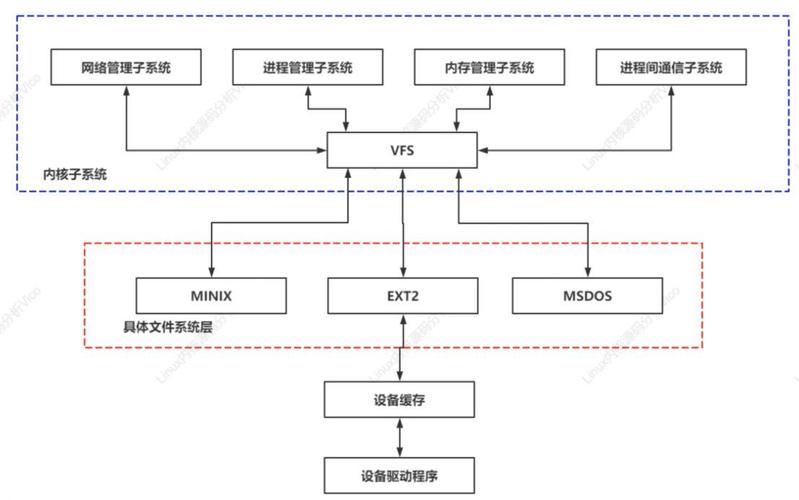
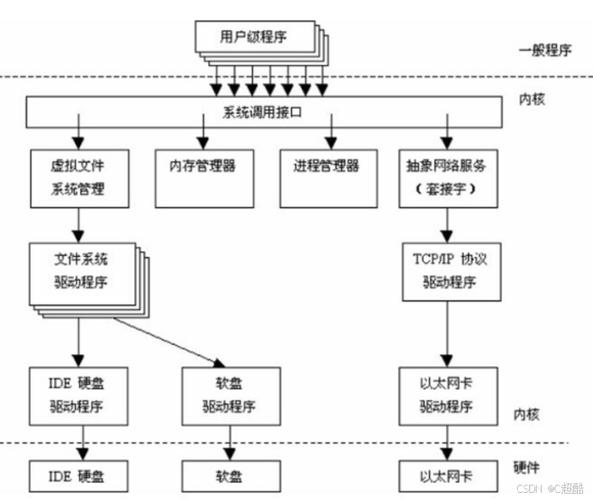
Linux内核整体架构图怎么看

翻开书的第一张全景架构图,你会看到内核被分为用户空间、内核空间和硬件层三个大层次。内核空间又细分为系统调用接口、进程管理、内存管理、文件系统、设备驱动和网络协议栈六大模块,每个模块之间通过函数调用和共享数据结构进行通信。这张图的关键价值在于让你一眼看清代码运行的宏观脉络,避免陷入局部细节。
实际阅读时,建议先用十分钟盯着这张图梳理出“系统调用触发内核服务”的主线。比如你执行read()函数,请求会经过VFS层、具体文件系统、块设备层,最终到达磁盘驱动。每个模块在图上的位置和连接线都对应了源码中的函数调用链,后续学习各模块时不断回看图,就能建立“见木见林”的认知。
进程管理核心机制是什么
Linux把进程描述为task_struct结构体,里面包含状态、PID、调度策略、内存映射指针、文件系统指针等上百个字段。新设计团队的图解最精彩之处,就是把这个庞大数据结构拆成“进程身份”“进程状态”“进程资源”“进程调度”四个功能块,并用不同颜色标注字段间的关联。例如需要切换进程时,CPU会先保存当前进程的硬件上下文到内核栈,然后加载新进程的上下文。
调度算法是进程管理的灵魂。书中用时间轴图展示了CFS(完全公平调度器)如何通过虚拟运行时间保证每个进程获得公平的CPU份额。当你在服务器上运行高负载计算任务时,CFS会动态调整优先级,确保交互式应用依然流畅。理解了这个机制,你就能明白为什么Nginx这种网络程序要设置worker进程数为CPU核心数,并且绑定CPU亲和性。
内存管理如何实现高效
虚拟内存地址空间是每个进程独享的4GB大房子linux伊甸园论坛,而物理内存是真实存在的砖块。书中用“页表映射图”清晰展示了线性地址到物理地址的三级转换过程:CR3寄存器指向页目录,页目录指向页表,页表最终找到物理页框。这种分页机制让多个进程可以安全地共享物理内存,比如动态链接库只需在物理内存中保留一份副本。
缺页异常处理是内存管理的核心性能点。当程序访问的虚拟地址没有对应的物理页框时,CPU会触发缺页异常,内核根据情况执行“按需分配”“写时复制”或“换入换出”。以fork()系统调用为例,子进程会共享父进程的物理页框,只有修改时才会复制一份。这种设计大大减少了内存消耗新设计团队linux内核设计的艺术:图解linux操作系统架,这也是为什么Redis在持久化时使用fork能瞬间完成内存快照。
文件系统与VFS设计原理
VFS(虚拟文件系统)是Linux支持数十种文件系统的秘密武器。书中用“抽象接口层图”展示了VFS如何定义统一的super_block、inode、dentry、file四个对象,而每种具体文件系统只需要实现这些对象的操作函数。比如你挂载ext4分区和FAT32的U盘,应用程序用open()/read()访问时,内核会自动调用对应的底层驱动。
路径解析的过程特别考验设计功力。当用户输入“/home/user/file.txt”,内核从根目录的dentry开始,逐层查找并缓存到dcache中。书中用序列图展示了查找过程中如何利用缓存加速,如果缓存未命中则调用具体文件系统的lookup函数。实际调优时,你可以通过修改/proc/sys/fs/dentry-state来调整dcache大小,显著提升大量小文件场景下的文件访问性能。
设备驱动模型怎样工作

Linux设备驱动借助platform、PCI、USB等总线将设备与驱动分离。书中用“驱动注册匹配图”描绘了当内核发现一个新设备时,会在总线上遍历所有已注册的驱动,调用probe函数进行匹配。这种设计让你写驱动时无需修改内核核心代码,只需实现探测、中断处理、读写等标准接口,然后通过module_init注册即可。
中断处理分为上半部和下半部是Linux驱动的高效所在。外部设备触发中断后,CPU立即执行上半部的紧急处理(如清中断标志、拷贝少量数据),然后唤醒下半部(使用软中断、tasklet或工作队列)来执行耗时任务。书中用时序图对比了三种下半部实现机制的使用场景。比如网卡驱动,上半部只把数据包拷入内存,下半部交给软中断处理协议栈,这样不会阻塞其他中断。
网络协议栈数据流如何传递

数据包从网卡到应用程序的旅程堪称经典。书中用“分层处理流程图”展示了当网卡收到以太网帧后新设计团队linux内核设计的艺术:图解linux操作系统架,中断上半部将数据放入sk_buff结构,软中断调用netif_receive_skb进入链路层。然后根据协议类型(0x0800为IP)交由IP层处理,IP层做完分片重组和路由查找后,再交给UDP或TCP层。TCP层根据端口号找到对应的socket,最终唤醒等待的进程。
发送方向的数据流正好相反。应用程序调用send()时,内核将用户态数据拷贝到内核socket发送缓冲区,TCP层负责分段、拥塞控制和序列号管理,IP层添加IP头并可能分片,最后通过网卡驱动发送出去。书中用状态机图详细说明了TCP的慢启动、拥塞避免、快速重传等算法。理解这个数据流后红旗 linux,你就能分析出网络延迟可能出现在哪一层,比如大量小包导致软中断过高,就应该开启网卡的gro/gso特性。
你是否也曾因为内核源码的复杂度而望而却步?欢迎在评论区分享你啃Linux内核时遇到的最大障碍,或者点赞收藏本文,让更多开发者掌握图解内核的学习方法。
