Linux管道通信是操作系统内实现进程间数据交换的关键手段,它使得不同进程可以共享并传递信息,宛如构筑了一座信息交流的桥梁。这种机制在软件开发与运行过程中发挥着至关重要的作用,显著增强了系统的数据处理和交互能力。
管道通信概念
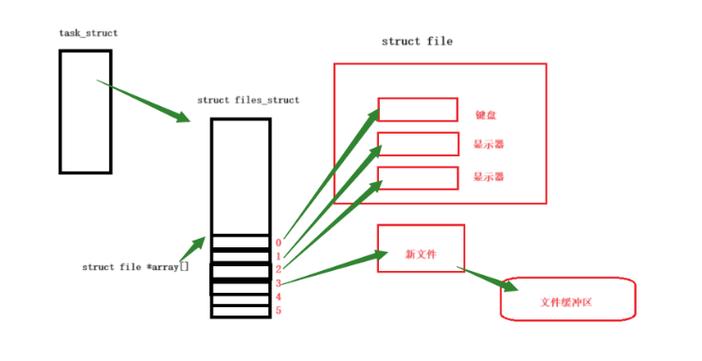
管道通信的基础在于构建一条数据传输的路径,通过这条路径,信息能够从一个程序传递至另一个程序。一般而言,一个程序充当数据的制造者,负责将信息存入管道;而另一个程序则扮演数据的接收者,从管道中提取信息。管道虽像是一种文件,却与常规文件有所区别,它仅存在于内存之中。数据在管道中只能单向移动,从写入端流向读取端,这样的流动方式确保了数据传输的有序进行。
在Linux操作系统中linux管道通信,管道是无名的,它们并不具备具体的文件标识。这类管道仅能在生成它们的进程及其派生进程中得以应用。这种无名的特性使得管道间的信息传递更为迅速,因为它们无需经历普通文件所需的繁琐文件系统操作。同时,管道的容量是有限的,一旦管道存储满载,写入数据的行为将会被暂时阻止,直至有数据被提取。
管道创建方式
在Linux系统里,通过调用pipe()函数,我们可以建立一条管道。这个函数会生成一个包含两个文件描述符的序列,一个用于读取数据,另一个用于写入数据。在C语言编程中,可以这样操作:创建一个名为pipefd的整数数组,包含两个元素。若pipe(pipefd)函数执行失败,则输出错误信息。若成功,pipefd数组的第一个元素pipefd[0]代表读取端,第二个元素pipefd[1]代表写入端。
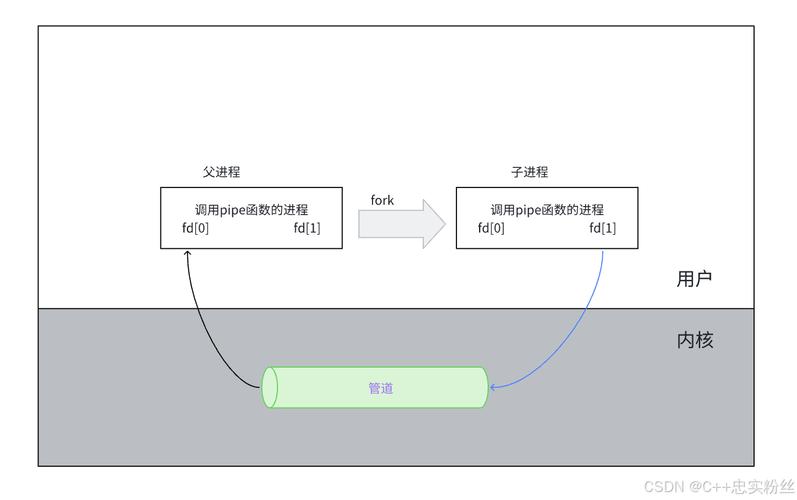
在shell里,我们可以用竖线符号“|”来构建管道。例如,执行“ls -l | grep ‘txt’”这条指令,就是将“ls -l”的输出结果传递给“grep ‘txt’”作为输入。这样做既方便又迅速,用户无需编写额外代码,只需在终端操作即可实现管道功能。
数据传输特点
管道的数据传输是按顺序进行的,写入的数据会按照顺序逐一被读取,确保了数据不会出现错乱。此外,管道中的数据是单次性的,一旦被读取linux管道通信,便会从管道中移除,不会重复被读取。这样的设计有助于节约系统资源,减少数据处理的冗余。
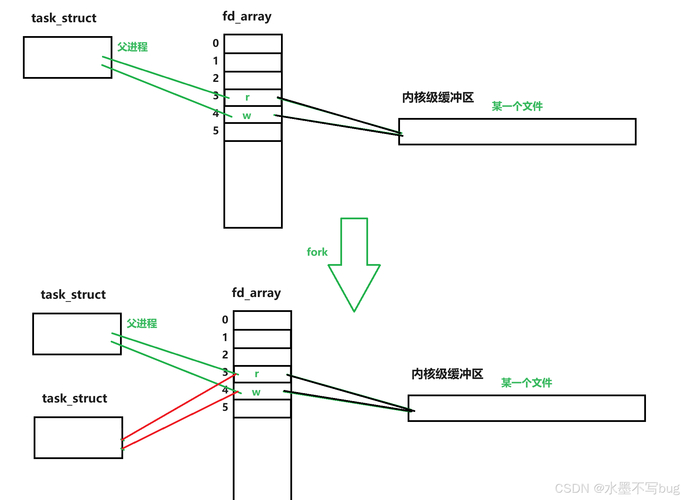
管道的数据传输是同步进行的。当写进程向管道存入信息linux使用教程,若管道已满,写进程便会暂停,直至管道腾出空间。而读进程从管道中提取信息,若管道为空,读进程同样会暂停,直至有新数据被写入。
同步机制机制
为确保管道数据传输的准确性,Linux系统引入了多样化的同步策略。例如,通过阻塞策略,若管道内容为空,读取操作将暂停;若管道已满,写入操作也将暂停。这一做法旨在保障数据顺利传输,防止出现数据丢失或重复读取的情况。
存在一种锁控机制,用于多个进程同时读取管道时确保数据的完整。只有成功获取锁的进程可以执行写入,其余进程需耐心等待。如此一来,便避免了多个进程同时写入管道可能引发的数据紊乱。
应用场景分析
管道通信在日志处理领域被普遍采用。以一个大型系统为例,其中存在多个负责生成日志的进程和一个负责分析日志的进程。生成进程会把日志数据存入管道,分析进程则从管道中提取数据进行处理。借助管道通信linux系统iso下载,日志的实时处理与分析得以实现。
在数据处理过程中,管道扮演着关键角色。比如,面对海量的数据,若需挑选出满足特定要求的部分,可以借助多个进程,通过管道逐一进行筛选。每个进程负责一个过滤环节,最终汇总出所需信息。
性能分析评估
管道通信的效能与系统资源的消耗紧密相连。因为管道在内存中构建,其读写速度通常较快。然而,若管道被频繁读写,会引发系统频繁的上下文转换,进而提升系统的整体开销。
管道的尺寸对性能有显著影响。管道若过窄,容易出现满载和空载现象,进而导致进程不断被阻塞和激活;而管道若过宽,则会消耗大量内存。因此,挑选恰当的管道尺寸,对提升管道传输效率极为关键。
在使用Linux的管道功能时,你有没有遇到过难题?如果你愿意,可以给这篇文章点赞并转发,然后在评论区分享你的遭遇。
