Linux操作系统中,du命令的源代码颇具趣味。此命令旨在展示磁盘空间的利用状况,并且能够准确计算出各个文件所占据的空间量。深入挖掘其源代码,我们可以洞悉命令的工作原理,同时也能根据实际情况对其进行调整,确保其在各种使用环境中都能达到最佳性能。接下来,我将从多个角度对du命令的源代码进行细致的分析。
核心算法实现
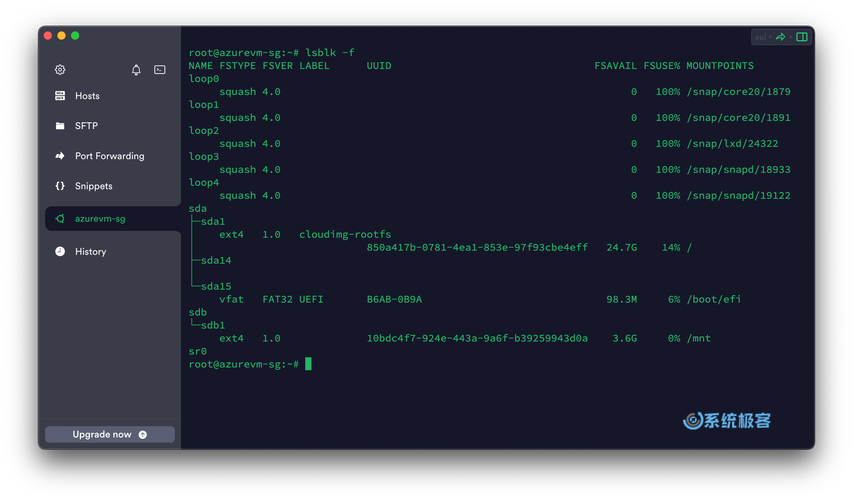
du命令主要用于对文件系统中的目录与文件进行详尽的检索,并统计它们各自占用的磁盘空间。在源代码层面,它通过递归算法来完成这一功能,具体来说,针对目录,它会递归地调用函数以深入到下一级子目录进行检索;而对于文件,它则直接读取并获取文件的大小数据。具体操作需要采用特定的文件访问方式linux服务器搭建,目的是为了获取文件的详尽信息,从而了解其实际大小和逻辑大小,这样做有利于数据的统计工作。这个算法设计得很巧妙,执行速度很快,它通过递归的方式对文件系统进行扫描,充分运用了其树形结构的特性,使得计数过程变得既简单又迅速。
数据结构设计
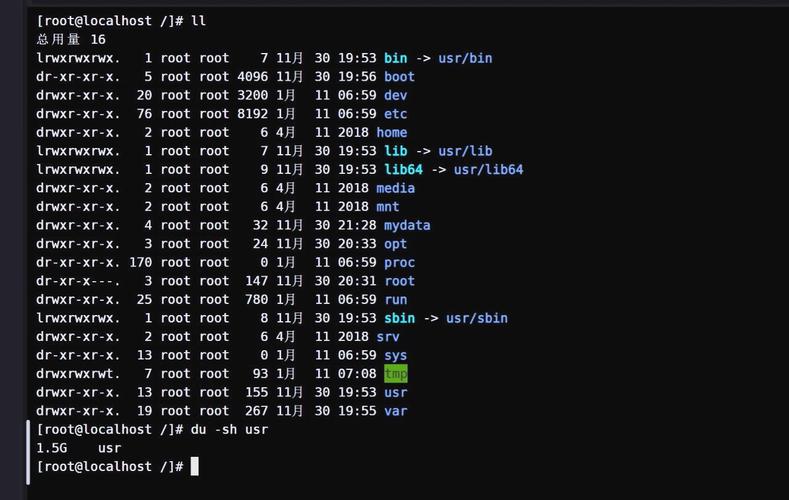
源码部分采用了设计合理且实用的数据结构来存储信息。例如,存在一种特定的结构用于表示文件与目录北京linux培训,该结构中包含了诸如文件名称、文件大小、访问时间等关键信息。通过这种结构,能够将目录的关联操作进行统一化处理,从而便于集中管理和操作。这种存储方式显著提升了数据的读取与计算速度,并且充分揭示了文件系统的详细信息,便于进行数据的统计分析,以及按照特定需求进行排序和输出。
参数解析策略
du命令的功能十分多样,涉及众多参数,所以在源码编写中,对参数的解读显得尤为重要。我们得先对用户输入的参数进行解析,然后根据这些参数来设定相应的标志,以便明确程序的具体操作。例如,当输入-h参数时linux du命令 源码,会激活一个标志,使得文件的大小以更符合人类阅读习惯的方式显示;而使用-s参数,程序只会展示总的信息。这种设计完全符合用户的需求,每个标志位都与一个特定的功能相对应。程序能够根据这些需求进行操作,并最终向用户展示定制的统计数据。
错误处理机制
源码里嵌入了一套严谨的错误处理系统,这确保了程序的稳定运行。在执行文件访问或查询文件大小等操作时,系统都装备了错误检测功能。若遇到文件权限不足无法访问,或是磁盘出现异常错误,程序不会直接崩溃,而是会展示详细的错误信息提示。随后,程序会跳过该文件或目录,继续执行正常操作。错误处理机制保证了指令在复杂多变的环境中准确无误地执行,并且确保用户能够及时获得详尽的数据信息linux du命令 源码,有效避免了因微小失误而无法得到预期结果的风险。
性能优化技术

为了提升性能,源码对代码进行了多方面的优化处理,比如在文件系统扫描环节,运用了缓存策略,以此降低对硬盘的读写次数。借助缓存存储文件系统数据,我们得以减少不必要的信息重复检索。另外,还引入了多线程技术,以加快扫描速度,例如在处理多个大型目录时,能够并行扫描,进而提升整体的工作效率。性能的增强不仅缩短了用户等待的时间,而且在处理大型文件系统方面,其效果尤为显著。
代码可维护性考虑

在源码开发的早期阶段,我们同样非常看重其后续的维护性。我们采用了模块化的设计理念,把不同的功能进行分类,分别封装在独立的函数或模块之中。例如,参数解析和遍历等操作,都有各自专门的模块来负责设计。这样一来,未来在需要修改或添加功能时,开发者只需关注对应的模块即可。这种模块化的结构不仅让代码变得容易看懂和修改,而且在添加新功能时,不需要对大量代码进行大规模的改动,有效地避免了因局部改动而对整体造成不良影响,保证了代码能够灵活适应需求的变化。
在使用du命令的过程中,您是否遇到了什么特别的情况?不妨在评论区留下您的见解。这篇文章对您有帮助的话,不妨点个赞,或者推荐给您的朋友。
