嵌入式Linux启动时间优化的秘密
01
工具链/应用程序优化
导读:嵌入式Linux在应用中常常希望系统能在尽量短的时间内启动,以提升用户体验。并且在有的应用场合,对启动时间具有严格的时间要求,尤其在工业或则医疗器械应用领域。此时怎么推动Linux的启动,将成为一个挑战,对于大多数应用开发人员而言,因为Linux系统的复杂性,对于怎样增强启动速率,常常无从下手。这么阅读完本文,将获得清晰完整的解决思路。
1.增加启动时间的通常思路
在打算增加系统的启动时间时,思路上应完善以下的切入点:
最快的代码是未执行的代码。
引导操作本质上的很大一部份工作实际上是将代码和数据从储存设备加载到RAM。如所需加载内容越少则意味着加载操作越快。
假如根文件系统越大,则安装时间可能会越长。
为此,虽然未执行的代码也会延长启动时间。
另外在硬件方案设计时尽量选择读写速率快的储存介质。比如,从SD卡启动实际上比从NANDFLASH启动快。
2.启动时间检测方式
要增加系统的启动时间,则首先须要选择一个可靠的启动时间的检测方式:
在Linux代码中加入对某一个GPIO脚的逻辑电平控制linux自启动c程序,借助示波器检测GPIO状态。前面将介绍怎样在代码中加入对GPIO的控制。
监控并口控制台报文以检测时间,可以使用grabserial。
参见
3.工具链优化
3.1从工具链入手
选择使用合适的工具链手机linux操作系统,应是第一个入手点,由于所有的运行加载固件都是由工具链编译而成。假如仍未进行其他优化,则修改工具链的益处将愈加显著,而且更容易测度。
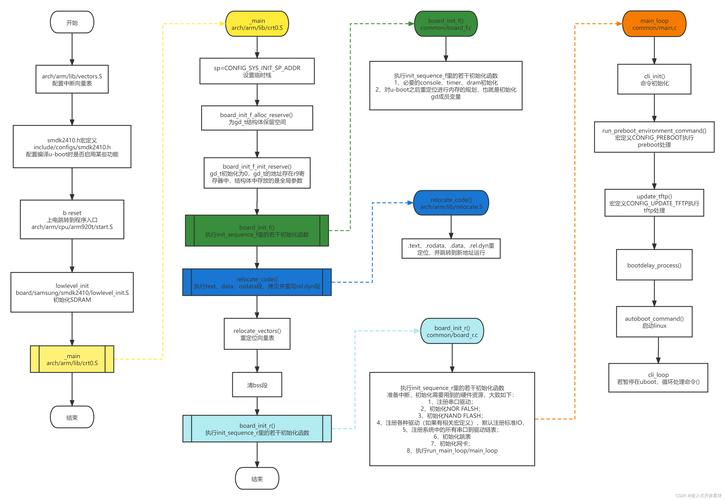
您可以在工具链中进行以下修改,这可能会影响启动时间,性能和大小:
编译器版本:gcc和binutils的版本,最新版本常常可以具有更好的优化功能。
C库:glibc,uClibc,musl。使用uClibc和musl库编译的根文件系统更小
指令集变量:ARM或Thumb2,是否支持硬浮点。
可能会影响代码性能和代码大小(Thumb2编码与ARM相同的指令linux自启动c程序,但以更紧凑的形式,起码会显着降低大小)。
C库在创建工具链时进行了硬编码,可供选择的C库:
glibc:最标准且功能最全。
uClibc:更小且可配置。早已存在约20年了。
musl:uClibc代替品,虽比较新但很成熟。
可以对glibc/uclibc-ng/musl进行对比测试:
1.静态编译hello.c程序并比较大小
使用gcc6.3,armel,musl1.1.16:7300字节
使用gcc6.3,armel,uclibc-ng1.0.22:67204字节
使用gcc6.2,armel,glibc:492792字节
2.静态编译BusyBox1.26.2并比较大小
使用gcc6.3,armel,musl1.1.16:183348字节
使用gcc6.3,armel,uclibc-ng1.0.22:210620字节
使用gcc6.2,armel,glibc:755088字节
3.2指令集选择
编译rootfs进行测试对比:
用gcc7.4编译,生成ARM代码:
根文件系统总大小:3.79MB
用gcc7.4编译,生成Thumb2代码:
根文件系统总大小:3.10MB(-18%)
性能方面:Thumb2的性能显著改善(大概多于5%,并且从一次运行到另一次运行,检测的执行时间略有变化)。
4.应用软件优化
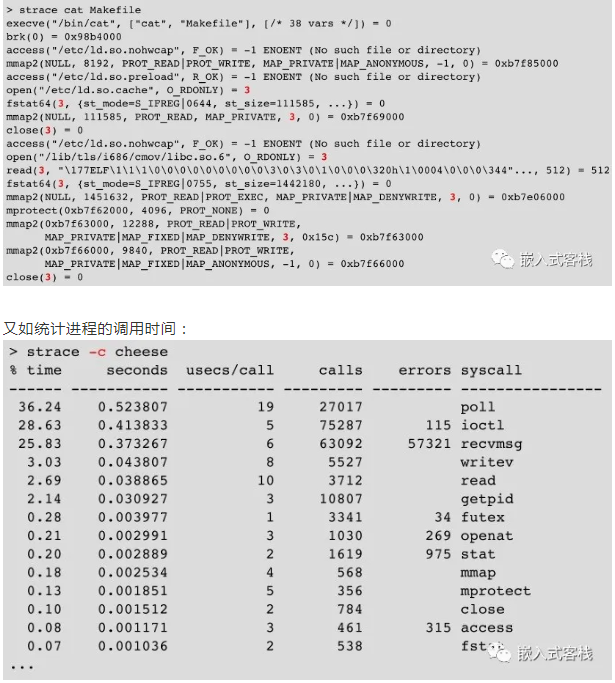
4.1检测strace
strace容许跟踪应用程序及其子级进行的所有系统调用。对于开发特别有用:
了解怎样在用户空间上耗费时间
比如,轻松查找打开尝试(open()),文件访问(read()/write())和显存分配(mmap2())。无需访问源代码即可完成!
找寻历时最长的开支应用
查找在应用程序和脚本中完成的毋须要的工作。诸如:多次打开同一文件linux服务器搭建,或尝试打开不存在的文件。
局限性:您难以跟踪init进程!
关于strace参见
:
在所有GNU/Linux系统上可用,可以由您的交叉编译工具链生成器建立。
更简单的办法:直接拷贝一个现成的静态二补码文件。参见
可以查看进程的操作情况:
1.访问文件,分配显存。。.

2.一般足以发觉简单的错误。
用法:
1.strace《命令》(开始一个新进程)
2.strace-p《pid》(跟踪现有进程)strace-c《command》(统计进程的系统开支时间)
如查看cat操作:
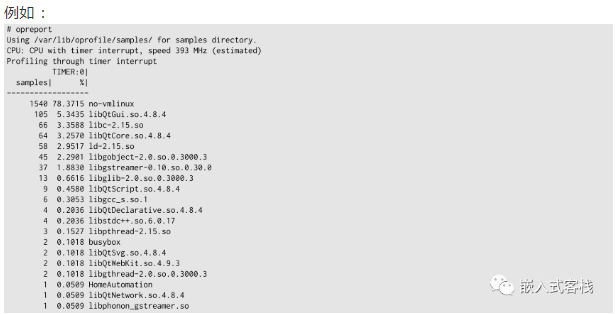
4.2Linux上的性能检测工具oprofile
Oprofile是linux上的性能检测工具:
具有两种工作方法:legacy模式和perf_events模式
legacy模式:
1.精度低,请使用内核驱动程序进行配置
2.使用CONFIG_OPROFILE进行编译配置
3.用户空间工具:opcontrol和oprofiled
perf_events模式:
1.使用硬件性能计数器
2.使用CONFIG_PERF_EVENTS和CONFIG_HW_PERF_EVENTS编译配置
3.用户空间工具:operf
其使用方式:
legacy模式:
opcontrol--vmlinux=/path/to/vmlinux#opTIonalstep
opcontrol--start
/my/command
opcontrol--stop
perf_events模式
operf--vmlinux=/path/to/vmlinux/my/command
借助opreport获取结果
4.3perf工具
Perf是外置于Linux内核源码树中的性能分析(profiling)工具。它基于风波取样原理,以性能风波为基础,支持针对处理器相关性能指标与操作系统相关性能指标的性能分析。可用于性能困局的查找与热点代码的定位。linux2.6及后续版本都自带该工具,几乎才能处理所有与性能相关的风波
使用硬件性能计数器
使用CONFIG_PERF_EVENTS和CONFIG_HW_PERF_EVENTS进行配置
用户空间工具:性能。它是内核源代码的一部份,因而一直与您的内核同步。
用法:perfrecord/my/command
通过以下方法获得结果:perfreport

4.4联接器优化
启动时使用的应用程序组代码:
查找启动期间调用的功能,比如使用
-finstrument-funcTIonsgcc选项。
创建一个自定义的链接描述文件,以按调用次序重新排列这种函数。可以通过将每位函数放到各自的部份中来实现:
-ffuncTIon-sectionsgcc选项。
非常对于具有较大MTD读取块的闪存储存非常有用。由于读取整个读取块后,极有可能读取毋须要的数据。
详尽信息:
通过如下方式,可以找到有望被优化的地方:
1.启动一次应用程序并检测其启动时间。
2.再度启动应用程序并检测其启动时间。因为它的代码应仍在Linux文件缓存中,故其代码加载时间将为零。
因而晓得第一次加载应用程序代码(及其库)所耗费的时间。链接器优化节约的时间应少于此上限。
之后据此可以决定是否有必要这样对该应用进行链接优化。因为链接优化必须更改应用程序的编译方法,因而这种优化的成本很高。
4.4.1Prelink预链接工具
Prelink是RedHat开发者JakubJelinek所设计的工具,正如其名子所示,Prelink借助事先链接取代运行时链接的方式来加速共享库的加载,它除了可以推动起动速率,还可以降低部份显存开支,是各类Linux构架上用于降低程序加载时间、缩短系统启动时间和推进应用程序启动的很受欢迎的一个工具。
预链接降低了启动可执行文件所需的时间
必须配置为晓得什么库须要进行预链接,并将为每位可用符号分配一个固定的地址,因而去除了在启动可执行文件时重新定位符号的须要。
请注意安全性,由于可执行代码仍然加载在同一地址。
代码以及文档参见
支持ARM,但自2013年以来未发布。Buildroot也不支持。并且,x86比较容易实现。
工具链/应用程序优化的部份就在此结束了,上篇我们将继续讲嵌入式Linux启动时间优化的方式之文件系统,请你们继续关注我们电子感冒友网和嵌入式酒店。
编辑连载推荐:嵌入式Linux启动时间优化的秘密之二文件系统
