整理/LiveVideoStack
你们好,我本次分享的主题是FreeSWITCH高可用布署与云原生集群布署,主要是谈一谈从高可用到弹性伸缩的一些技术应用。

具体包含以下相关内容:双机、三机,到可弹性伸缩的通讯集群建设经验,包含⼀对⼀通话、呼叫中⼼及⾳视频大会、⽇志监控等场景,涉及FreeSWITCH、Kamailio、WebRTC、MCU、SFU、Docker、K8S、ETCD、NATS、Loki等相关技术。
主要会介绍我们用到的一些技术,希望能对你们有所帮助。前面提及的一些技术似乎也不算是新技术,通讯技术已经历几六年发展,早在二三六年前你们就早已在研究高可用相关技术。不过由于新时代的发展,近来你们开始关注云原生等相关技术,相应基础设施形成一些变化,通讯与互联网的联系也越来越紧密,由此形成了更多新的玩法。
01单点故障

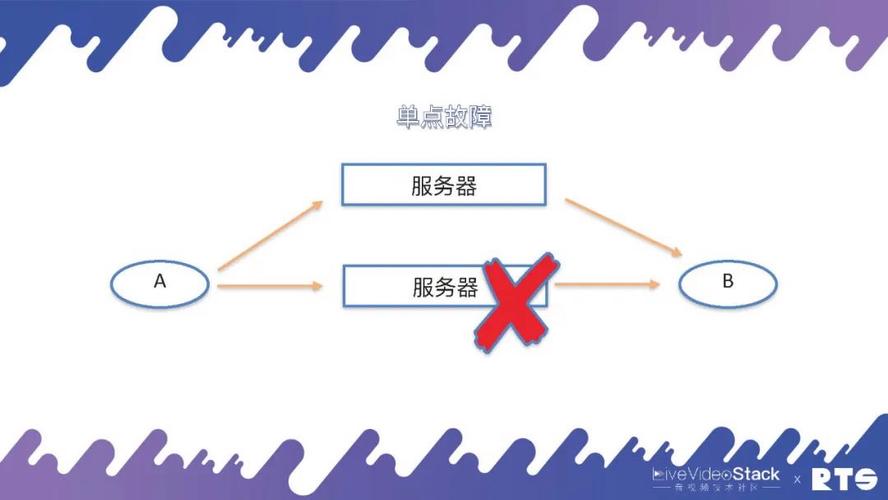
虽然,一切的起源都是来自“单点故障”这个问题,我们就由此展开来进行介绍。
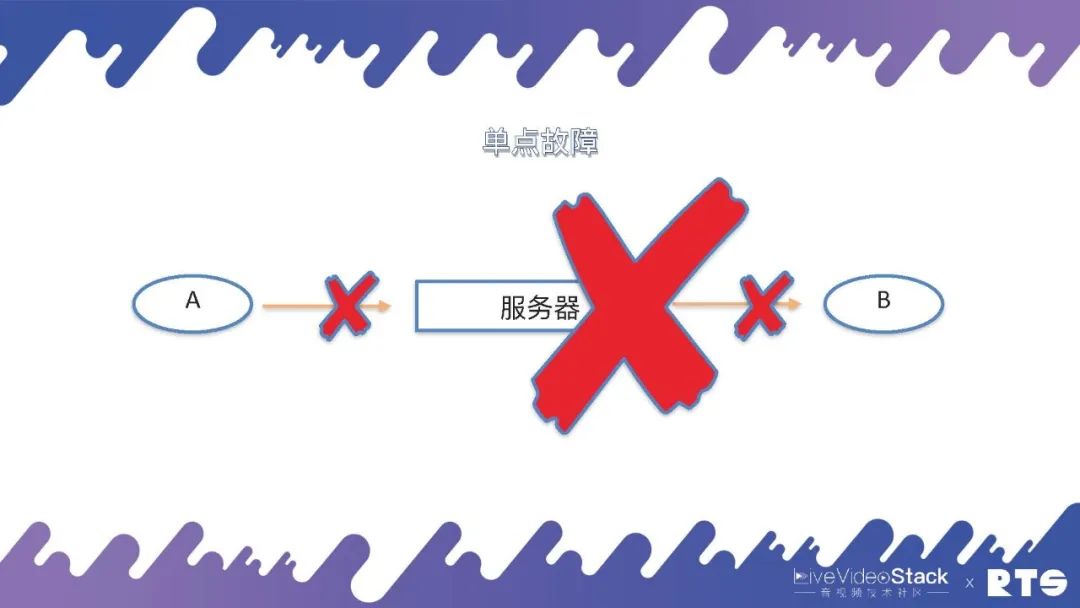
A和B两个通讯的实体,两个电话(人)通过一台服务器进行通讯,其实这个服务器可以是FreeSWITCH,也可以是任何其它服务器。假定这台服务器因为通讯链路中断或则是网路联接中断,A和B则未能完成通讯,这就是单点故障的起源。
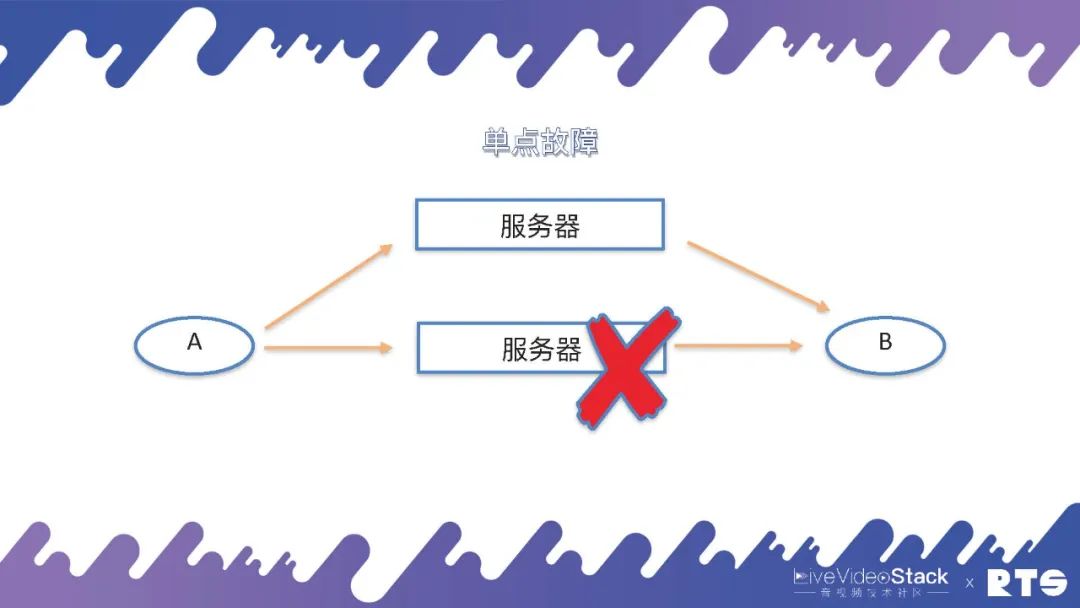
那要想解决这个单点故障,就须要另外的服务器通过迂回路由或是其它办法来克服单点故障的问题。
02双机HA

通常来说,克服这个单点故障的方式就是双机HA(HighAvailability),即主备高可用。
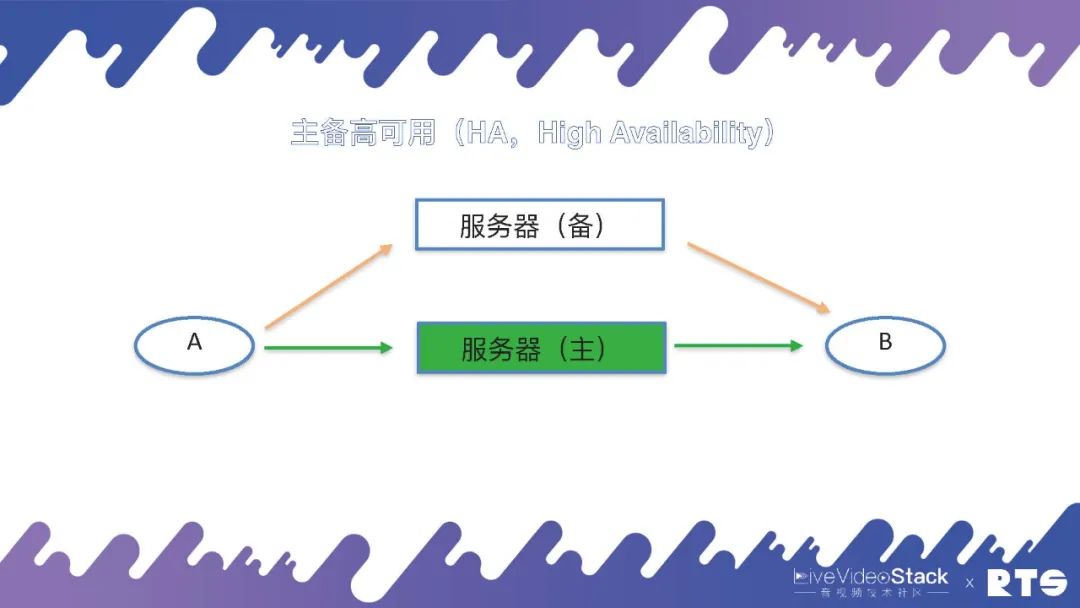
双机HA的主要原理是:有一台主机和一台备机,如果主机出现问题断连,备机可以接替成为主机继续进行工作,这么不断进行主备交换。主机与备机为同一IP地址,对于A和B来说可能感知的到或则根本感知不到主备机所进行的切换,由于通信时A和B听到的仅仅只是IP地址,当任何一台服务器切换到主机时,它就占有了对外服务的IP地址,这个IP地址我们就称作虚拟的IP,也叫业务IP或浮动IP。本身每台服务器底层还有一个IP,但对外提供服务的IP(即A和B见到的IP)虽然是虚拟IP。
这样当服务器发生切换的时侯,A和B依然是和原先的IP进行通话,她们可能会觉得到网路的短暂卡顿,之后恢复正常,而感知不到服务器是否有进行切换,这就是主备高可用的原理。
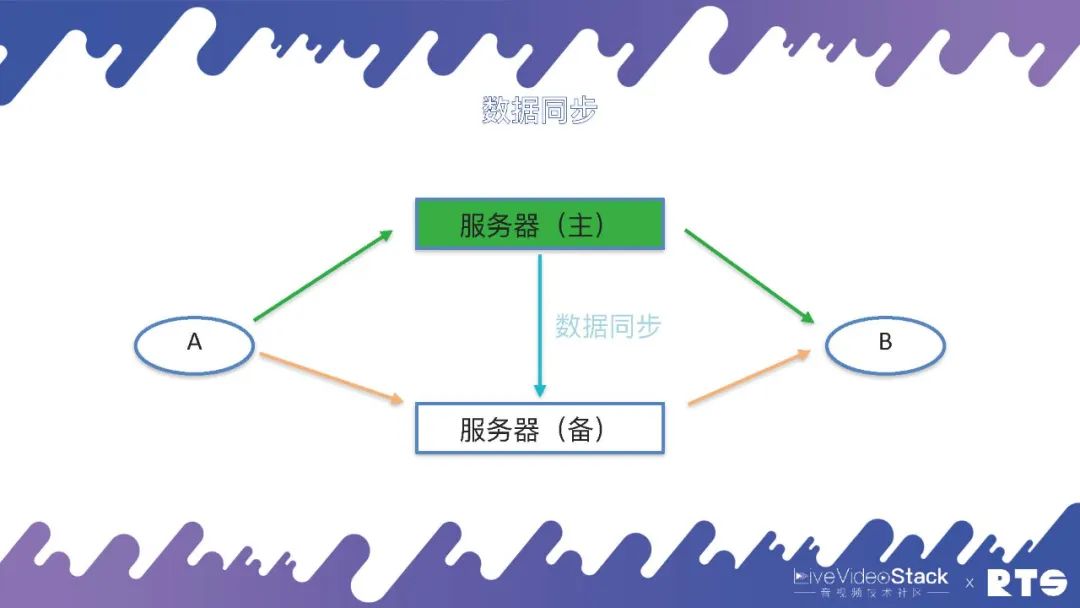
为了实现主备高可用,因为主服务器和备服务器之间有一些数据须要同步,所以就须要一种数据同步机制。
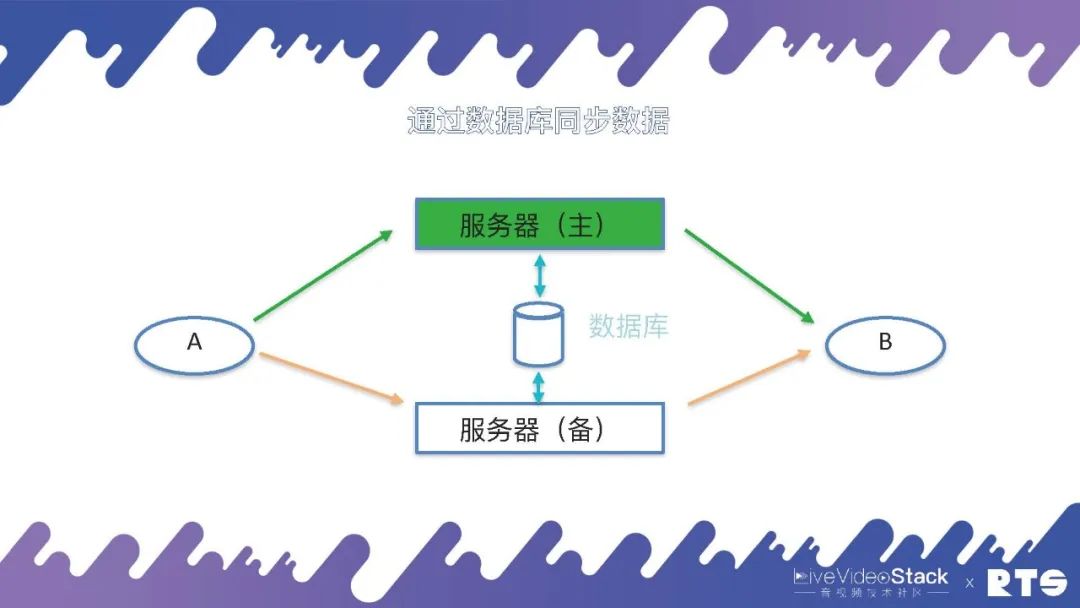
其实这个数据同步的机制有好多种,比如通过日志、消息队列等等,在FreeSWITCH中主要是通过数据库来同步这种数据。主服务器会实时将A和B(A和B可能有成千上万个)通话的数据写入到数据库当中,备机可以在数据库当中查询数据,一旦发生主备切换,备机从数据库当中取得数据,重新构建通话场景,A和B就可以继续进行通话。
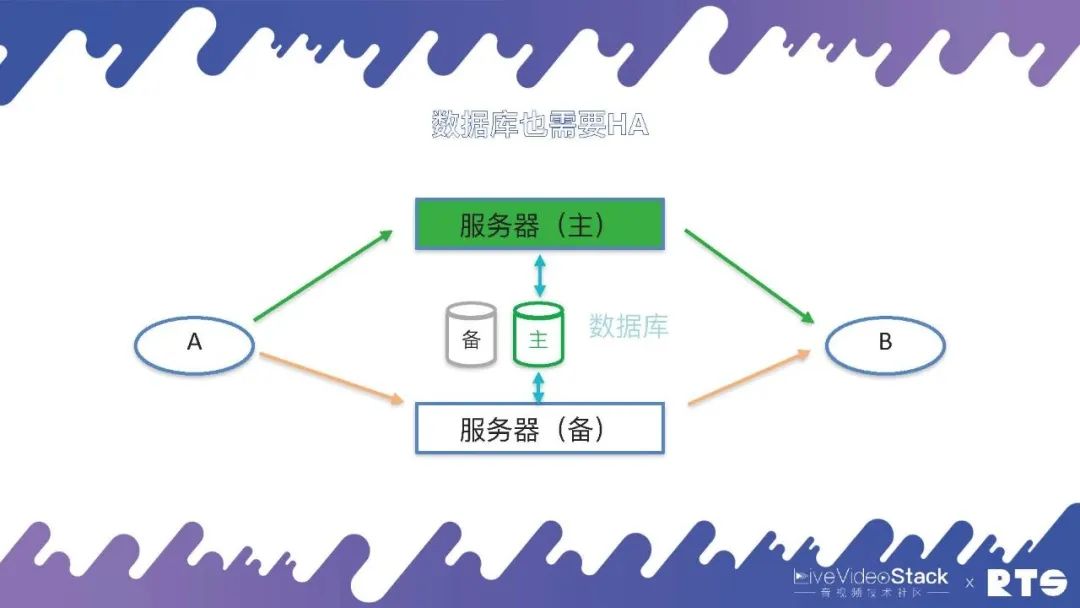
在这些情况下,数据库也就成为了一个单点,为了解决这个问题,数据库同样须要主备高可用。
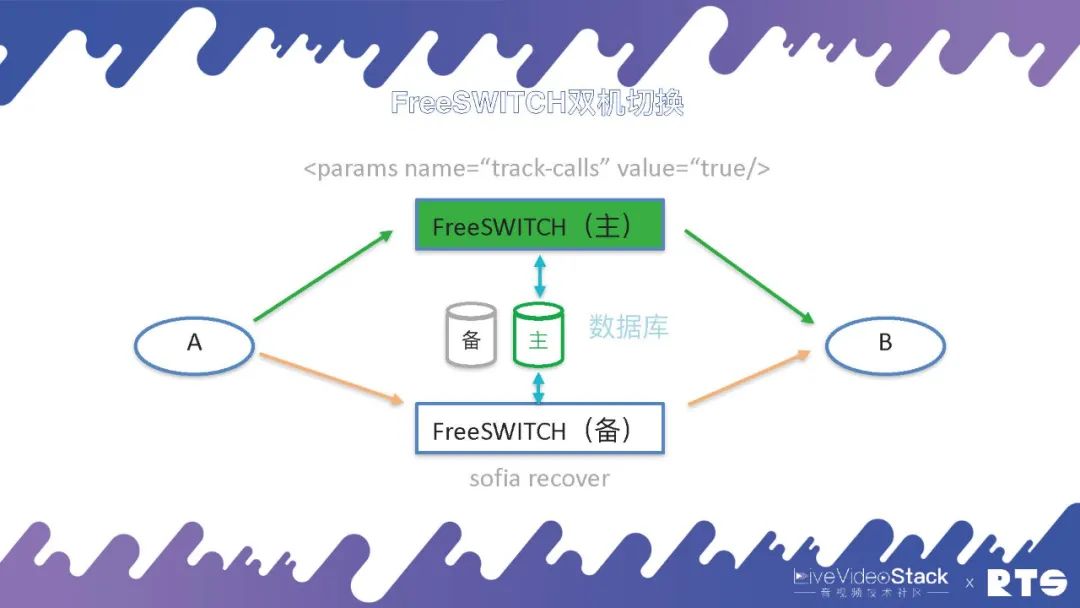
FreeSWITCH的主备切换原理:首先主机包含一个Param,参数为:
,假如我们开启此参数,它都会实时的将通话数据写入数据库当中。其实这个会有一定的开支,由于须要实时的写入数据库,例如每秒有一千路通话、一万路通话,它的开支都会很大,所以这些双机切换会对系统的吞吐量有一定影响。但在一些必要的场景下,我们常常是须要牺牲一些性能来更好的实现高可用的。
当备机发生切换的时侯,备机会执行一个sofiarecover命令,从数据库中取得数据重建通话的场景,向A和B发送reINVITE。上面我们说A和B感知不到,虽然也能感知到,由于A和B收到了重新建连的约请,继续进行通话。通常这个通话过程大约在1-3秒内解决,A和B只是认为会短暂的卡顿,不用挂断重新呼叫。
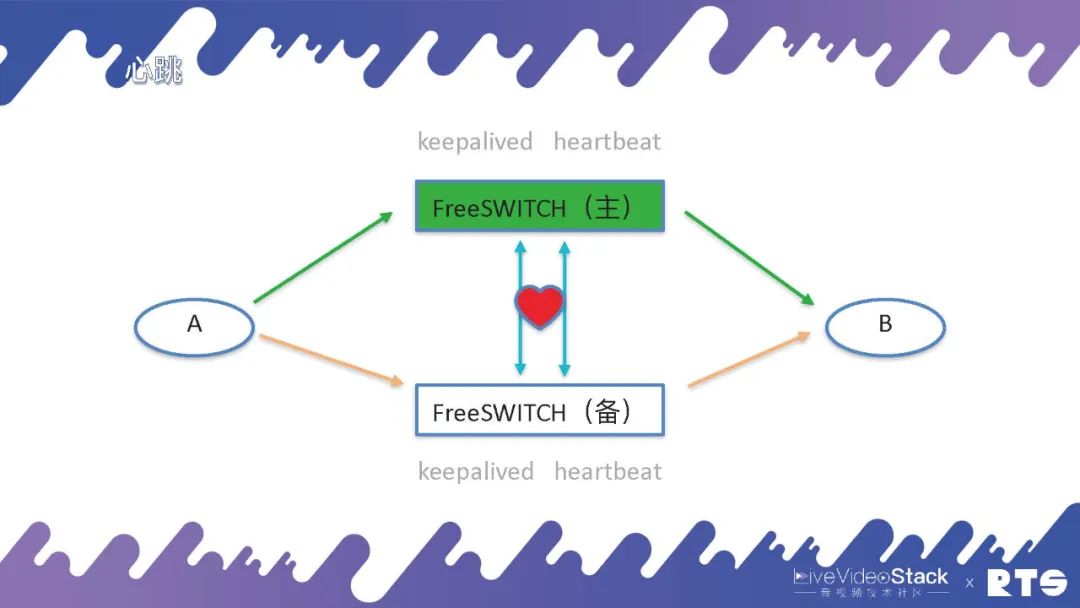
我们先排除数据库的影响(默认数据库是主备高可用的),来看FreeSWITCH的主备高可用。
为了能确切感知进行主服务器和备服务器之间的切换,须要有一个东西叫脉搏(脉搏线),通常脉搏线在之前都是用并口线,由于脉搏只是简单的传几个字节的信息,对带宽的要求不大。但如今在一些虚拟机中,不包含数学的并口,就只能用网线来实现。通过一个网线,不停的有脉搏,备机可以以此感知主机的状态,一旦形成主机崩溃、断连,备机会接管IP。
其实这个情况下也可能会形成错判,考虑到脉搏线本身的断掉影响,我们可以通过两根脉搏线或双网卡的方式防止出现这些错判的情况。其实,我们须要更多的机制来保护系统,防止出现两个服务器同时绑定同一个IP,同时写入服务器造成服务器错乱的情况形成。
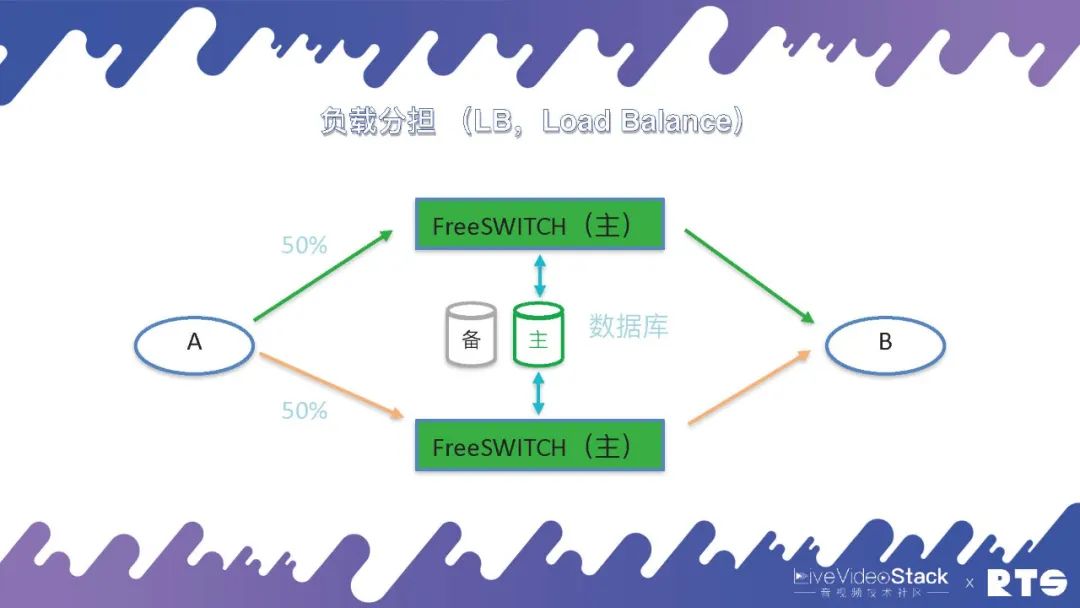
其实,这些情况下会有一些问题,两台机器作为一台机器使用,可能会导致资源的浪费。还有一套方法是负载分担(LoadBalance),A和B之间有50%的话务分别放置于两台主机,两台主机可以同时达到满负荷承载。但这些情况同样存在一定问题,假定先前每台可以承受一千路通话,两台配合总共可以承受两千路通话,当其中一台主机出现问题,另一台在满负载的情况下,实际上系统的吞吐量只能达到一千,还会发生串扰发生问题。
所以说通常主备负载分担的情况下,我们会保证两台FreeSWITCH主机每台的话务量不要超过其设计容量的50%,这样是比较安全的。其实,这样算上去我们实际上还是有50%的浪费,我们也可以采取通讯降级的策略,当一台主机出现故障时,仅使用另外一台主机,按照实际业务需求,保证部份通话联接的正常使用。
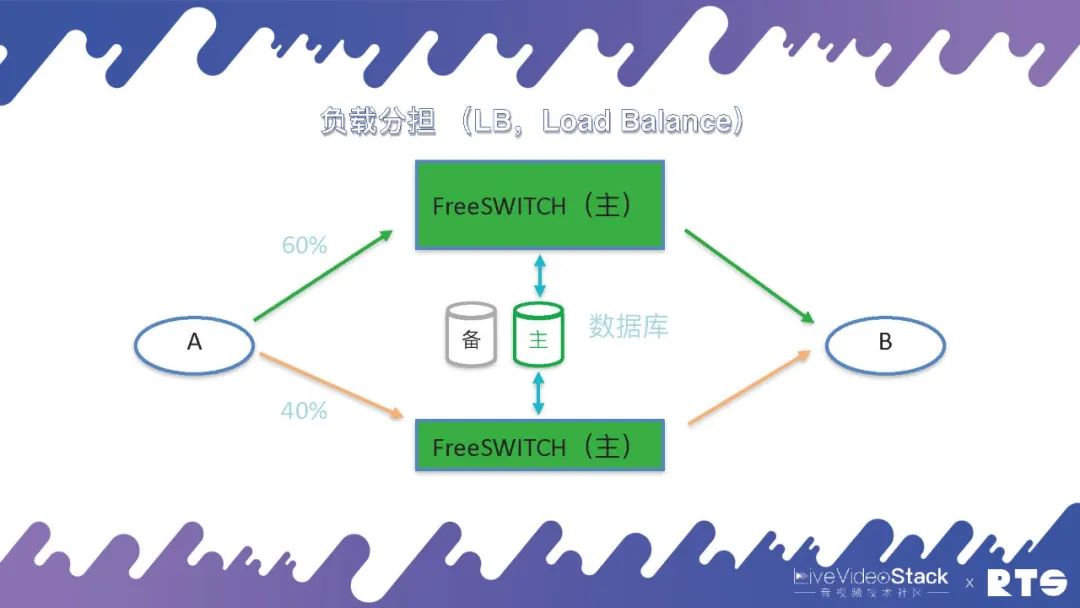
不过负载分担对于A和B会有一定的要求,上面我们说到主备的方法,A和B都只能看见一台服务器(实际上是两台服务器),是一个IP地址。并且在负载分担的情况下,A和B都能看见两台机器,这就须要一定的逻辑(在A和B上做),须要才能分发例如将50%的话务量分到一台主机,剩余50%分到另外一台主机。并且有时侯两台主机的性能不一样,可能一个是64核,另一个是32核,须要依照主机性能对话务量进行分配,例如一个60%,一个40%。这样才会对A的要求比较高,须要才能感知主机来进行负载的分发。
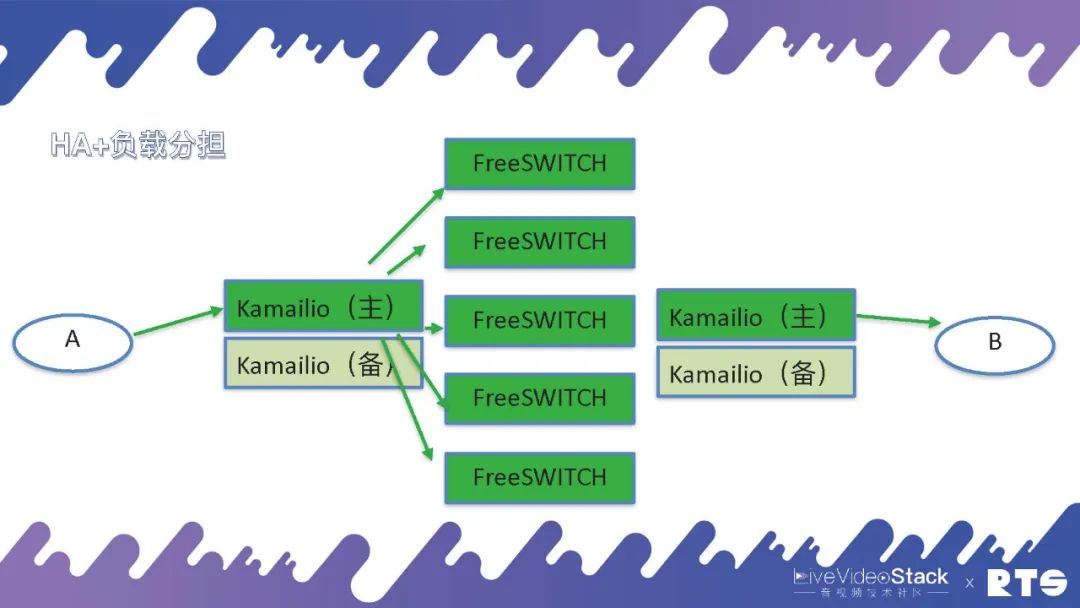
在实际的布署当中,我们通常都是采用这样的结构(如图所示)。FreeSWITCH作为媒体服务器,上面再放上代理服务器,通常是用Kamailio或则openSIPS做代理。Kamailio只代理SIP就是指处理通讯的构建和分发,一台Kamailio前端可以放好多的FreeSWITCH。由于FreeSWITCH要过媒体,要进行录音、质检、分析等等媒体的处理,所以FreeSWITCH的处理能力就不如Kamailio强。这样上面放一个Kamailio,前端可以放好多FreeSWITCH进行通讯。
其实Kamailio须要主备高可用,而Kamailio和FreeSWITCH之间是用LoadBalance,这样用HA+负载分担的形式就完成了一种比较大的通讯集群。并且因为A和B两边的业务逻辑有可能会不一样,例如说左侧是中继,右侧是文员是本次的系统电话,这时我们可以放两个不同的Kamailio,管理上去会更便捷一些。其实我们也可以使用一个Kamailio,将A和B置于左侧,但这样的话脚本和逻辑的判定上都会比较复杂。由于必需要判定通话是由A还是B过来的,还是从FreeSWITCH过来的,须要判定呼叫的方向,逻辑会相对比较复杂。
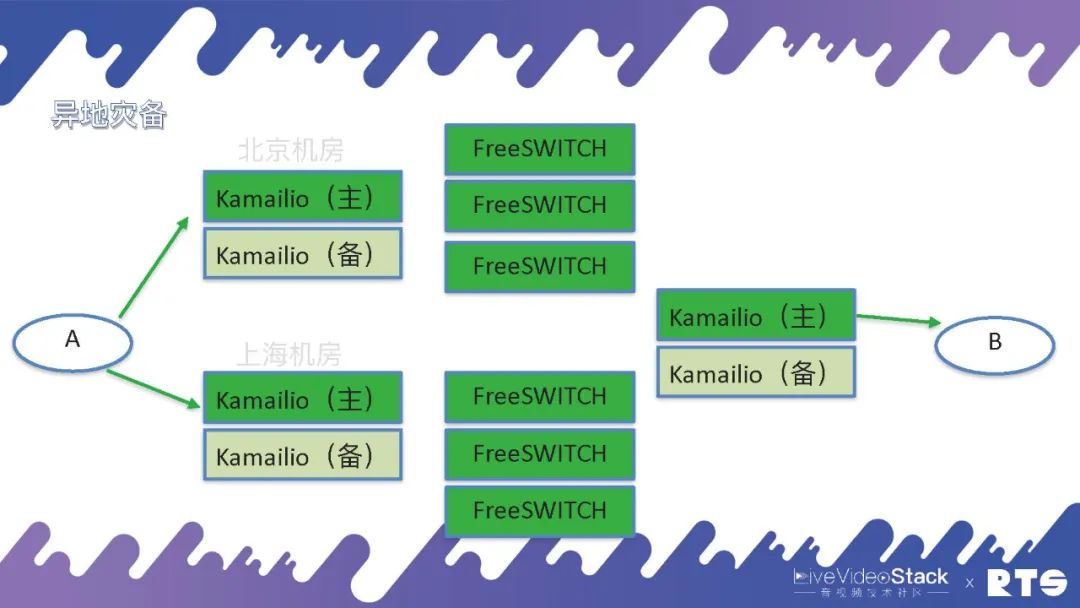
还有一种情况就是异地灾备,哪些是异地灾备?举个事例,我们可能有两个机房分别在成都和重庆,都用FreeSWITCH和主备高可用,这样平时主要通过上海的机房,一旦出现问题可以通过迂回路由经由北京的机房进行通讯。
然而异地灾备同样须要一些数据的同步,这就又对A提出了一定要求,由于A面对的是上海和南京两个机房。所以说高可用是无穷无尽的,只要有需求只要改构架就须要相应的考虑,但万变不离其宗,当然就是HA和负载均衡这两种逻辑。其实具体地来说,A上可能靠DNS寻址,也可以将上海或南京的地址直接写进设备当中,自己执行策略按照情况来进行切换等等。
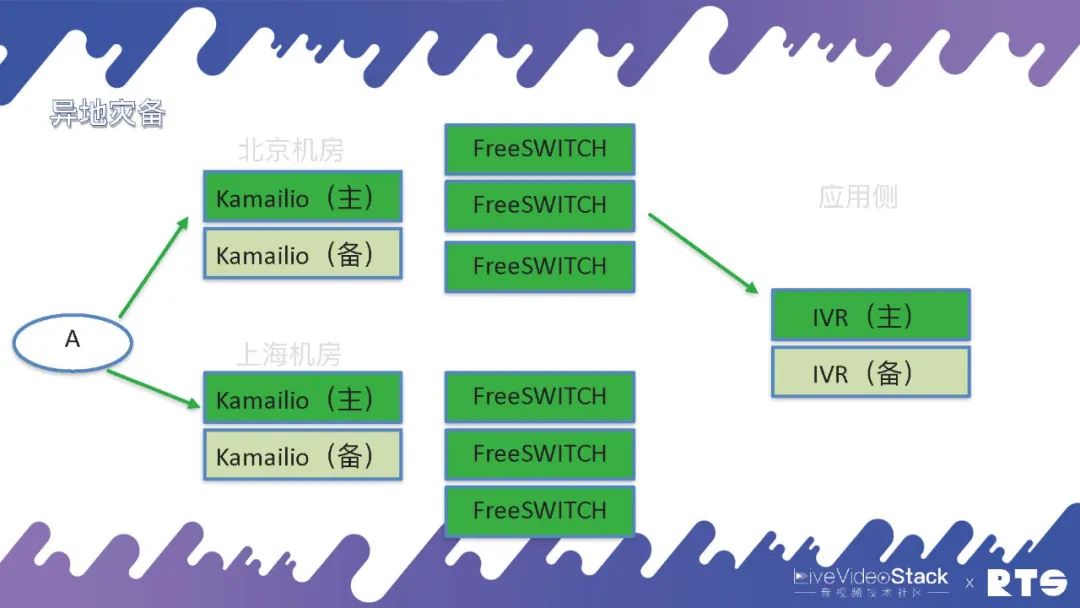
这么,我们来看B这两侧。A和B进行通话,有可能会呼叫进来以后执行IVR有些应用,这种应用同样须要主备高可用。例如有人打电话进来docker 高可用,Kamailio是负责鉴权的,FreeSWITCH负责媒体,然而具体的逻辑是由应拿来负责的,须要由它来告诉FreeSWITCH应当哪些时侯处理媒体、什么时侯录音、放音等等,所以应用侧同样须要主备高可用。
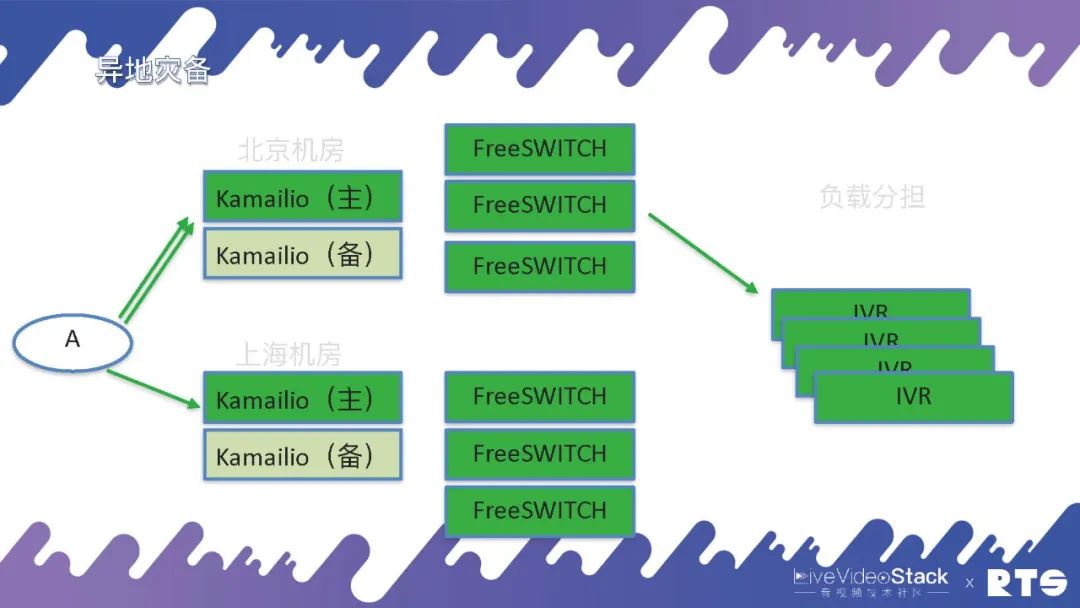
其实,通常的这些IVR我们觉得它大体都是无状态的,接入通话挂断以后再接入一个新的通话同样还是这个IVR,所以通常还会用负载分担的方法,可以承当多个IVR的业务。
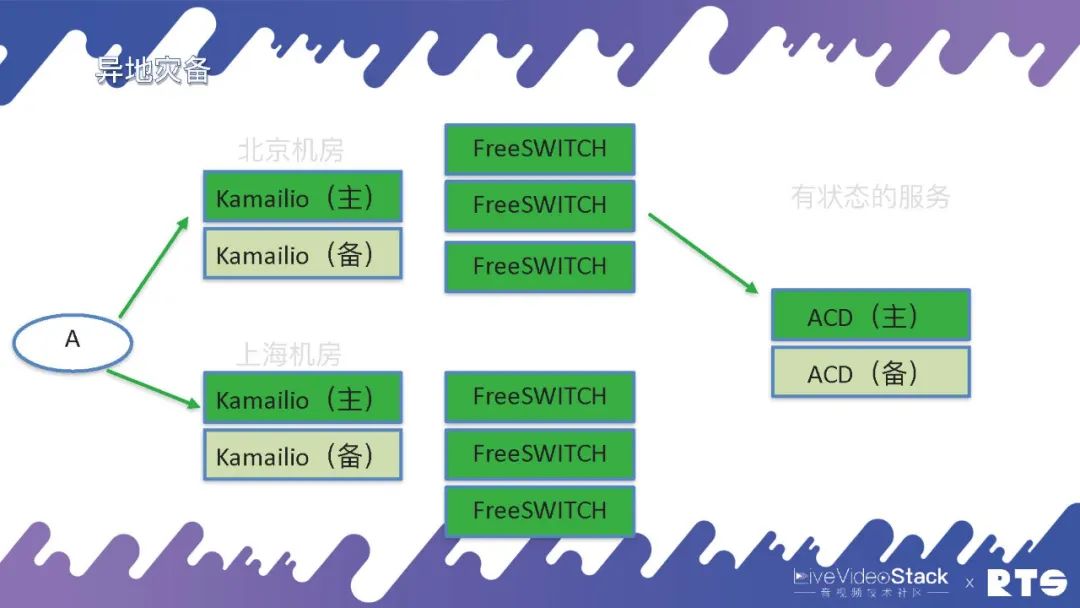
并且有一些服务它是有状态的,例如说呼叫中心当中常用的ACD。ACD须要check座席的状态,以及队列的状态,有多少顾客在等待、有多少座席在服务、哪个座席正在跟顾客沟通、哪个座席正处于空闲,它须要跟踪这种状态。通常来说对于这些有状态的服务,还是要采用主备高可用的形式。其实,双机HA同样可能会出现两台机器同时发生问题的情况,这时侯我们就扩展到——三机。
03Raft

三台机器的场景更为麻烦,由此我们引入了一个合同称作Raft,还有一个称作PaxOS,不过现今比较常用的还是Raft合同。

Raft似乎是一个共识合同,它的主要作用是做Log。首先它是用一个分布式的系统,分布式系统主要是解决容错的问题。这么如何解决呢?就是同步日志。例如一台机器上的日志,我要将这种日志副本同步到其它的服务器起来,其实我们说到的日志可能也是数据,数据库数据或则通话的数据或则是状态的数据等等。通常来说Raft都是质数的,由于其秉持少数服从多数的原则,通过投票来进行补选。
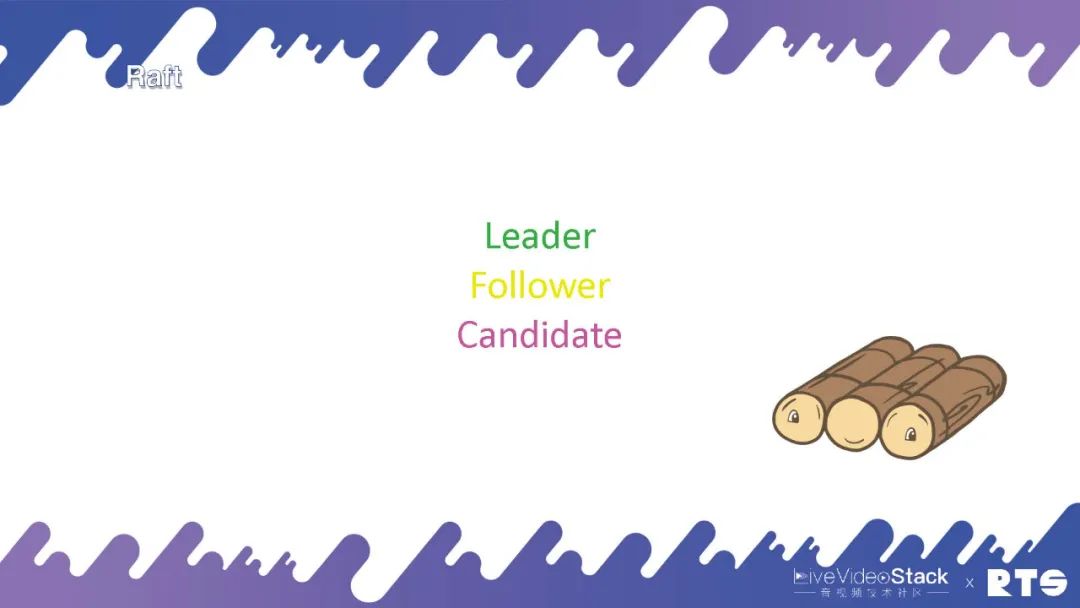
Raft中包含三个节点,Leader(领导)是一个主服务器,所有人会补选选出一个Leader来,由Leader来决定哪些时侯更改数据。之后它会把那些数据同步给Follower(跟随者),所有的数据会从Leader上进行更改,然后会同步到Follower上。正常的情况下,集群内有Leader和Follower,数据就可以在服务器间进行同步。但又一种情况是作为Leader的主服务器死掉了,其它所有的服务器都会变为Candidate(候选者),有机会被补选成为新的Leader,通过这个机制可以保证有一台服务器是可以保存这种数据的。
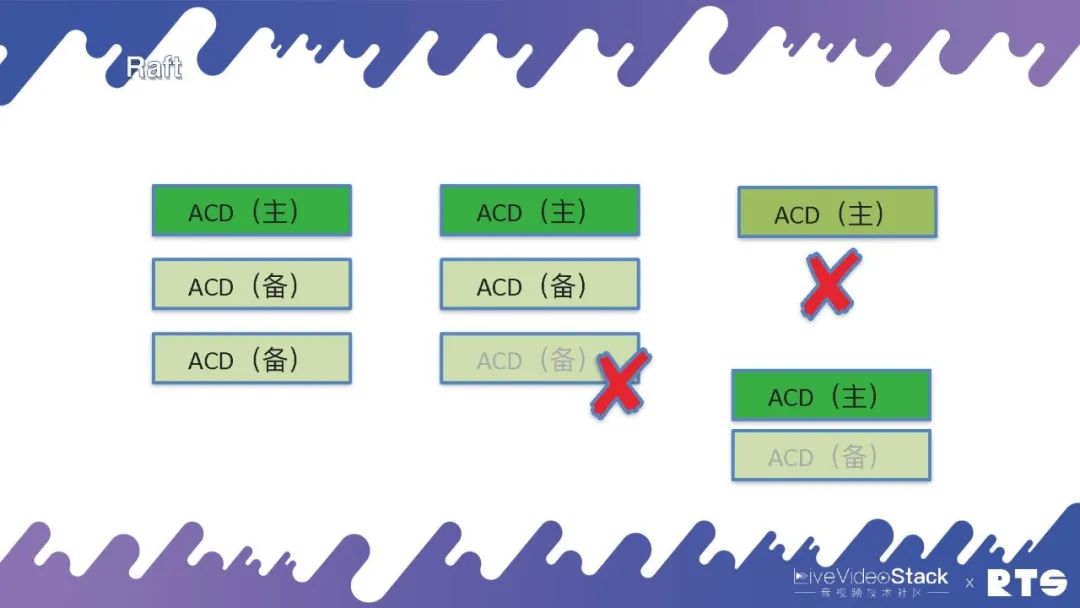
并且它似乎能保存数据却不能对外提供服务,Raft集群规定其中有一台主机负责写数据,另外两台负责备份,只有集群当中有多数的主节点和备节点活着的时侯,譬如说3个死了1个,则还可以继续对外提供服务。而且假如是死了两个docker 高可用,就不能继续对外提供服务了。
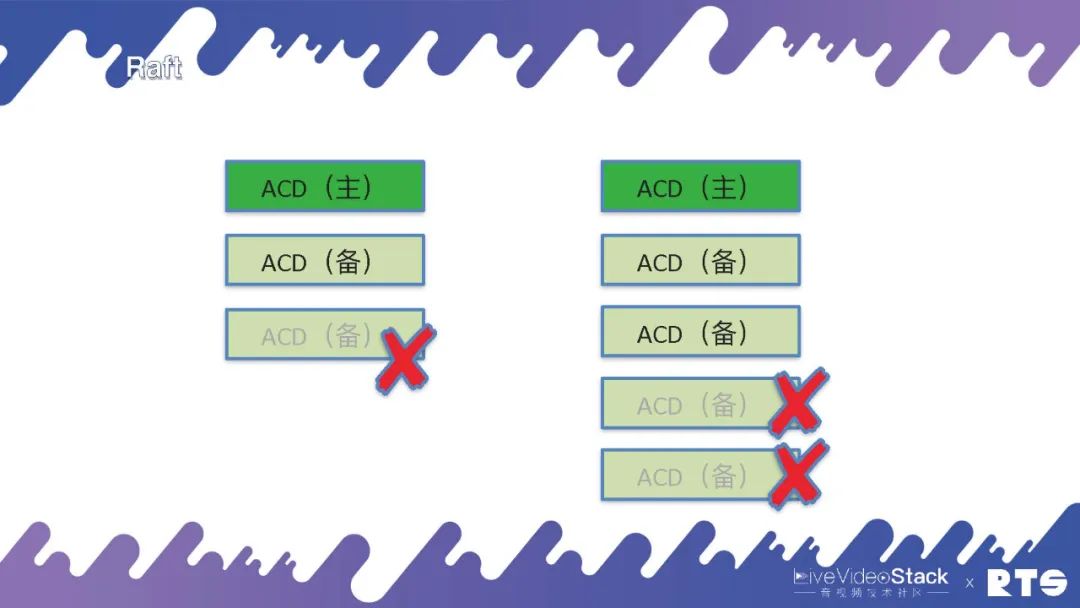
这么,这是为何?如图最右边我们来看,假定原先的主服务器与其它服务器断掉链接,此时它还是能正常进行服务。而另外的两台服务器会按照当前情况判定,重新改选出一台作为主服务器。此时,整个集群当中就会同时出现两台主服务器形成冲突。所以一定要遵守少数服从多数的原则,只有当整个集群中有多数的节点活着的时侯才会对外提供服务。
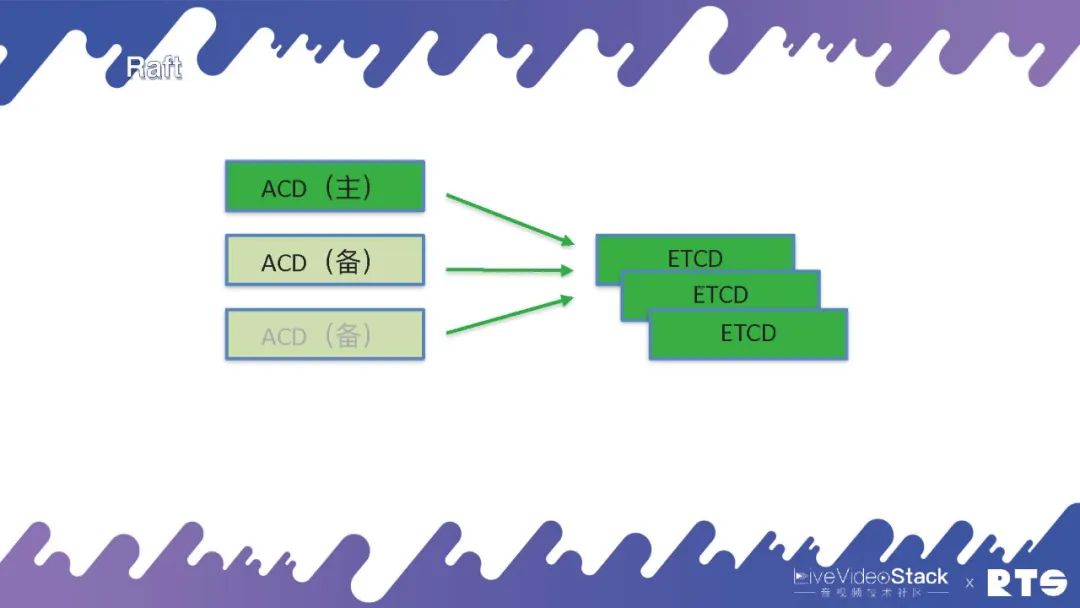
其实,假如我们说要把所有的ACD上面都要实现一个Raft是很难的。目前有一个应用称作ETCD,我们可以直接将服务联接到ETCD上,它会告诉我们谁是主谁是备。并且这样又带来了一个问题,原本三台机器就可以,我们还须要另外再装三台ETCD,这样会带来更大的开支和浪费,多用了一倍的资源。
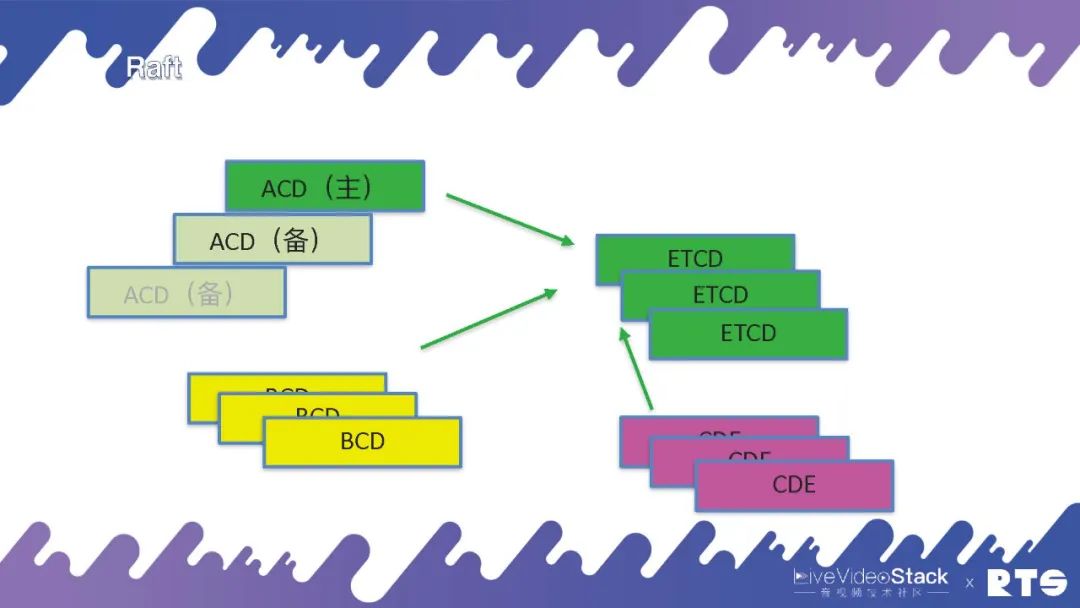
然而当我们的集群比较大的时侯,例如不仅ACD外我们还有其它服务如BCD、CDE等等。假如各类微服务的数量比较多,可以公用一个ETCD的话,相比较而言开支也就没这么大了。

简单的总结一下:
双机可以提⾼可靠性,但投⼊资源和获得回报不成正⽐;为了节约服务器,把不同的服务放在相同的化学服务器或虚拟机上,可能适得其反;集群可以提⾼可靠性,但只有集群⾜够⼤,资源能够有效利⽤;双机须要的服务器数目是质数的,⾄少2台;分布式系统(集群)须要的服务器数目是质数的,⾄少3台。
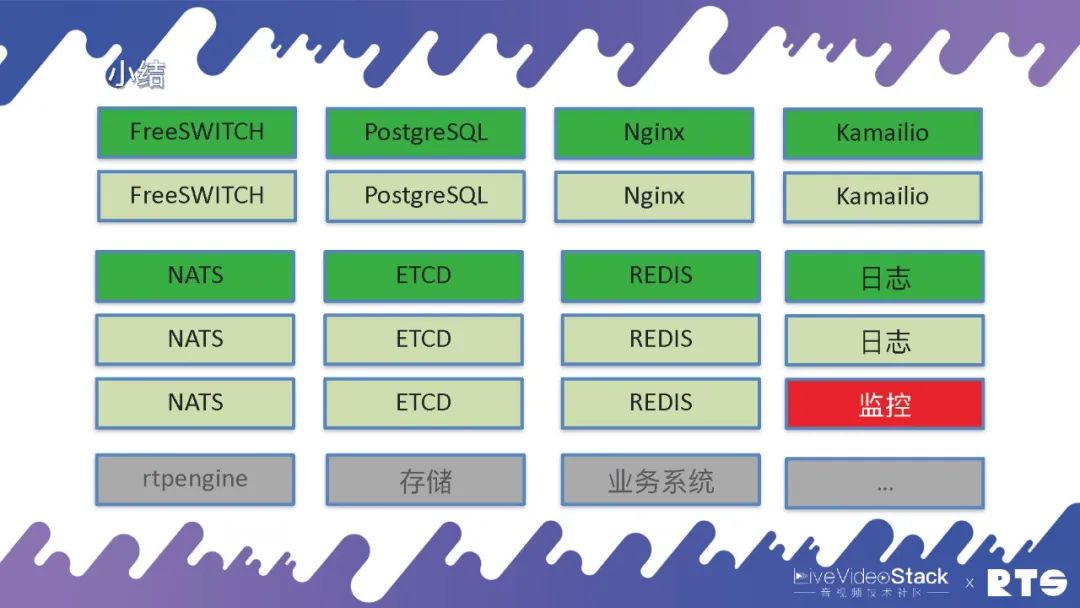
通常的来说,有一台FreeSWITCH服务器就够了,若果想双机设备的话就须要两台服务器,假如须要数据库的话就是四台。有可能就会放Nginx代理HTTP,还有可能会放Kamailio来代理SIP。其实我们主要使用NATS,这是一个消息队列。之后使用Etcd来做选主,有可能使用Redis来做缓存,还有可能做日志、监控等各类服务器。还有可能rtpengine、存储、业务系统……
其实linux驱动下载,要是想构建一个可靠的系统起码须要十几台服务器,它对外所能提供的服务能力也超不过一台服务器的服务。所以假如集群规模比较小,那就没有哪些意义,投入天文数字但实际上整体的利润很小。假如想要集群规模做的足够大,类似云服务,这么投入多少台服务器虽然都无所谓了,由于开支是相对比较小了。其实,这种最终还是须要依照业务本身来做权衡。
04XSwitch实践

接出来介绍一些XSwitch的具体实践。
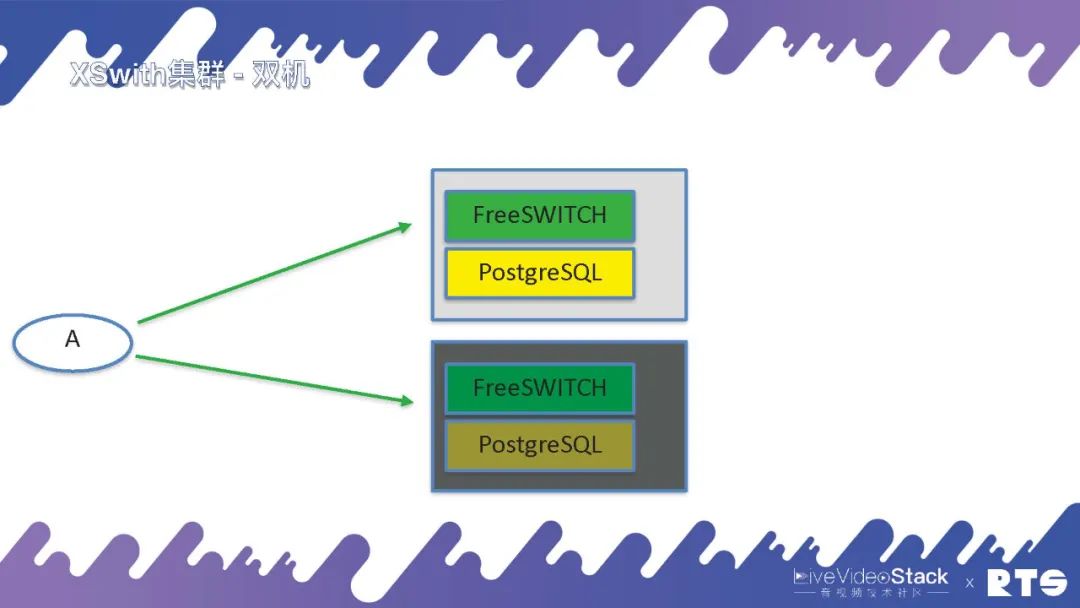
XSwitch即XSwitch集群,通常来说最小的配置就是双机,主备高可用,FreeSWITCH和PostgreSQL置于一块。
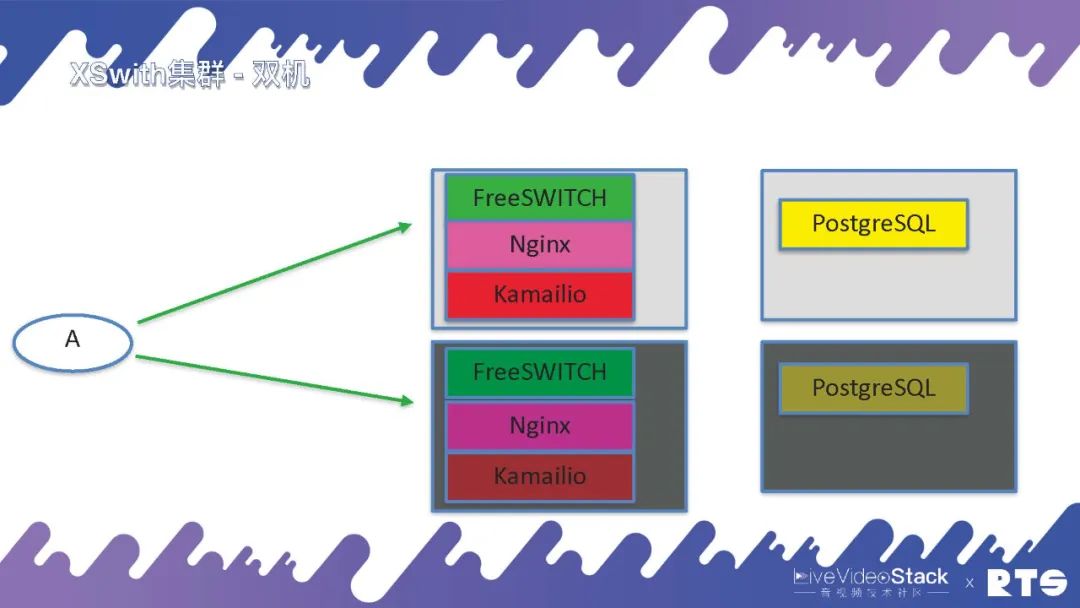
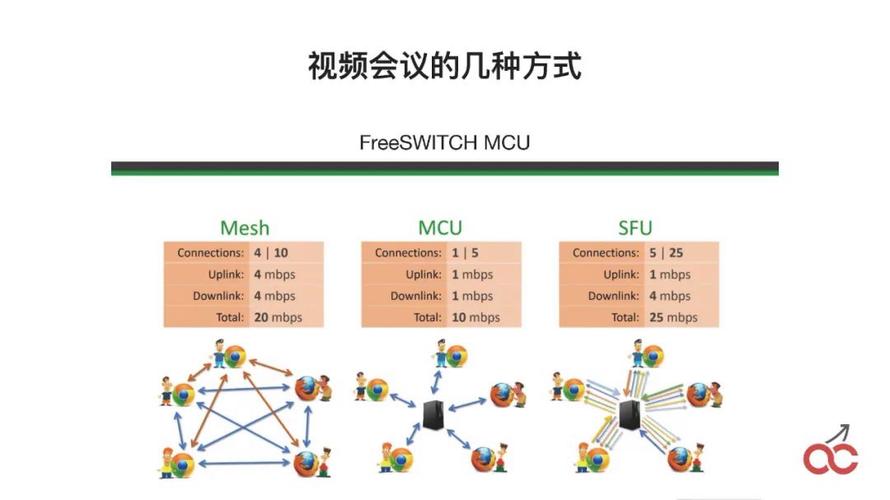
对于有一定预算的顾客,我们就建议她们将数据库独立下来,置于独立的服务器上,总共4台服务器。Nginx通常我们可以跟FreeSWITCH置于一起,之后有可能我们会放Kamailio。
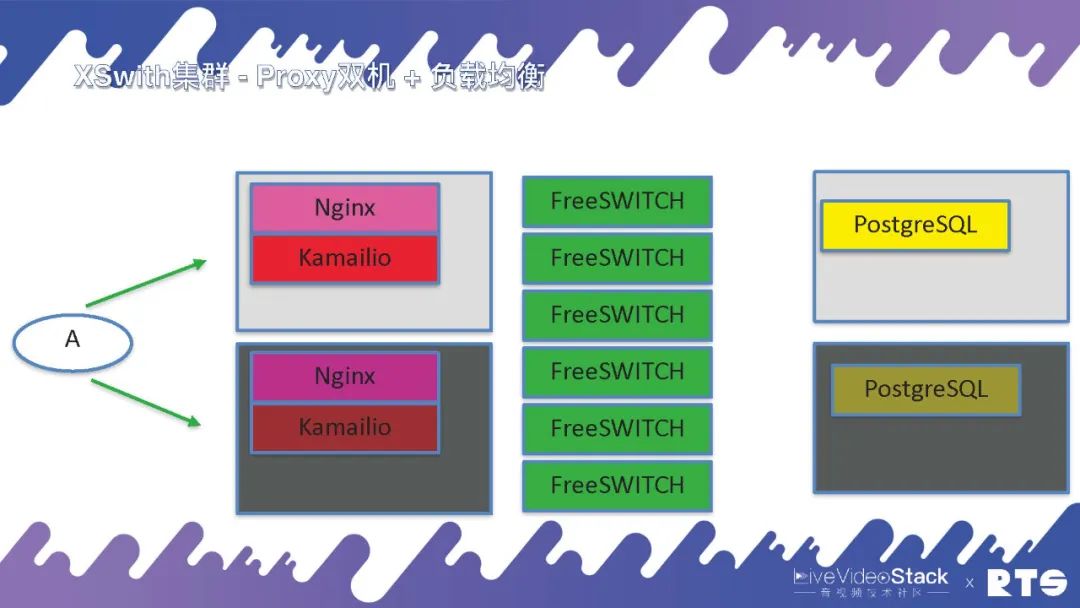
假如预算充足也可以将它们都独立下来,这样后边就可以放更多的FreeSWITCH。
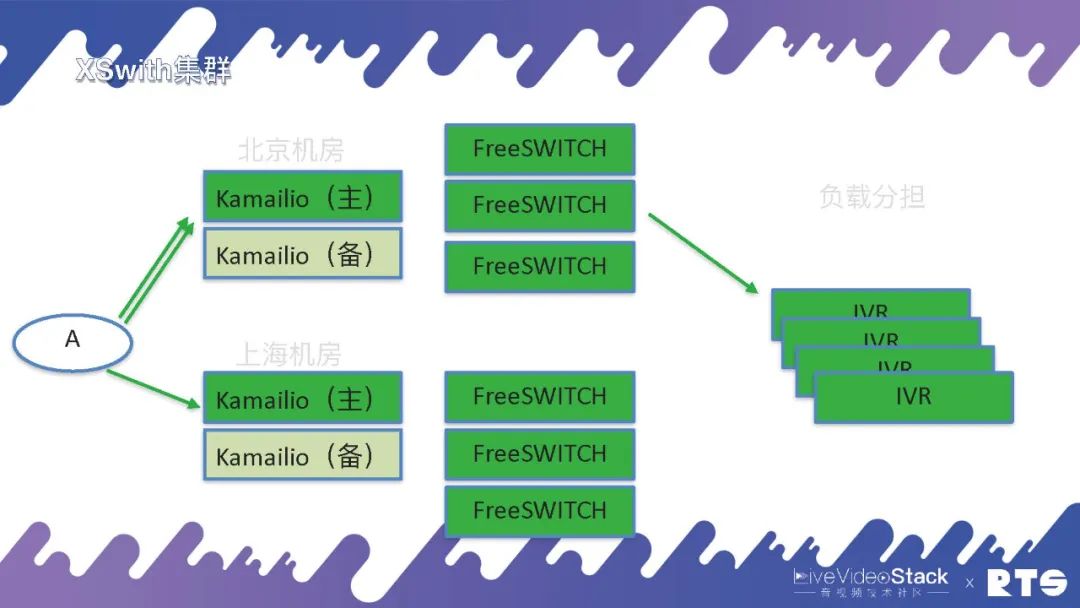
再就是异地的,负载分担。
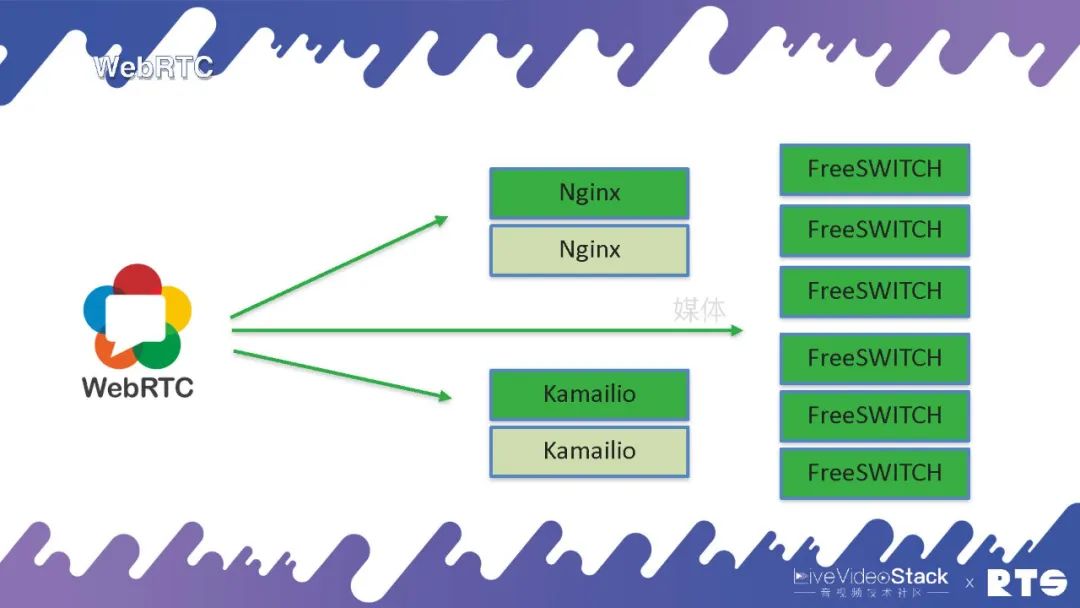
由于WebRTC只有媒体,所以就是直接到FreeSWITCH,鉴权可以通过Nginx或则Kamailio实现,由于鉴权都是基于WebSocket来做的,这是WebRTC的高可用。其实,媒体上面我们谈到有个rtpengine也可以做代理,可以把后台的FreeSWITCH隐藏上去,这就是更复杂的一些应用了。
XSwitch怎样实现多住户呢?虽然我们有很多种形式,一种就是PertenantperFreeSWITCH,每位住户给它一台FreeSWITCH,每位FreeSWITCH一个Docker,使用同一个数据库,我们用的是PostgreSQL,上面可以天然的分Schema,每位Schema都是彼此隔离的,这样的话可以给每位住户分一个Schema。
也就是每位住户一个域名,每位住户一个Docker,每位住户一个Schema,数据库是同一个。上面放一个sbc,用Kamailio来做鉴权的代理,其实sbc如今我们是单机布署的,之后也可以做HA。
具体的代码或许我们就写了一个映射表,由于我们如今集群规模比较小,还没有放数据库,通过域名就可以直接查到对应的IP地址,来进行分发。我们使用的是Kamailio+Lua。
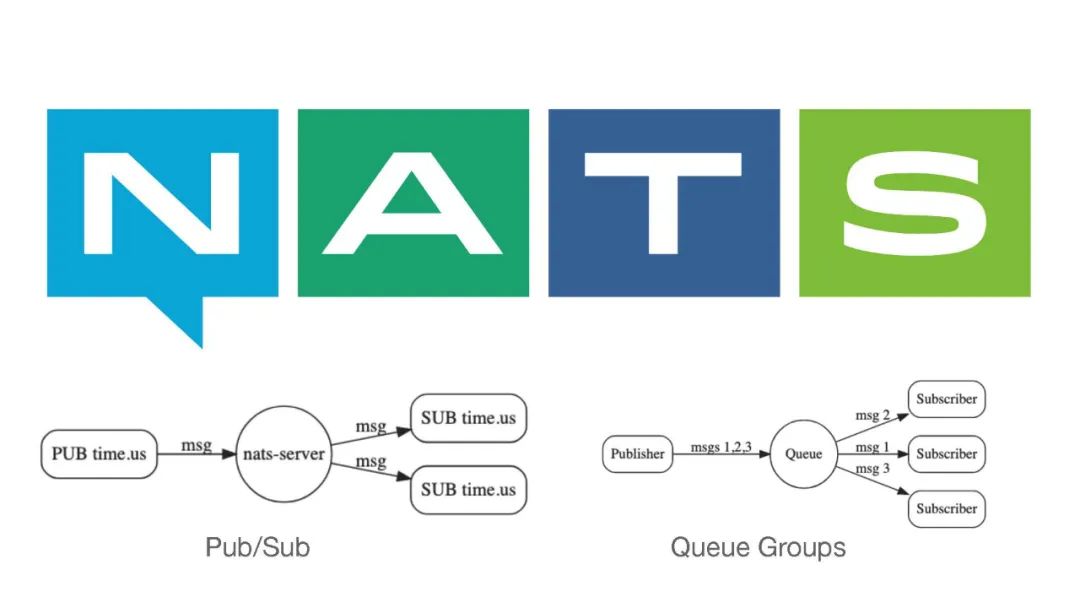
在应用侧我们就使用了NATS。NATS是一个消息队列,所以它具有消息队列的一些基本特点,例如说Pub/Sub来进行推送,还有一个就是QueueGroups,可以通过一个队列进行订阅,这些情况下就可以做负载分担。生产者生成了一条消息,消费者可以负载分担的消费这种消息。
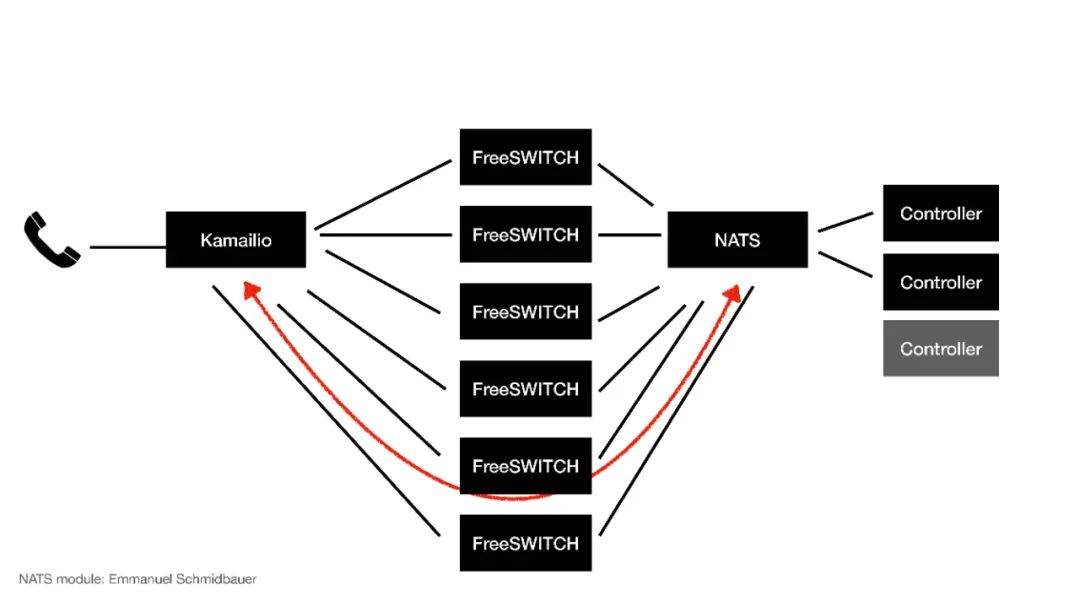
这么我们就用它来做集群的应用:来了一个电话到Kamailio进行分发,分发到不同的FreeSWITCH,通过NATS分配给不同的Controller,这个Controller就是应用侧,应用侧会控制通话的逻辑。
当来了一个电话到了FreeSWITCH之后,NATS会分给某一个Controller,这个时侯Controller就跟某一台FreeSWITCH构建了一个虚拟的对应关系,在这个电话的生存期间它就可以控制这路电话的通话行为和呼叫流程。

其实,这个Controller也可以额外降低,FreeSWITCH也可以。NATS也联接到了Kamailio,Kamailio也可以感知到NATS,这时侯假如我们扩充、弹性伸缩,FreeSWITCH不够用我们又加了几台,这个时侯FreeSWITCH都会给NATS发一个消息,NATS会把这个消息发给Kamailio,Kamailio就感知到我如今有了6台FreeSWITCH,它都会重新估算它的路由表,我们用的是dispatcher模块,重载dispatcher模块的数据,之后它还会把新的通话分发给新的FreeSWITCH,这样就完成了一个扩容,这也就是弹性伸缩。
弹性伸缩的“伸”还是比较容易的,只须要往上加机器就行。“缩”才是比较困难的,有时侯须要等所有的话务量都去除以后才会进行。

其实,“缩”还有一个就是可能你们都觉得的,例如其中一台机器死掉了,我重启一下。虽然重启以后它就不是原先那台机器了,我们那边用的都是FreeSWITCH的UUID,重启以后UUID会发生改变。其实IP地址有可能变有可能不变,但我们觉得它是变了,由于是一台新的机器了。
所以说在这个集群上面,虽然是重启了之后,它也不是原先那台机器了。我们在哲学里曾学过:“⼈不能两次踏⼊同⼀条支流”就是这个意思。假如想要做集群,那就要把它弄成是无状态的最好,这样就能大规模的分发和复用。

所以说使用的机制主要是Docker和K8S。其实,将FreeSWITCH置于K8S上面并不容易,首先我们先放在Docker上面,先完成容器化,之后再放在K8S上面。由于K8S它是一个网路,优点就是不晓得它在哪台化学机上运行,想启动就启动,想关掉就关掉。并且FreeSWITCH、SIP,尤其是RTP,它们有一大堆的端口,才会比较麻烦。

这么,我们是如何做的呢?我们使⽤Kamailio做Ingress,负责鉴权进来。Kamailio还是双机,之后它分发给前端的FreeSWITCH,FreeSWITCH不够用了就执行ScaleUp,相反就ScaleDown。
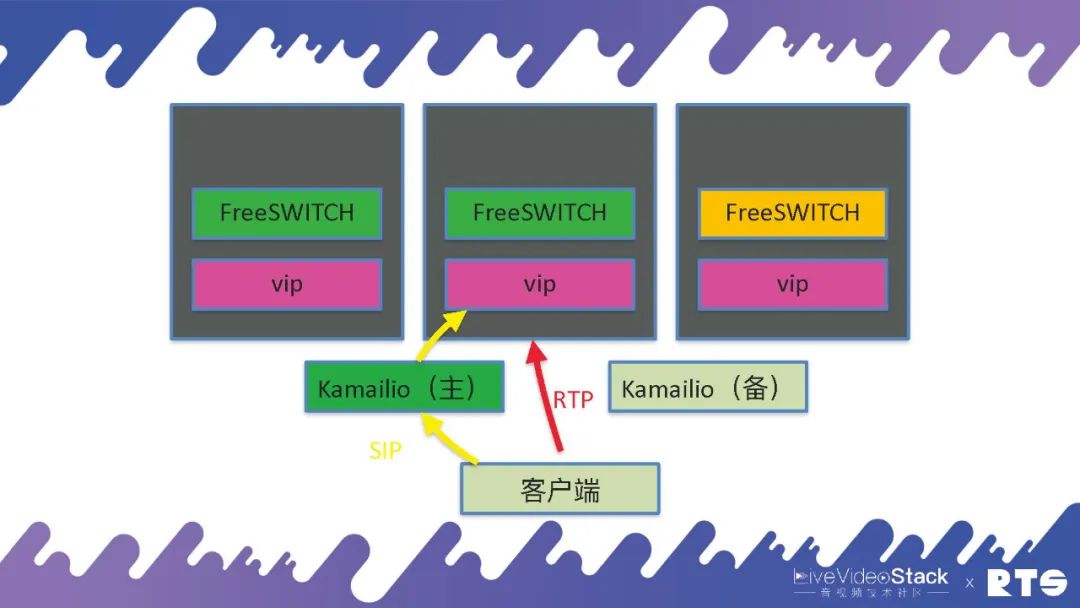
然而具体的我们使用了一个东西称作VIP,这个VIP是我们自己写的一个合同,由于现今的K8S主要是针对HTTP来优化的,对SIP类的应用都会比较麻烦。所以我们就自己写了一个应用,在每台化学机或则虚拟机上,都有一个VIP的服务。当FreeSWITCH启动的时侯,同样每台机器上也只启动一个FreeSWITCH,它告诉VIP打开一对端口,之后VIP就把这种端口通过iptables打开,就可以正常分发了。万一这台机器死了以后,端口就是空着不用也无所谓,由于FreeSWITCH也死了,不会有服务往这里面发了。当机器重启以后,端口依然还是使用这几个端口段,所以也没有问题。这些情况下RTP就是直接到FreeSWITCH,后端还是通过Kamailio进行分发SIP。

这些应用就是每位Node上只运⾏⼀个FreeSWITCH,每位Node上运⾏⼀个vip。其实,VIP这个东西称作DaemonSet,每台机器上只起一个VIP服务,这个服务也在集群当中。通过这些方法我们就可以动态的打开SIP和RTP的端口红旗linux桌面版,这样可以做弹性的伸缩。这是我们做的一些应用。

其实,假如一个Node64核、128核,能不能运行多个FreeSWITCH?可以的,虽然这样就须要按端口段来分开,可以弄成两个Pod,一个占10000-20000,另一个占30000-50000。这样的话通过这些方法,保证两个FreeSWITCH同时启动的时侯互不影响,同样管理也会愈加复杂。
下边是在Kamailio中使用NATS的一些基本代码:

05大会

下边还有一种就是大会。
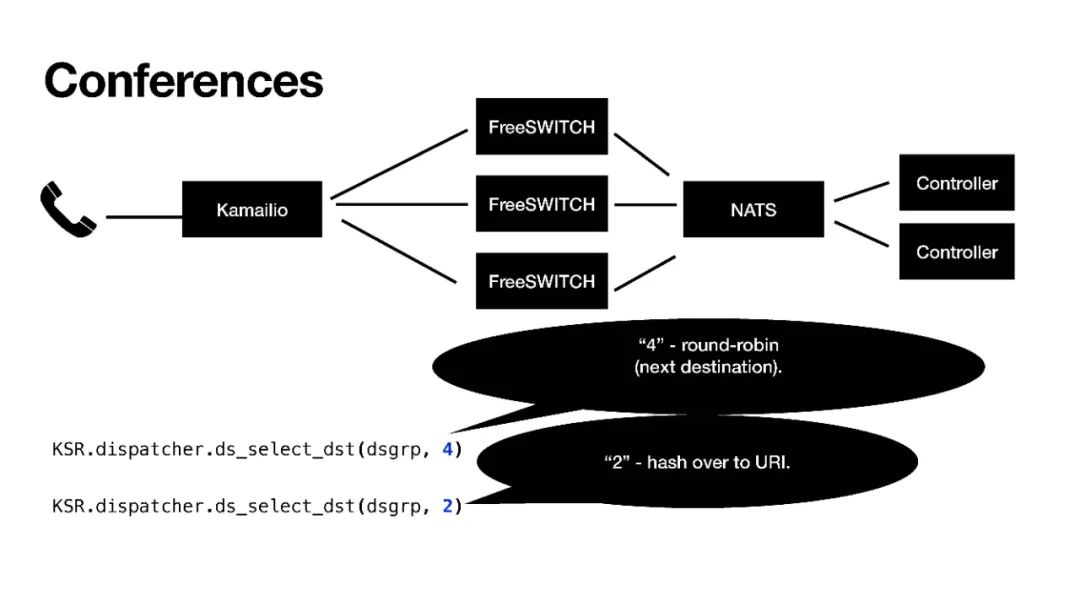
我们平时的负载分担分发是尽量平均的分发到不同的FreeSWITCH,这是最好的分发策略。并且大会不能,大会须要把外呼同一个大会号的,都分发到同一台FreeSWITCH上。这儿我们用了Kamailio中一个“2”的策略,“hashovertoURI”。

其实,实际使用的时侯大会规模比较大,一台FreeSWITCH不能满足,我们须要放在多台FreeSWITCH上,这个时侯我们就用了“7”这个策略,“hashoverthecontentofPVsstring”。我们可以自己创建一个字符串,只要是估算下来不同的终端,它在一个组内,通过分组,只要估算下来字符串是相同的,都会分配到同一台FreeSWITCH。
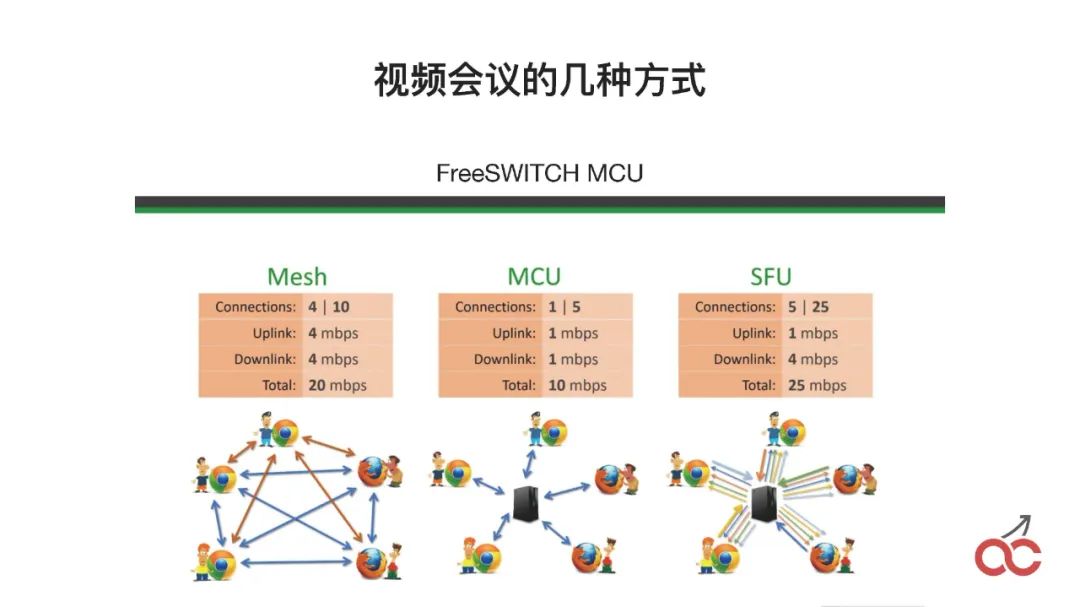
视频大会有如此几种方法:Mesh是无状态的,MCU就是所有的东西都通过中间融屏,SFU是通过它进行分发,不融屏。
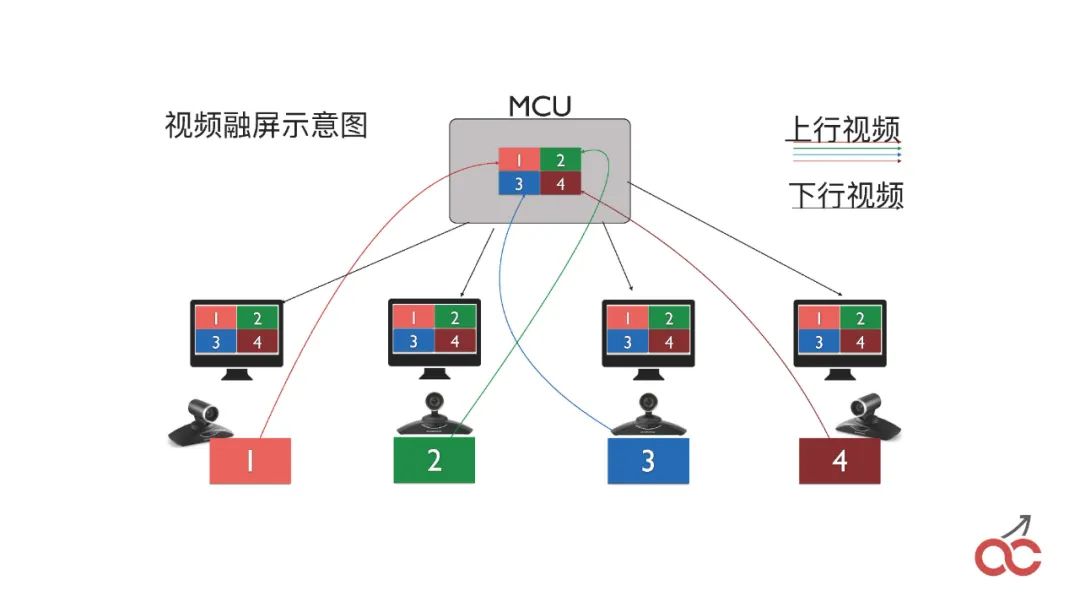
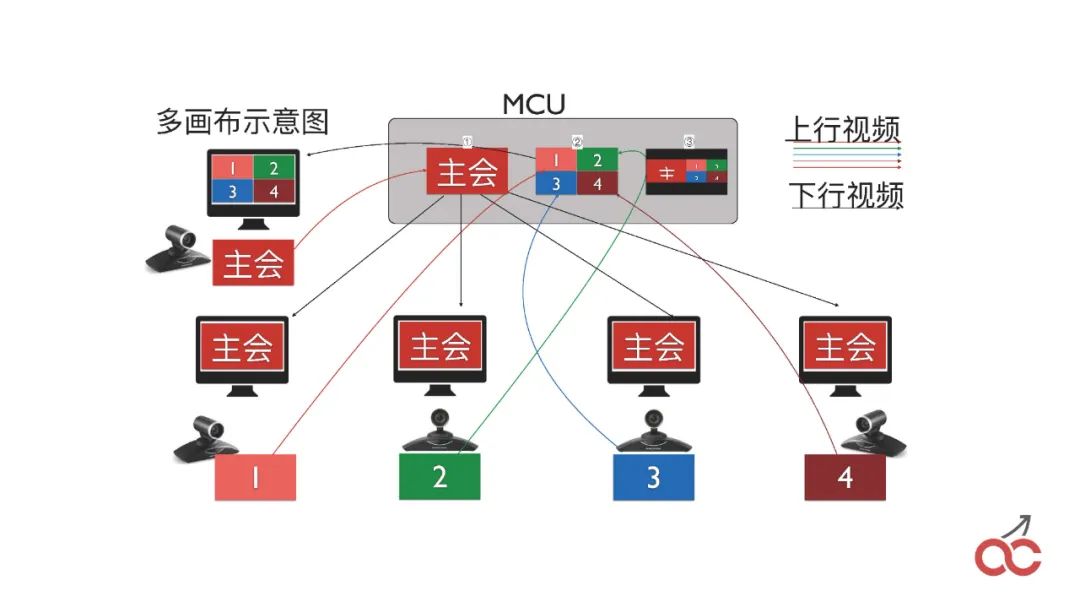
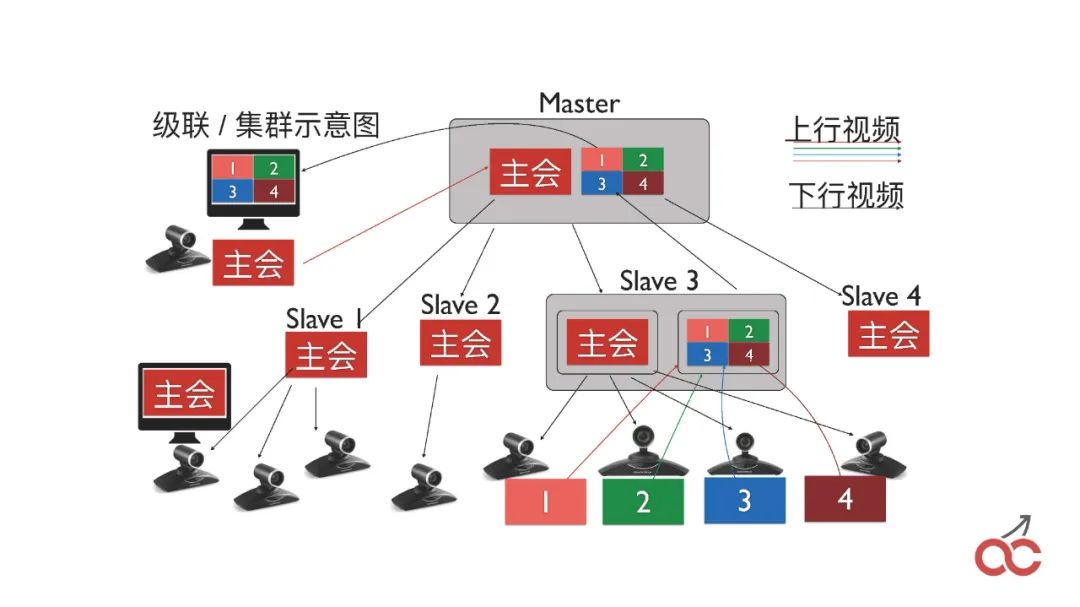
我们也会做大会的级联,通过多个FreeSWITCH级联来实现较大规模的大会。
级联也会出现一个问题,称作“看对眼”,就是出限类似无限循环的疗效,如上图中的样子。
这么,我们是如何做的?我们在大会当中,首先我们说如何将两个FreeSWITCH的大会串上去。
很简单,就是在第一台FreeSWITCH上面conference3000(大会号),之后呼叫另外一台FreeSWITCH也呼3000,另外一台FreeSWITCH收到呼叫之后,直接conference3000加入大会,这个时侯就是把两个大会进行串上去。

串上去以后,我们就可以设置两个画布,第一个是“video_initial_canvas”,表示我把我的图象置于那个canvas上;第二个是“
video_initial_watching_canvas”,表示我看那个canvas。

通过这些方法,我们也完成了MCU和SFU的互通。我们如今打通了Agora、TRTC以及MediaSoup之类的应用。
06日志

最后一个我想说的就是日志。

日志很简单,都有一些现成的服务:
Homer是做SIP的日志的,它的实现原理就是FreeSWITCH或Kamailio插入一个Agent,会将收到的消息转发给它,将SIP的图画下来;Loki就是储存日志的,我们会把所有的日志都发给它;另外还有Zabix、Grafana、Promuthus。

这儿面关键的一点是,每晚成千上万路的通话并发,我们须要晓得哪一路通话跟哪一路是相关的。所以说要有一个uuid,FreeSWITCH上面每一路通话都有一个uuid,这个UUID要跟call-id关联上去。通过call-id就可以找到对应的uuid,通过uuid就可以找到另外一条腿的uuid。

里面是外呼,呼出的时侯使用的是这个参数
:outbound-use-uuid-as-callid。

假如FreeSWITCH对外发出一路呼叫,在SIP当中的Call-ID和内部的uuid是一致的,这样就可以找到它们的对应关系,日志和SIP的对应关系。
这样的话,A进来,通过A的Call-ID就可以找到uuid,通过B的uuid就可以找到对应的Call-ID。通过Other-Leg-Unique-ID,这个在风波上面会有,或则Channel-Call-UUID,都能找到到对方,找到A和B。
07总结

最后,简单的总结一下。通讯的集群我们要用到各类各样的开源软件,要有双机、三机,弹性伸缩,包括⼀对⼀通话、呼叫中⼼及⾳视频大会、⽇志监控等场景。最终还是万变不离其宗,不管使用的是任何软件,它们的基本原理是不变的。
