深度学习开发里及部署进程中,环境配置从来都是让人纠结的麻烦事儿。NVIDIA Docker一产生,就把这种状况彻底转变了,它把GPU运算跟容器化本领精妙融合一起,使得开发者可轻易搞定复杂AI应用环境的打包、分发而后运行,完全不用再担忧宿主机环境的杂乱以及依赖冲突问题了。
为什么需要NVIDIA Docker
在Docker容器内,传统方式没办法直接运用宿主机的GPU。这表明即便你的服务器配备了强大的NVIDIA显卡,在容器里运行的深度学习代码也不能够借助其开展计算。过去,我们不得不于宿主机上手动去安装CUDA驱动以及库,这造成了环境管理的极其复杂化。

NVIDIA Docker借助与Docker命令行相兼容的工具,聪明地化解了此问题,在容器启动之际,其把不可或缺的用户态驱动库以及设备文件映射至容器内部,如此一来,容器里的应用程序如同于宿主机上那般能够直接运用GPU展开计算,并且维持了容器自身的隔离性nvidia docker,呈现出轻量性。
NVIDIA Docker的工作原理是什么
一个名为nvidia-container-runtime的组件是其关键所在,它并非独立的容器运行时,而是对标准runc的一种封装,执行nvidia-docker run命令的时候,这个运行时会接到调用,它于容器启动的特定阶段参与进来,负责达成GPU相关设备以及库的注入任务。
此过程对于用户而言是绝对公开透明的丝毫没有秘密部分。你并不必需就着起初存有的CUDA应用镜像进行调整作出改变,但是只需得在启动相关对应指令一开始增添上面写由nvidia-docker字样编排而成的一系列字符,或者是在较为崭新的发行版本以及具有当下流行特性的版本之中把Docker按照NVIDIA运行规则进行设置给予适配,那么你所使用的容器就很有可能会成功获取到GPU访问的相应能力进而得以运用。从最基础的底层角度来说,它是借助了Docker的--device以及挂载这两项所具备的功能特性,达成了以一种更为有风度且具备自动化特点的方式来完成相应操作。
如何安装NVIDIA Docker工具包
在进行安装工作之前,务必要确保你的系统已将NVIDIA显卡驱动安装妥当,并且安装了一个处于稳定版本状态的Docker引擎。在此之后,添加NVIDIA的官方软件仓库这样的行径是被推荐采纳的做法,这般施行能够保证你获取到以最新作为特性的安全层更新以及各项功能。具体而言的安装命令能够在NVIDIA NGC网站或者其GitHub仓库里面寻觅到。
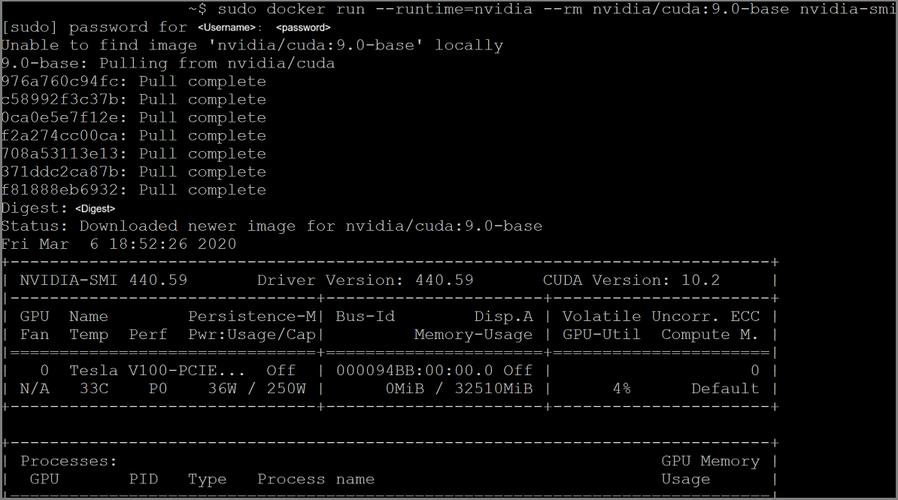
以基于Ubuntu的系统而言,流程一般是添加GPG密钥,添加软件源,接着借由apt安装nvidia-docker2包。安装完毕后,将需要重新启动Docker服务,从而让更改产生效果。通过运行一个基础的CUDA容器,像nvidia-docker run --rm nvidia/cuda:11.0-base nvidia-smi,能够验证安装是不是成功。
如何使用NVIDIA Docker运行容器
进行容器运行倘若应用NVIDIA Docker存在主要的两种方式,其一属于传统然而现今早已不再适用的办法,也就是径直运用nvidia-docker run命令行工具,其二充当现代状况之下得到引荐的形式,那即在实行标准的docker run命令期间,借由--runtime=nvidia这一参数来进行明确地指定从而运用NVIDIA容器运行时。
有较为持续的办法是去改动Docker的守护进程配置文件,也就是/etc/docker/daemon.json文件,把NVIDIA运行时放置设置成默认被当作运行时使用状态。接着这么做的话linux软件工程师,之后全部的docker run命令都会于不自知情况下拥有GPU支持。而处在Kubernetes环境里,能够借由进行定义Device Plugin或者运用NVIDIA GPU Operator去在集群层面开展GPU资源的管理工作 。
NVIDIA Docker在深度学习中的最佳实践
于构建深度学习训练环境所用镜像之际,建议采用NVIDIA官方供给的基础镜像,比如nvidia/cudanvidia docker,该些镜像已然安装了跟驱动相适配之CUDA工具包以及cuDNN库,能够确保拥有最大程度之稳定性以及性能,要规避于容器内部开展安装或者升级显卡驱动之操作,此操作应当由宿主机予以负责 。
提升数据读取效率时,大型数据集要以卷的方式挂载到容器内,而非打包进镜像。对于模型训练任务,必须通过nvidia -- smi命令或者环境变量去限制容器可使用的GPU卡以及显存,避免单个任务耗尽所有资源,进而影响其他容器或宿主机系统。
NVIDIA Docker与普通Docker有什么区别
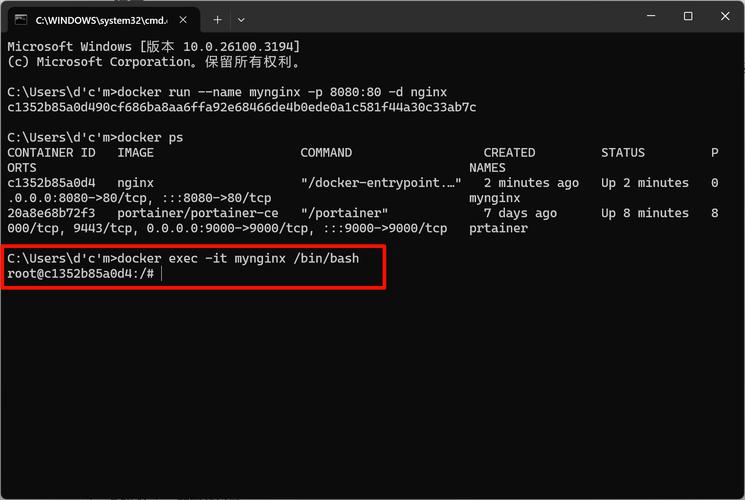
关键的本质不同乃在于GPU所具备的访问能力,平常的普通Docker容器在默认状况下没办法识别以及运用GPU,然而NVIDIA Docker借助额外的运行时层面赋予了容器这般的能力,于资源管理这一方面,NVIDIA Docker给出了更为精细的GPU控制,能够去指定容器借助哪几张GPU卡,甚至于对其显存使用量予以限制 。
基于命令而言,早期版本借助的是nvidia-docker,此为一包装命令,然而当下更倾向于借由配置Docker默认运行时达成无缝融合,这种转变使得docker run命令自身便可启动具备GPU支持的容器linux 下载,如此情形已然降低了用户用于学习方面的成本以及使用具备的复杂度。
当你使用NVIDIA Docker去处理多个AI项目之时,你是怎样去解决不同项目针对于CUDA版本依赖冲突这般问题的呢,欢迎于评论区去分享你的经验哟,如果自觉此文具备有帮助作用,也请为其点赞并分享给更多有着需要的朋友呀?
