Linux内核函数的调用之路,是通向操作系统核心深入之处的必经途径,它不仅仅是驱动程序开发得以开展的基石所在,并且就连性能优化以及系统研究这些方面来说,也是关键的技能要点,这个过程是直接与内核进行交互的,它要求开发者对于内核机制实实在在地拥有清晰的理解,而且要严格地去遵行其规则,不然的话,极有可能致使系统不稳定,甚至出现崩溃的情况,接下来,我会围绕着几个核心问题,去分享实际工作期间的经验以及需要予以警惕的陷阱。
为什么需要直接调用内核函数
通常而言,直接去调用内核函数,往往是旨在达成那些于用户空间无可为之或者效率颇为低下的操作。比如说,硬件设备驱动程序,其必然得借助内核函数来同硬件寄存器展开通信,进而实施内存映射以及中断处理。而用户空间的程序,是没办法直接对物理内存或者 CPU 特权指令予以操作的,这些操作通通都得经由内核所提供的接口方可进行。
另外有一个常见的场景,那是性能具有关键性质的应用,举例来说,像是高频进行交易的系统,或者实时开展数据处理的情况,需避开标准库的部分支出费用才行得通调用linux内核函数,借助系统调用或者更处于底层的内核接口去获取达到顶点的速度,除此之外,系统实施监控、安全方面开展审计等工具,也需要进一步进入内核去获取进程、网络连接等内部所具有的状态方面信息,而这些信息并不会全部向用户空间予以暴露 。
如何找到并理解所需的内核函数
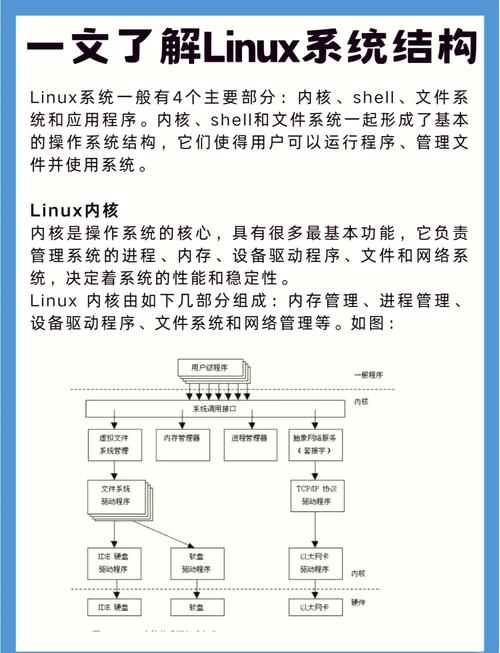
需要留意什么是linux,寻觅正确的内核函数,首要之事乃是熟知内核源码的排列布局以及主要头文件,内核API一般于include/linux/目录下,所含头文件之中予以声明,像linux/sched.h该文件,含有调度相关函数,运用grep工具,于源码树之内对关键词展开搜索,此为基本方法,与此同时,内核文档(位于Documentation/目录)以及在线资源,诸如Linux Cross Reference (lxr)网站(其为宝贵参考资料) 。

懂得函数调用linux内核函数,不光得晓得它的原型,更得清楚它的上下文以及使用约束才行。一定要认真去阅读内核源码里的注释,那些注释常常会讲函数的调用上下文(能不能睡眠)、锁的规定以及内存管理的职责。比如说,kmalloc是在内核空间去分配内存的,然而它返回的指针在进程上下文和中断上下文里的使用规则有所不同,要是错误使用了就会引发死锁或者内存错误。
调用内核函数需要哪些前置条件
首个重要前提在于,代码得运行在 内核上下文之中,这表明着,你正着手编写一个内核模块,或者对内核 源码自身进行修改,用户程序没办法直接调用像 kprintf 这类的函数,所以,你要准备好内核 开发环境,其中涵盖对应版本的内核头文件、编译工具链,并且掌握内核模块的编译以及加载方法,比如借助 Makefile 和 insmod 。
理解内核编程的独特规则,是另一个关键前置条件。内核编程不像用户空间C库有那样的保护,内存错误常常会直接致使oops或者死机。内核的内存管理、同步原语像自旋锁、信号量,还有禁止睡眠的原子上下文,你都得熟悉。在编写调用内核函数的代码之前,一定要保证已经掌握了这些基础概念。
常见的内核函数调用错误有哪些
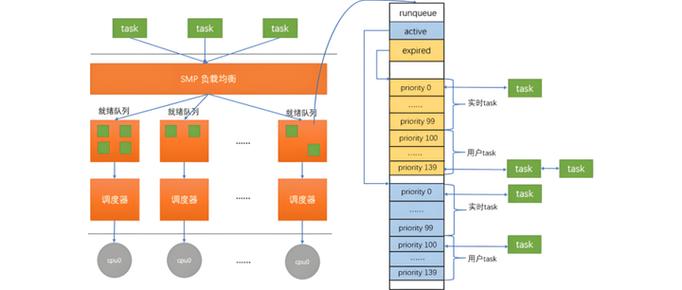
有着一个高频出现的错误redhat linux,情形乃是于错误的上下文里,去调用具备可能睡眠特性的函数。举例而言,在中断处理程序的情境下,或者在持有自旋锁之际,调用了那种极有可能引发调度的相关函数,像kmalloc(GFP_KERNEL)这样的,这会致使系统出现死锁的状况。而正确的做法是,于原子上下文当中,运用GFP_ATOMIC标志来分配内存。此类错误并不会被编译器给出报错提示,然而其在运行的时候,必定会引发相当严重的问题。
还有一个典型的错误在于忽视内核API的版本区分,针对不同的内核版本而言,其所对应的函数名、参数或者行为是有可能出现变化的,一旦模块使用了新版内核中已经被移除掉的函数,将没办法进行编译或者运行,鉴于此,在代码里通常都会运用#ifdef宏开展条件编译,或者条理鲜明地注明其所能支持的内核版本区间范围,无视版本兼容性是导致模块无法在他人系统上实现加载的常见缘由。

如何安全地传递参数和接收返回值
内核函数针对参数实施的检查,通常不像用户空间那般严格,要是传递错误参数,极容易致使内核崩溃。传递指针的时候,得格外小心:要保证用户空间传递过来的指针已历经严格验证(比如运用copy_from_user),并且要保证所指向的内核内存是有效的。对于像printk这样的格式化输出函数,要防止使用用户所提供的字符串来当作格式字符串,以免造成信息泄露或者崩溃。
保障稳健性的关键在于处理返回值 ,许多内核函数借由返回负数错误码(像 -ENOMEM 此种)去指示失败 ,成功之际返回 0 或者一个正数指针 ,调用之后必定要检查返回值 ,不可假定永远成功 ,资源申请函数(例如 request_irq)于失败之后 ,一定得清理先前已申请成功的全部资源 ,以防资源泄漏 。
调试内核函数调用问题的技巧是什么
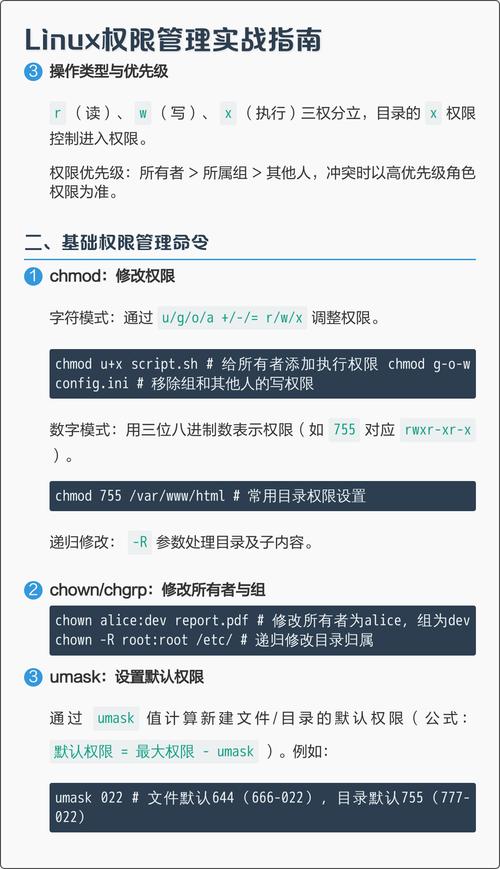
“printk”是最为基础的调试工具,该工具能够把相应信息打印至内核日志,此内核日志可借由“dmesg”予以查看。对打印等级予以合理设置,像设置成“KERN_ERR”这种情况,有助于对信息加以筛选。于复杂情形状况下,能够运用内核所内置的调试器,即KGDB来开展单步调试,然而这却需要进行额外的设置。Oops信息乃是深入分析崩溃现象的直接线索,在这些信息当中涵盖了调用栈以及错误地址 。
使用静态分析工具比如sparse能够于编译之前发觉某些上下文方面的错误 动态检查工具像是KASAN也就是内核地址消毒剂能够协助检测内存越界访问诸多问题 针对并发问题锁调试机制例如CONFIG_DEBUG_SPINLOCK是极为有用的 养成在代码里添加充分断言也就是BUG_ON WARN_ON的习惯能够在问题出现时迅速定位。
充满挑战的是探索内核的这趟旅程,每一回稳定的调用背后,都是针对细节的再三反复斟酌。当你尝试去调用某一个内核函数之际,碰到过最为意想不到的陷阱是啥呢?欢迎于评论区去分享你的经历,要是觉得这些经验具备有用性,也请点赞予以支持。
