哪怕做了那么多年运维,晚上手机铃声一响,我肾脏还是会漏跳半拍。
那个觉得大家都懂,迷迷糊糊摸过手机,见到告警群里一排白色的字,头脑顿时清醒,紧接着就是一身虚汗。打开笔记本,连上VPN,黑底黄字的终端窗口一跳下来,那时侯能救你的,不是哪些高大上的构架图,也不是PPT里吹的这些云原生概念,而是你敲打按键的胸肌记忆。
俺们这行,说白了,大部分时间是在和Linux内核那一堆莫名其妙的状态较劲。好多新人问我,说看了好几本书,命令背了一大堆,真出了事儿还是只会cd、ls、reboot三板斧。
虽然不是你背得少,是你没看懂什么命令是“看热闹的”,什么是“救命的”。明天我不跟大家扯哪些mkdir如何建目录,那个百度一下就有东西没啥好讲的。俺们谈谈这些真正能在CPU暴跌、磁盘爆满、网络丢包时,帮你快速定位“凶手”的家伙事儿。
这篇有点长,建议先收藏,上次排障没思路的时侯,翻下来瞧瞧。
top:不仅仅是看个热闹
出了问题,谁就会敲个top。但大部份人敲完top,也就瞧瞧那种%CPU谁最高,之后就没下文了。
兄弟linux find exec命令,那太浪费了。top这个界面,虽然是个矿藏。
这儿面最有用的虽然不是那种跳来跳去的CPU占用率,而是第一行的LoadAverage(平均负载)。这三个数字(1分钟、5分钟、15分钟)是你判定系统压力的第一道关口。
好多人搞不清楚Load究竟多少算高。有个很精典的的比喻:你把CPU想像成一座桥。
假如Load等于CPU核数,那是刚才好,车流顺畅。
假如Load小于核数,例如你是4核,Load到了8,那就意味着有一半的进程在排队等着过桥。
假如是CPU密集型任务,Load高一般意味着CPU真的不够用了;但若果是I/O密集型(例如数据库读写慢),Load高可能CPU占用并不高linux操作系统教程,而是大量进程卡在D状态(DiskSleep,不可中断睡眠)。
这时侯你在top界面按一下1,把所有CPU核展开瞧瞧,是不是某一颗核被跑死了?还是比较均衡?
再按一下c,显示完整的命令行路径,别只看个java或则是python,你得晓得是那个脚本在作妖。
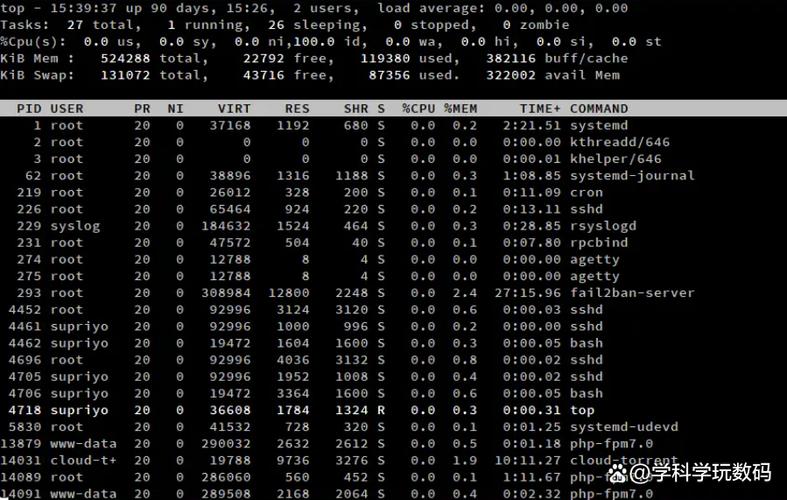
还有一个容易被忽略的:wa(I/Owait)。在CPU状态那一行,假如这个数字飙到了30%甚至50%,别查CPU了,赶忙去查查是不是c盘快挂了,或则数据库在疯狂刷盘。
vmstat:给系统把号脉
假如top看得眼花缭乱,认为信息量太大,我强烈推荐你用vmstat。
vmstat1,每1秒刷新一次。这命令简直就是系统的“心电图”。
盯住看几列:
曾经有次帮同学排查一个Web服务慢的问题,CPU不高,显存也够,就是慢。敲了个vmstat1,发觉cs(ContextSwitch,上下文切换)每秒好几万。后来查下来是代码里开了太多线程在空转,光是线程调度就把CPU累呕血了。这些问题,光看CPU使用率是看不下来的。
ps:捉贼要抓现行
ps你们都用,ps-ef|grepjava恐怕是好多人的起手式。
但我更喜欢用psaux--sort=-%cpu|head-10。
这行命令的意思是:列举所有进程,按CPU占用率降序排列,只看前10个。一目了然,谁是资源大户直接揪下来。
另外,还有一个场景非常搞态度。
就是你发觉一个进程卡死了,想kill掉它,结果它弄成了僵尸进程(Zombie,状态Z)。这时侯你用ps能够看见前面有个。
记住了,僵尸进程你是杀不死的,由于它早已死了。你要杀的是它的父进程(PPID)。
用ps-ef|grep僵尸进程PID找到它的PPID,之后送父进程上路,僵尸自然就消失了。
netstat&ss:究竟是谁连着我?
网路不通,或则端口被占,这时侯就是这两个兄弟登场的时侯。
老一点的系统用netstat,新一点的(CentOS7+)推荐用ss,由于ss跑得快,尤其是在并发联接数几万几十万的时侯,netstat能卡到你怀疑人生。
最常用的组合拳:ss-lntp。
还有一个场景,服务器联接数激增,你想瞧瞧是那个IP在搞你(或则是正常的业务洪峰)。
可以用这行神命令:
netstat-nat|awk'{print$5}'|cut-d:-f1|sort|uniq-c|sort-nr|head-20
看着长,虽然逻辑很简单:掏出所有联接->提取第五列(对端IP)->去除端标语->排序->统计每位IP出现的次数->按次数升序排->取前20个。
假如发觉某个陌生的IP有几千个联接,那恭喜你,可能被CC功击了,或则是那个内部服务配置错在疯狂重试。
awk&grep:文本处理的德国军刀
在Linux上干活,离不开处理日志。
曾经我也恶狠狠地用vi或则cat打开几个G的日志文件,结果终端直接卡死,被主管骂了一顿。
查日志,一定要学会“流式处理”。
grep就不多说了,加个-A10(显示匹配行以后10行)和-B10(之前10行)是基操,便捷你看报错的上下文。
这儿重点吹一下awk。这玩意似乎是一门编程语言,但我们不须要精通,会皮毛就够用了。
例如,Nginx的访问日志linux find exec命令,你想晓得那个插口访问最慢?
假定日志格式里,倒数第二列是响应时间。
tail-n10000access.log|awk'{if($NF>1)print$0}'
这就把近来一万条恳求里,响应时间超过1秒的恳求都复印下来了。($NF表示最后一列)。
再例如,你要把一个文件里所有的空行删除:
awk'NF'file.txt
就如此简单两个字母。
学会awk,你能把那一堆乱七八糟的日志弄成整齐的报表,老总见到就会感觉你这人显着“专业”。
lsof:谁动了我的文件?
这个命令全称是ListOpenFiles。它的强项在于解决这些“灵异风波”。
例如,最精典的:你明明用rm删掉了好几个G的大日志文件,结果df-h一看,c盘空间根本没释放!
这时侯别慌,多半是某个进程还打开着这个文件句柄没松手。系统觉得文件还在被用,只是从目录结构里删了入口而已。
输入lsof|grepdeleted。
假如你看见一堆标记着(deleted)的文件,找准前面那种进程PID,重启那种服务或则kill掉那种进程,空间顿时就回去了。那个看着c盘占用率从100%掉到40%的顿时linux移植,真的比捏脚还爽。
dmesg:内核在说哪些悄悄话?
有时侯,服务器挂了,但应用日志里啥也没有。Java没报错,Nginx也很正常。这时侯,你就得去问问操作系统本身了。
dmesg或则直接看/var/log/messages(Ubuntu下是/var/log/syslog)。

这儿面记录了硬件和内核级别的信息。
例如,OOM(OutofMemory)Killer。
假如你的Java进程忽然没了,也没留下任何遗书,多半是被Linux内核杀死了。
去dmesg|grep-i”kill”或则是grep”Outofmemory”瞧瞧。
假如见到类似Killedprocess1234(java)的字样,那就实锤了:显存不够,系统为了自保,挑了个最占显存的把你宰了。
还有网卡报错、硬盘I/O错误,这种底层硬件的哀号,也只能在这儿看到。
find:时间的魔法
运维除了要救火,还得会打扫战场。
清除旧文件,find是最靠谱的。
千万别手滑写个rm-rf/*,那你就出名了。
安全删掉30天前的日志:
find/var/log/myapp/-name”*.log”-mtime+30-execrm-f{};
解释一下:
有时侯你会遇见文件名是乱码或则带特殊字符删不掉的文件,也可以用find配合-inum(inode编号)来删,这招专治各类疑难杂症。
strace:最后的秘诀
假如里面那些都用了,还是找不到缘由。程序就是卡住,不报错,也不输出日志,CPU也不高。
这时侯,只能请出上帝视角的工具:strace。
它可以跟踪进程和Linux内核交互的所有系统调用。
strace-p进程PID
你会看见屏幕疯狂滚动:open(…),read(…),write(…),connect(…)。
假如屏幕忽然不动了,或则疯狂循环复印同一行报错,那就是卡住的地方。
有一次,一个Python脚本莫名其妙卡死,我挂上strace一看,发觉它在疯狂尝试联接一个外网不存在的DNS服务器,超时设置得非常长。没有strace,这问题我恐怕得查到今年去。
不过要注意,strace会严重拖慢程序运行速率,生产环境慎用,除非你真的走投无路了。
闲聊两句
写了那么多,虽然命令这东西,真是那是那句古语:熟能生巧。
刚入行的时侯,我也喜欢在桌面上贴个便利贴,里面写满了参数。后来敲得多了,遇见问题右手头比脑袋反应还快。
你们千万别认为运维就是搬服务器、装系统的。现今的环境越来越复杂,容器化、微服务、云原生,底层的逻辑虽然还是Linux内核那一套。你把那些基础命令玩透了,哪怕里面跑的是Kubernetes,Pod出问题了你进到容器里,用的还得是top和netstat。
工具是死的,人是活的。这种命令如同俺们手里的螺母刀和万用表,能不能修好机器,还得看俺们对系统原理的理解。
行了,明天就聊到这。原本还想扯扯tcpdump抓包的事儿,那种更剌激,上次有机会再单独开一篇细说。
要是认为这篇文章对你有这么一点点帮助,哪怕是帮你追忆起某个遗忘的参数,记得点个赞、在看,转发给身边那种还在对着死机苦恼的兄弟。
干运维不容易,俺们得相互撑着点。
