作为一名在运维一线摸爬滚打多年的工程师,我深知当系统出现卡顿、响应缓慢时linux events进程,第一反应往往是查看进程资源占用。而那个名为“events”的进程,常常是导致CPU飙升的幕后推手。它并非普通的用户进程中文linux操作系统,而是内核线程,主要负责处理硬件中断、定时器以及工作队列等底层任务。今天,我们就来深入剖析这个进程,从原理到实战,彻底解决它带来的困扰。
linux events进程是什么
Events进程实际上是多个内核线程的集合,常见的有events/0、events/1等,数字对应着CPU核心编号。它们就像内核的“勤务兵”,专门处理那些不需要立即响应的延迟任务。当硬件设备产生中断,或者内核需要推迟执行某项工作时如何安装linux,就会将这些任务放入队列,由events进程在合适的时机唤醒并执行。
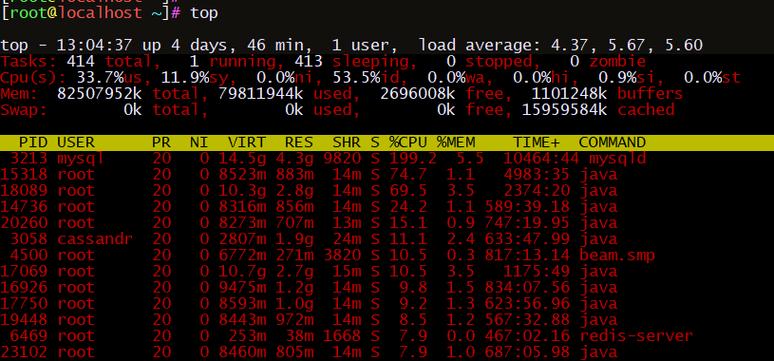
如果你在top命令下看到events进程占用率飙升,这通常意味着内核正忙于处理大量的软中断或工作队列任务。这可能源于硬件故障、驱动程序效率低下,或者某个应用程序疯狂地触发系统调用。理解这一点至关重要,因为它将引导我们跳出“杀进程”的惯性思维,转而从硬件、驱动、应用三个层面去定位根源。
events进程CPU高怎么办
当发现events进程CPU占用超过正常范围时,第一步是确认问题的严重程度。通过top命令观察,如果单核占用持续在50%以上,就需要立即介入。此时,不要盲目重启服务器,而是应该使用pidstat -t -p [进程PID] 1来查看该内核线程下具体是哪个子线程在消耗资源,例如是events/0还是events/1。
定位到具体的CPU核心后,结合mpstat -P ALL 1查看对应核心的软中断(%soft)占比是否异常。如果软中断非常高,可以进一步使用cat /proc/interrupts观察中断数量的变化,找出中断号增长最迅猛的设备。常见问题包括网卡队列积压、USB设备冲突,或是NVMe磁盘的驱动瓶颈。通过这种层层递进的方式,能精准锁定病因。
如何查看events进程日志
很多人误以为events进程没有日志,其实它的活动记录都隐藏在系统底层的接口中。最直接的方法是使用dmesg -T查看内核环形缓冲区信息,这里会记录硬件报错、驱动超时等信息。例如,频繁的“irq timeout”或“soft lockup”警告,通常就是events进程调度异常的征兆。
更精细的观察需要借助tracepoint。通过perf工具,我们可以追踪内核的工作队列执行情况。例如,执行perf record -e workqueue:workqueue_execute_start -a,就能捕获哪些函数被events进程调用了。如果发现某个驱动回调函数频繁出现,比如nvme_irq或ixgbe_poll,那就明确了问题出在对应的硬件驱动上。掌握这些工具,就等于拿到了解开谜团的钥匙。
内核参数优化能解决吗
适当的内核参数调整确实能缓解events进程的压力,但这需要极其谨慎。对于网络密集型应用,可以调整网卡多队列的亲和性。通过设置/proc/irq/[中断号]/smp_affinitylinux events进程,将特定网卡中断绑定到指定的CPU核心上,避免所有中断都涌向同一个核,从而分散events/0的负载。
另一个常用的优化是调整内核的看门狗阈值。如果系统频繁出现“soft lockup”报错,可以适当增大kernel.watchdog_thresh的值。但请注意,这属于“治标不治本”的掩盖手段。更根本的做法是检查vm.zone_reclaim_mode等内存参数,因为内存回收压力过大时,也会通过工作队列触发大量的events线程活动。参数优化应当基于对业务场景的深刻理解,而非盲目套用。
应用层如何避免影响
从应用开发的角度看,某些编码习惯会无形中加重events进程的负担。最典型的是频繁的mmap和munmap操作。每次内存映射的建立与释放,都会引发内核的内存管理工作队列活动。在高并发场景下,这种系统调用的风暴会让events进程疲于奔命。
使用epoll时,如果关注的事件类型过于宽泛,或者频繁修改epoll的监控列表,同样会导致内核事件通知机制产生大量额外开销。对于数据库或消息中间件这类程序,建议开启大页内存(HugePages)来减少TLB miss,这能从根本上降低内核进行内存管理时产生的events开销。优秀的应用代码应当懂得与内核和平共处,而不是肆意挥霍系统资源。
故障排查实战案例

上个月,我接手了一起典型案例:一台Kafka节点在业务高峰期出现严重的“假死”现象。登录服务器后,top显示events/2占用达到了98%,而业务进程几乎无法获得CPU时间。通过pidstat确认是events/2异常,再结合mpstat发现CPU 2的软中断高达85%。
我立刻查看/proc/interrupts,发现中断号39(对应网卡eth0)的每秒增量高达10万次。进一步检查发现,该服务器的网卡驱动版本与操作系统内核版本存在兼容性问题。在将网卡驱动从ixgbe 5.6.3升级到5.12.5后,中断数量骤降至正常水平,events/2的占用也随之降到了5%以下。这个案例告诉我们,保持驱动与内核的同步更新,远比事后查问题更有效。
你在生产环境中是否也遇到过类似events进程异常导致系统卡顿的棘手问题?当时你是如何快速定位并解决的?欢迎在评论区分享你的实战经验,让我们一起探讨更多内核排障的实用技巧。
