在日常Linux运维中,我们经常需要统计符合某种模糊规则的文件数量,比如查找所有日志文件、特定后缀的配置文件等。如果手动数或挨个查看,既低效又容易出错。掌握模糊查询文件个数的命令组合linux模拟,能让你在几秒内精准获取统计结果。本文结合真实场景,分享6个最常用的方法。
如何用通配符统计文件数
在Linux当前目录下,星号和问号是最简单的模糊匹配符号。例如想统计所有.txt结尾的文件个数,直接运行ls <strong>.txt | wc -l即可。但需要注意长春linux培训,如果匹配不到任何文件,ls会报错,而wc -l会输出0,所以最好用ls </strong>.txt 2>/dev/null | wc -l屏蔽错误信息。另一种更稳妥的方式是使用数组:files=(<strong>.txt); echo ${#files[@]},即使没有匹配文件也会输出0。
通配符只能处理当前目录,且不支持更复杂的模式比如匹配“以a开头、中间任意、以b结尾”。这时可以将通配符与echo结合:echo </strong>.log | wc -w,-w统计单词数。但注意如果文件名包含空格,这种方法会出错。实际生产环境中,推荐优先使用find命令,它对空格和换行符的处理更可靠,后面会专门讲解。
find命令怎样模糊计数
find是Linux下最强大的文件查找工具,它的-name参数支持通配符模糊匹配。要统计当前目录下所有以conf结尾的文件个数,可以执行find . -maxdepth 1 -type f -name "<strong>.conf" | wc -l。其中-maxdepth 1限制只在当前目录,去掉它则递归搜索所有子目录。注意-name是区分大小写的,如果想不区分大小写,改用-iname。
如果文件名中包含换行符,直接| wc -l会漏数。安全做法是使用-print0让find以空字符分隔输出,再配合tr或grep -c:find . -type f -name "</strong>.sh" -print0 | grep -cz "^"。另外,find还可以配合-exec做更复杂的统计,比如统计大小超过1M的压缩包数量:find . -size +1M -name "<strong>.tar.gz" | wc -l。掌握这些参数,模糊查询文件个数将变得极其灵活。
ls和wc组合注意点
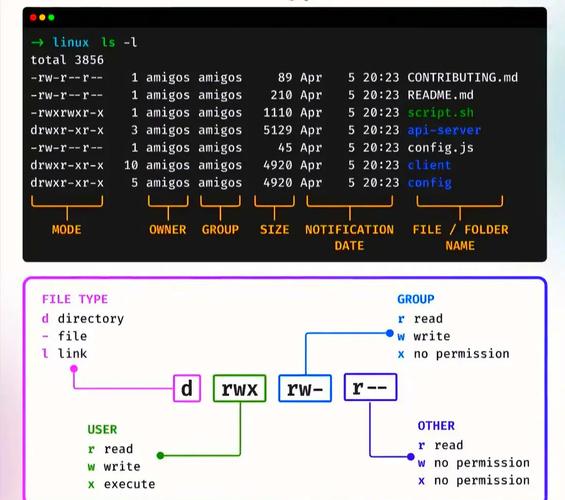
很多新手直接用ls -l | grep "pattern" | wc -l来模糊统计,但这种方法存在隐患。ls的输出会包含文件权限、所有者等额外信息,如果文件名恰好匹配了权限字符串中的字母,grep就会误判。例如想统计包含“log”的文件,-rw-r--r--里的“r”不会干扰,但更危险的是一些特殊字符。正确做法是让ls只输出文件名:ls -1(数字1)每行一个文件,然后grep过滤,最后wc -l。
另一个常见错误是忽略隐藏文件。默认ls不显示点开头的文件,需要加上-a选项:ls -1a | grep "^." | wc -l可以统计所有隐藏文件个数。如果想模糊匹配以.bak结尾的隐藏文件,ls -1a | grep ".bak$" | wc -l。注意grep本身也支持模糊正则linux模糊查询文件个数,比如grep -E "file[0-9]+"。但整体上,ls管道法只适合简单场景,生产环境推荐find。
模糊查询时忽略大小写
日志文件常常混用大小写,比如Error.log、error.LOG、ERROR_log。此时需要忽略大小写来统计所有相关文件个数。使用find的-iname参数即可:find /var/log -type f -iname "</strong>error<strong>" | wc -l,它会匹配大小写任意组合。如果没有-iname,可以借助-name配合[Ee][Rr][Rr][Oo][Rr]这样的字符集,但写法繁琐,不推荐。
如果系统不支持-iname(极老旧版本),可以用find输出所有文件再交给grep -i:find /var/log -type f | grep -i "error" | wc -l。不过这样做会匹配路径中包含“error”的目录名,可能产生多余结果。更严谨的是用find的-regex参数:find . -type f -iregex ".</strong>error.<strong>" | wc -l,-iregex不区分大小写且支持完整正则。掌握这些技巧,无论文件名如何大小写混杂,你都能精准统计。
包含子目录的文件个数统计
项目目录往往有几十层子文件夹,你需要统计其中所有</strong>.java文件的数量。很简单,用find不加-maxdepth限制即可:find . -type f -name "<strong>.java" | wc -l。但如果只想统计特定深度的子目录,比如只往下查两层,用-maxdepth 2。或者只统计当前目录及其直接子目录,但不深入子目录的子目录:find . -maxdepth 2 -mindepth 1 -type f -name "</strong>.java" | wc -l。
另一个常见需求是排除某些子目录,比如跳过test文件夹。可以用-not -path:find . -type f -name "<strong>.py" -not -path "./test/</strong>" | wc -l。如果要排除多个目录,可以叠加-not -path或用正则。统计包含子目录的文件数时,注意软链接可能导致重复统计,加上-type f只查普通文件。对于超大目录树(十万级以上文件),建议加上-quit或先测试,避免wc -l长时间等待。
隐藏文件如何参与模糊匹配
隐藏文件以点开头linux模糊查询文件个数,默认会被很多命令忽略。在ls中需要加-a,在find中默认不会忽略隐藏文件,但需要注意路径写法。例如find . -name ".<strong>"会匹配所有隐藏文件和隐藏目录,加上-type f则只统计隐藏文件个数。如果想统计当前目录下所有.bash</strong>开头的隐藏文件:find . -maxdepth 1 -type f -name ".bash<strong>" | wc -l。
使用通配符时,.</strong>会匹配到当前目录.和上级目录..,导致结果错误。正确统计当前目录所有隐藏文件个数(不含.和..)可以这样:ls -1a | grep "^." | grep -v "^.$" | grep -v "^..$" | wc -l,但太繁琐。推荐用find . -maxdepth 1 -type f -name ".<strong>" -not -name "." -not -name ".." | wc -l。更简单的方法:开启dotglob选项:shopt -s dotglob; files=(.</strong>); echo ${#files[@]}; shopt -u dotglob,注意要减去2个特殊目录。实际工作中,建议直接使用find,它天然安全。
你在日常工作中是否遇到过因为模糊查询文件个数不准确而导致误操作?欢迎在评论区分享你的踩坑经历,点赞让更多运维朋友看到这些实用技巧。
