为什么要监控进程
在Linux服务器开发中,进程监控是保障服务稳定性的基石。很多开发者初学阶段往往忽略进程状态变化,直到线上服务突然挂掉才意识到监控的重要性。实际上,进程可能因为内存泄漏、死锁、外部攻击或系统资源耗尽而异常退出,如果没有监控机制,你甚至无法第一时间发现问题。
从实际运维经验看,一个没有进程监控的服务器就像蒙着眼睛开车。进程监控不仅能帮你及时发现服务宕机,还能记录进程的资源消耗趋势,为容量规划和性能优化提供数据支撑。无论是Web服务、数据库还是后台任务linux服务器开发 监控进程,每个运行中的进程都值得你认真对待。
如何监控进程CPU使用率
在Linux环境下,最常用的CPU监控命令是top和htop。top命令能实时显示各进程的CPU占用百分比,按Shift+P可按CPU使用率排序。你可以结合watch命令实现周期性采集,比如“watch -n 1 ‘ps -eo pid,pcpu,comm --sort=-pcpu | head’”,这样可以快速定位CPU飙升的异常进程。
针对长期监控需求,建议使用pidstat工具,它属于sysstat软件包。执行“pidstat 1 10”会每秒采样一次CPU数据,共采集10次,输出内容包括用户态和系统态的CPU占用。你可以编写脚本将pidstat输出重定向到日志文件,配合定时任务实现按小时归档linux vi命令,方便后续回溯分析。
内存监控怎么做
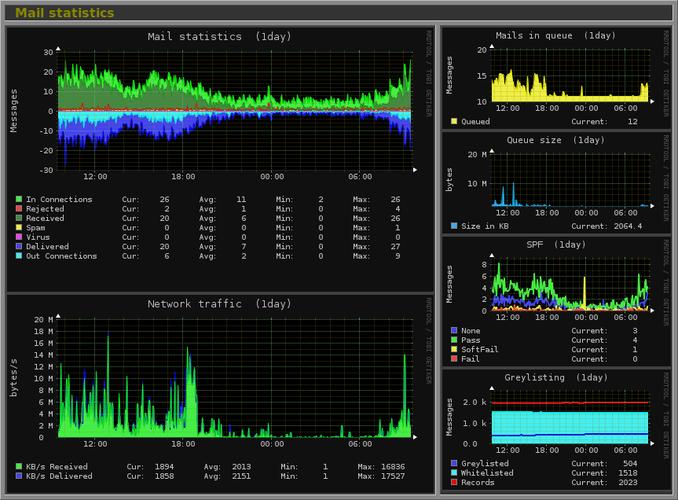
内存泄漏是服务器开发中最隐蔽的问题之一。通过“ps aux --sort=-rss”可以列出按物理内存占用排序的进程,RSS列代表实际使用的物理内存。更专业的工具是smem,它能区分USS(独占内存)、PSS(比例分摊)和RSS,帮你准确评估每个进程的真实内存开销。
进阶监控手段是使用Valgrind的memcheck工具检测内存错误linux操作系统安装,但这对性能影响较大,不适合生产环境。在生产环境中,推荐集成tcmalloc或jemalloc的内存分析功能linux服务器开发 监控进程,定期输出内存统计信息。此外,可以设置/proc/[pid]/smaps文件的监控脚本,当某进程的匿名内存映射区域持续增长时触发预警。
进程自动重启方法
实现进程崩溃后自动重启,最简单的方案是编写一个while循环脚本:while true; do /path/to/your_program; sleep 1; done。但这种方式缺乏优雅退出和日志记录。更好的选择是使用supervisor,这是一款成熟的进程管理工具,只需配置program的command、autorestart和startretries参数,即可实现崩溃秒级重启。
对于系统级关键服务,建议使用systemd的Restart机制。在service单元文件中设置Restart=always和RestartSec=5,当进程异常退出时systemd会自动拉起。如果你开发的是网络服务器,还可以结合fork()系统调用,父进程监控子进程的SIGCHLD信号,并调用waitpid获取退出状态码,针对不同状态码执行差异化恢复策略。
监控工具选择对比
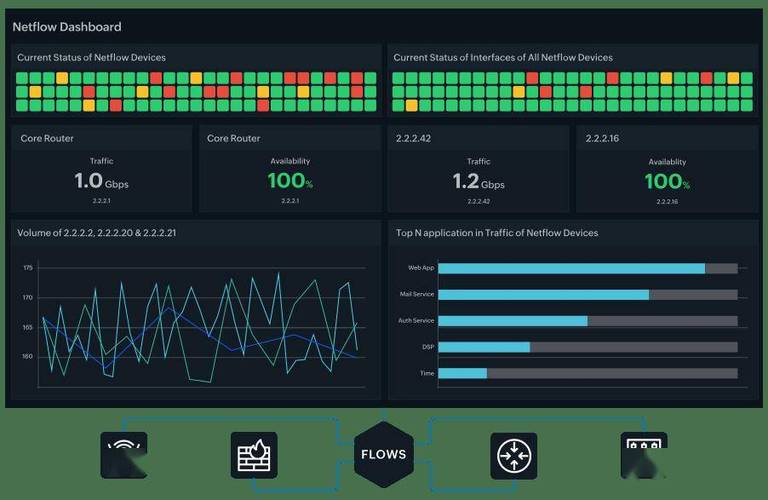
轻量级场景推荐使用cron+ps脚本。每5分钟执行一次“ps -C your_process_name”或检查pid文件,若进程不存在则执行启动命令。这种方案依赖少、易调试,适合资源受限的嵌入式设备或容器环境。但缺点是监控周期最小为1分钟,无法做到秒级响应。
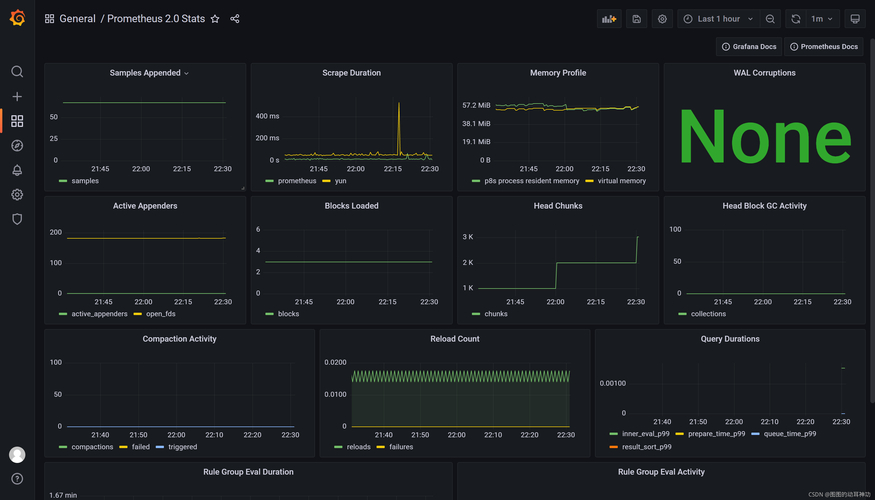
企业级生产环境则建议部署Prometheus+Node Exporter+Alertmanager。Node Exporter采集进程的CPU、内存、文件描述符等指标,Prometheus每15秒拉取一次数据,并通过PromQL查询“absent(process_running)”来触发告警。配合Grafana可以画出进程生命周期曲线,让历史状态一目了然,优势在于扩展性强、告警规则灵活。
进程异常告警配置
告警的核心原则是“分级触发”。对于非关键进程,可以设置连续三次检查失败后再发送邮件;对于核心服务,应采用秒级探测并发送钉钉或企业微信通知。告警消息中必须包含主机名、进程名、PID(若曾存在)、时间戳以及最近三条系统日志,方便接手人员快速定位原因。
实战中推荐使用alertmanager的grouping特性,避免同一进程频繁抖动时告警轰炸。结合webhook可以对接自研运维平台。同时要配置恢复通知,当进程重新稳定运行后自动发送“已恢复”消息。最重要的是设置静默规则,例如凌晨三点到五点计划重启维护期间临时屏蔽告警,否则运维人员的睡眠质量会大打折扣。
你是否也遇到过进程莫名挂掉却毫无日志的尴尬情况?欢迎在评论区分享你的排查故事,一起探讨更可靠的监控方案!点赞收藏本文,让更多Linux开发者避开这些坑。
