很多刚接触系统级开发的开发者都会觉得Linux内核源代码晦涩难读,动辄几百万行的代码量很容易让人产生畏难情绪。实际上只要找对切入路径深入分析linux内核源代码,顺着核心子系统的调用脉络逐层溯源,就能一步步摸透内核的运作本质,真正读懂这段支撑服务器、移动设备等海量场景的底层代码。
怎么筛选核心源码模块
刚开始梳理Linux内核源代码时,不要直接钻进所有零散文件中,优先聚焦和系统核心功能强关联的几大块目录。比如先从处理器初始化、内存管理、进程调度这几个高优先级模块入手,先搭建起内核运行的基础框架认知。

我们可以借助内核官方的MAINTAINERS文档,快速找到每个模块对应的维护者说明和简要注释内容,跳过无关的驱动、第三方适配的冗余代码。这样就能把原本几百万行的代码规模压缩到十分之一左右深入分析linux内核源代码,大大降低初期的分析门槛。
用开发环境搭建源码索引
完成核心模块筛选后,要先搭建起适配内核源码的索引分析环境,告别仅靠文本编辑器逐行查找的低效方式。我们可以选择Cscope搭配VsCode插件的组合,能快速实现函数跳转、调用关系查询红旗linux桌面版,大幅提升代码阅读的流畅度。
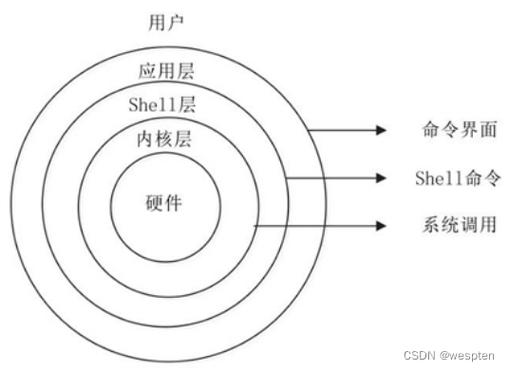
索引环境搭建好后,可以给核心子系统做好分类标签,给关键数据结构、核心函数的入口加好批注。后续分析不同调用链路时能直接跳转到对应位置,不会在海量文件里茫然回溯,整个源码分析的效率会提升数倍。
怎么梳理内核启动链路
梳理内核启动链路要从汇编入口文件head.S开始,跟着处理器上电后的第一行执行指令往下推进。从汇编阶段的硬件初始化、页表搭建,跳转到内核第一个C函数start_kernel后,系统所有基础服务的初始化流程就正式展开了。
沿着start_kernel里的函数调用顺序,我们可以依次追踪中断、内存子系统、调度器的初始化流程,能清晰看到整个内核从空白状态逐步准备好运行环境的全过程。这段链路能帮你快速建立起内核程序运行的全局时间线。
分析进程调度源码方法
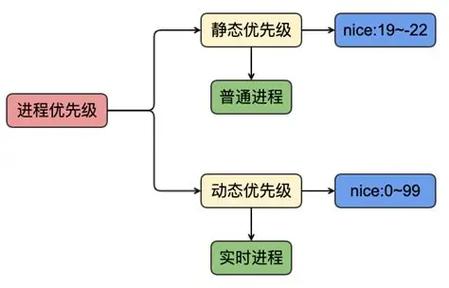
分析进程调度功能的源代码,要先找到调度类、调度实体这两个核心数据结构的定义,理解不同调度策略背后的分类逻辑。不管是CFS公平队列还是实时调度的处理逻辑,都是依托这两个核心结构来组织。
顺着schedule这个核心调度函数的调用路径红旗linux5.0,往下追踪 pick_next_task 获取下一个运行进程的完整流程,再关联上时钟中断触发调度的回调逻辑,就能完整摸清楚内核怎么轮转CPU执行权来实现多任务并发。整个逻辑链路通了之后,调度部分1万多行的源码很容易就能读透。
怎么理解内存管理源码

理解内存管理的源代码,要先分清页表页帧、虚拟地址空间内核映射这些核心基础概念的代码实现。跟着 buddy 伙伴系统、slab分配器的入口函数追踪资源分配和回收的逻辑,理清楚物理内存的整体管理框架。
随后再推导用户态malloc在之内核对应的brk、mmap系统调用的实现链路,把虚拟地址到 physical 页帧的映射过程一步一步拆解,就能打通用户态内存申请到内核底层分配的全链路逻辑,整个内存管理体系就变得完全清晰。
调试内核源码小技巧
直接在开发板或者虚拟机挂载调试模块,用printk在外核关键路径加日志输出,是成本最低的动态调试方式。能直观看到你关注的函数实际运行的入参和执行分支,快速验证自己对代码逻辑的推导是否正确。
进阶一点可以用Kprobe动态插入探测点,不需要重新编译打包整个内核,就能随时监控任意内核函数的执行情况。结合gdb在线内核调试工具,甚至可以断点单步跟踪内核函数的执行,把纸面上的源码逻辑和实际运行的流程完全对应起来。
Linux内核源代码的深入分析是一个循循渐进逐步进阶的过程,不用急着一次性吃透所有模块,顺着自己接触的开发场景逐步扩展分析范围,就能慢慢掌握所有核心逻辑。你在分析Linux内核源码的过程中,第一个啃透的子系统是哪一部分呢?欢迎在评论区分享你的经验,觉得内容实用的话也可以点赞转发给更多希望学习内核源码的朋友。
