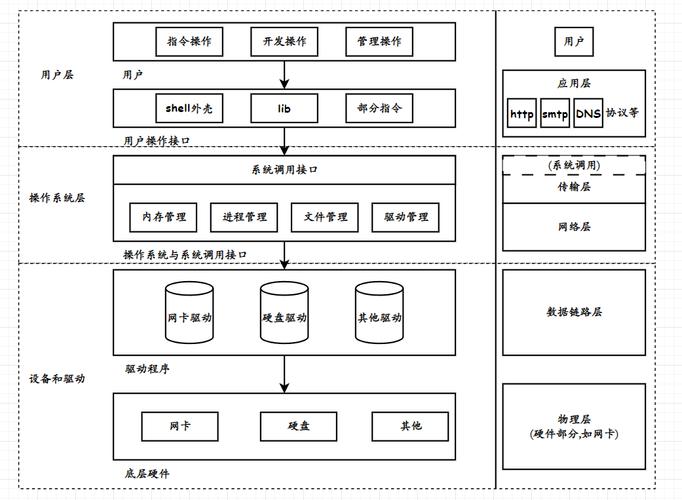
Linux内核网络栈是操作系统处理网络数据包的核心机制,它负责将应用程序发出的数据层层封装、发送到物理网络,再将从网卡收上来的数据包解析并递交给正确的进程。理解这个栈,不仅是内核开发者的基本功,也是后端工程师排查网络延迟、优化吞吐量的关键。
数据包从网卡到应用的完整路径
当一个网络数据包到达网卡时,内核网络栈的表现就像一个精密的快递分拣系统。网卡通过DMA(直接内存访问)将数据包直接写入内存中的环形缓冲区,避免CPU参与数据搬运,这是高性能的起点。随后,网卡触发硬件中断,通知内核有数据到达。
中断处理程序会尽快完成必要的登记工作,然后调度一个软中断(SoftIRQ)来处理后续更耗时的任务。在软中断上下文里美国linux主机,内核会调用驱动程序提供的接收函数,将数据包从缓冲区取出,交给协议栈。数据包会依次经过链路层(检查MAC地址、解析VLAN)、网络层(IP校验、路由查找、分片重组)、传输层(TCP/UDP端口匹配、状态机更新),最后根据socket类型,将数据放入对应进程的接收队列。应用程序只需调用read或recvfrom就能拿到数据。
这个过程看似简单,但每个环节都可能成为瓶颈。例如,大量的小包可能导致频繁的中断,而中断上下文又不能做太多工作,所以现代网卡普遍支持多队列(RSS)和中断合并(coalescing),让不同CPU核分担处理压力。
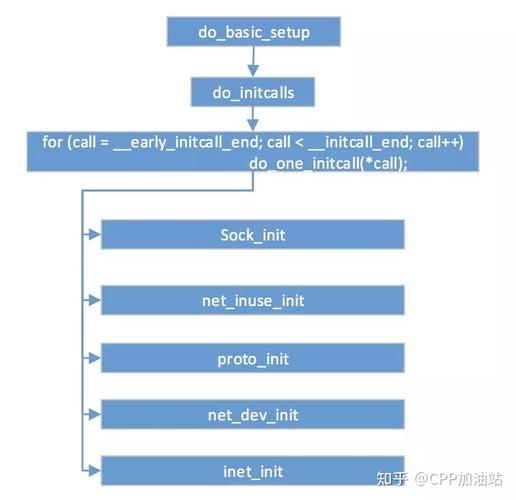
内核协议栈如何影响网络延迟
网络延迟不仅取决于物理距离,更取决于内核处理数据包的速度。在传输层,TCP协议栈的状态管理尤为复杂。三次握手、拥塞控制、重传定时器,这些机制都会在数据流动中引入微秒甚至毫秒级的延迟。
举个例子,当进程发送数据时,系统调用会陷入内核,TCP层会先检查发送窗口和拥塞窗口,如果窗口允许,就将数据分段并加入发送队列。然后调用IP层进行路由选路和分片,最后通过邻居子系统(ARP/ND)找到下一跳的MAC地址,交由网卡驱动发送。每一个步骤都需要持有锁,尤其在多核环境下,锁竞争会显著增加延迟。
内核还提供了许多优化选项。比如TCP_NODELAY可以禁止Nagle算法,避免小包被延迟发送;SO_PRIORITY可以设置套接字优先级,让关键流量优先得到处理。对于追求极低延迟的场景(如金融交易),甚至需要绕过内核协议栈,使用DPDK或XDP技术,直接把数据包从网卡映射到用户态处理。
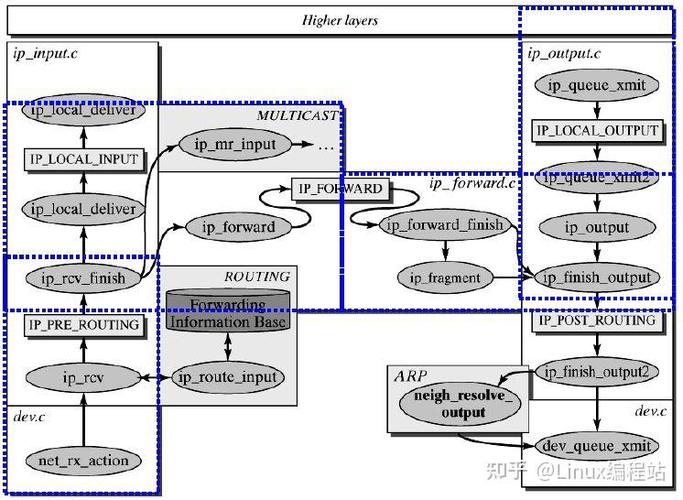
网络栈性能瓶颈在哪里
性能瓶颈往往出在最容易被忽视的地方。首先是中断处理,如果网卡中断都落在同一个CPU核上,这个核会因为频繁的中断而负载过高,导致其他任务得不到调度。解决办法是启用多队列网卡linux vi,并绑定不同队列到不同CPU核。
其次是内存分配。每接收一个数据包,内核都需要分配sk_buff结构体和数据缓冲区。大量并发连接时,内存分配器的压力巨大,可能导致缓存失效。使用内存池(如kmem_cache)和页分配器可以有效缓解。
还有锁的粒度。在Netfilter框架中,iptables的规则匹配会在每个包经过时加锁,如果规则链过长linux内核网络栈,锁竞争会非常严重。改用nftables或eBPF程序可以显著降低开销。eBPF允许你在数据包经过协议栈的早期阶段(如XDP hook点)执行自定义逻辑,实现高效的包过滤、统计和负载均衡。
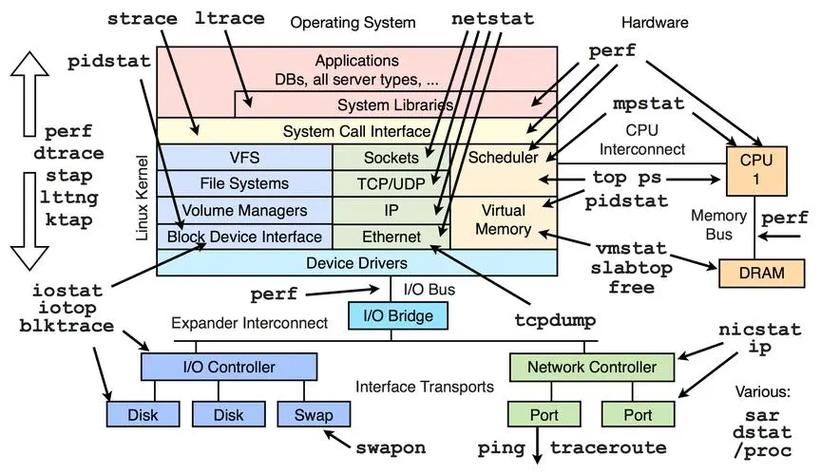
如何利用内核调优提升网络性能
调优的第一步是识别瓶颈。使用perf、bpftrace、netstat和ethtool等工具,观察中断分布、CPU使用率、丢包统计和缓冲区溢出情况。例如,netstat -s可以显示TCP的重传、丢包等异常指标,ethtool -S能查看网卡驱动的详细计数器。
针对常见场景,有几项调优几乎总能见效。增大接收和发送环形缓冲区的大小(ethtool -G),可以减少在高流量下的丢包。调整内核参数net.core.rmem_max和net.core.wmem_max,允许应用使用更大的套接字缓冲区。对于长连接密集型服务,开启tcp_tw_reuse(需确认系统支持)和tcp_fastopen可以缩短连接建立时间。
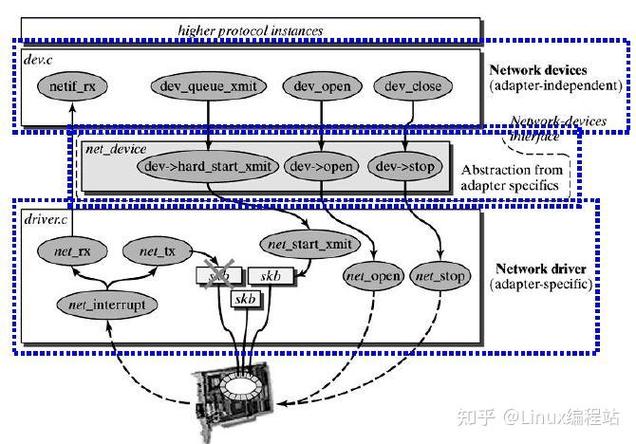
更高级的调优涉及内核编译选项。如果确认不需要IPv6linux内核网络栈,可以在内核配置中禁用,减少协议栈的复杂度。同样,关掉不必要的Netfilter模块、禁用TCP拥塞控制算法中的那些试验性算法,也能小幅提升性能。但要注意,每个环境的负载模型不同,最好在测试环境验证后再应用到生产。
网络栈的每个层次都藏着影响性能的细节。从网卡中断到应用读取,任何一个环节的失调都可能让整个系统的吞吐量骤降。真正理解这些流程,才能在排查问题时快速定位,而不是盲目修改参数。
