
前言
又来更新了,得空记录下之前写得一个需求,欢迎大佬前来指教,轻喷
需求 导出Excel:本身以为是一个简单得导出,但是每行得记录文件中有一列为图片url,需要下载所有记录行对应得图片,然后压缩整个文件夹。
1.生成对应Excel___
2.根据时间日期创建对应文件夹#精确到毫秒级_____
3.Excel写入到对应得文件夹___
4.多线程根据图片Url写入到对应文件夹____
5.压缩整个文件夹,打包成.zip文件____
6.接口响应下载Url页面进行下载____
这里只做4.5.得代码讲解描述,其它也没什么好说得,话不多说上代码.

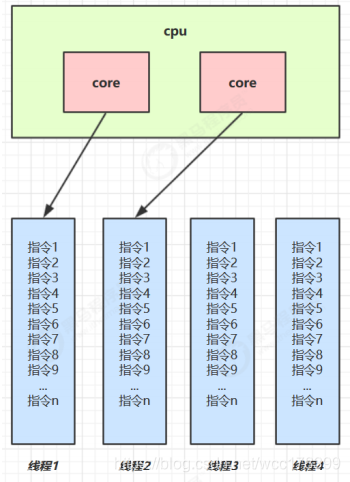
实现思路
多线程实现使用了线程池,Jdk1.8并发包下的CompletableFuture
第一步:得到基础数值
// 线程数
Integer threadNum = 10;
// 每条线程需要处理的图片数
int dataNum = imageInfoVos.size() / threadNum;
// 写入线程数
List threadS = new ArrayList();
for(int i=0; i<threadNum; i++){
threadS.add(i);
}
首先我们保存了需要下载的图片的Url列表,多线程的方式下载我们需要保证每个线程下载的图片不会重复,因此我们需要根据规则来切割保存Url列表的集合RAR FOR LINUX,从而保证每个线程下载属于自己的任务,上代码 :
// 接上文代码
threadS.stream().map(item -> CompletableFuture.runAsync(() ->{
List theadItem = imageInfoVos.subList(dataNum * item,(item+1)==threadNum?imageInfoVos.size():Math.min(dataNum * (item + 1 ), imageInfoVos.size()));
threadDownPic(theadItem,item,dirName);
},threadPoolTaskExecutor)).collect(Collectors.toList()).forEach(item ->{
try {
item.get();
}catch (Exception e){
log.error("============ 多线程down执行等待异常 msg:{} =============", e.getMessage());
}
});
这里进行拆分讲解
使用CompletableFuture.runAsync 走异步方式,遍历item
如item=10,也就是线程数为10,则直接执行10次(有线程池的前提下)
// 使用CompletableFuture.runAsync 走异步方式,遍历item
// 如item=10,也就是线程数为10,则直接执行10次(有线程池的前提下)
threadS.stream().map(item -> CompletableFuture.runAsync(() ->{规则: 根据item数值通过sublist 从开始到结束,截取对应线程所需要下载的Url列表
例:dataNum为每个线程需要完成的下载数如上文 dataNum为100时
如:item=0 dataNum* item(0) =0,Math.min(dataNum * (item + 1 )=100
(item+1)==threadNum?imageInfoVos.size() 此次是为了保证最后一个线程处理最后不足的图片
根据如上规则即可得到每个线程需要下载的图片Url保证不会重复
// 根据item数值通过sublist 从开始到结束,截取对应线程所需要下载的Url列表
// 例:dataNum为每个线程需要完成的下载数如上文 dataNum为100时
// 如:item=0 dataNum* item(0) =0,Math.min(dataNum * (item + 1 )=100
// 根据如上规则即可得到每个线程需要下载的图片Url保证不会重复
// (item+1)==threadNum?imageInfoVos.size() 此次是为了保证最后一个线程处理最后不足的图片
List theadItem = imageInfoVos.subList(dataNum * item,(item+1)==threadNum?imageInfoVos.size():Math.min(dataNum * (item + 1 ), imageInfoVos.size()));
// theadItem:图片Url item:所属下标 dirName:写入路径url
threadDownPic(theadItem,item,dirName);由于执行的异步方式,此处是为了线程池中所有线程都结束才能往下走,执行压缩文件步骤linux 常用命令,这里提一嘴,如果没有手动赋予线程池打包压缩命令linux,CompletableFuture默认使用monPool,会根据电脑核心数来指定,
比如:我本机未指定就是7个线程打包压缩命令linux,执行方法时,会执行完前面7个线程任务,才会继续创建3个线程继续执行后续未完成的
},threadPoolTaskExecutor)).collect(Collectors.toList()).forEach(item ->{

try {
item.get();
}catch (Exception e){
log.error("============ 多线程down执行等待异常 msg:{} =============", e.getMessage());
}
});实测
主要代码也写完了,这种方式真的能提高效率吗?下面我贴几张测试图来说明
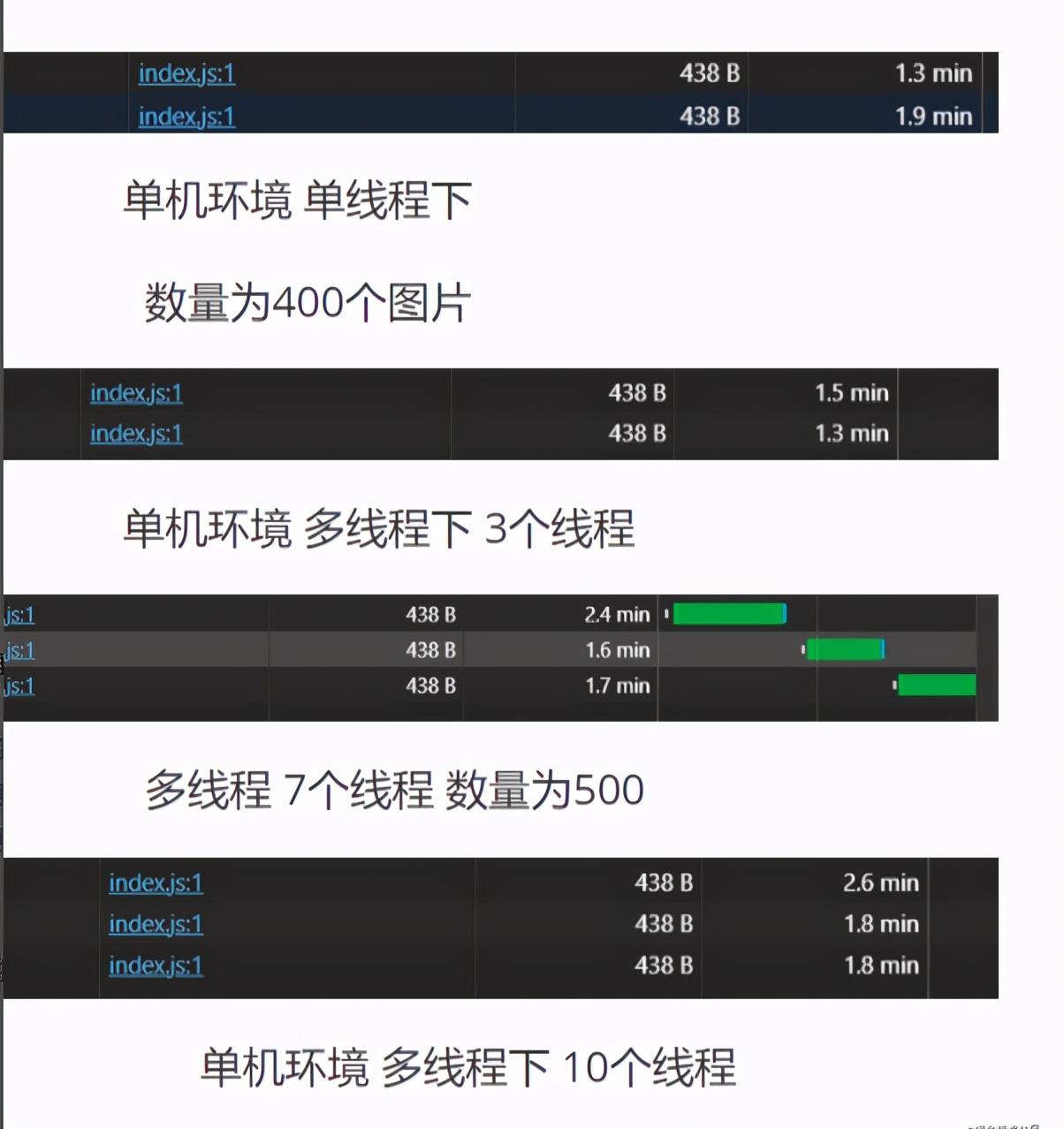
其实这种方式并没有显著的提高效率,当然这是我本机环境测试的。
效率是由网速决定,而不是由本机Cpu和io决定,比如10M带宽,一个线程一个一个顺序下载,但速度是10M,10个线程,可能每个线程的速度是1M,结果没有什么两样。 相对于网速,多线程带来的cpu以及io节省的时间几乎可以忽略,瓶颈还是在网速.
接口优化点为:提高压缩效率可以不将图片保存到本地而直接压缩文件流
