在Linux操作系统中linux虚拟主机,采用UTF-8编码的文件经常会出现乱码问题,这种情况很常见,解决起来也比较困难。这种情况不仅会影响我们正确读取文件内容,还可能对日常的工作流程造成干扰。下面,我将具体分析造成这一问题的原因linux utf8文件 乱码,并给出相应的解决策略。
乱码现象初察
在Linux操作系统中查看UTF-8格式的文件时,有时会遇到乱码现象,这种现象呈现多种形态。部分文件内容看起来像是杂乱的符号,段落和换行显得十分混乱;严重的情况下,整篇文本都难以辨认。这些问题让我们在阅读和处理文件时感到困难,极大地降低了工作效率,让人感到十分烦恼。
文件格式和大小等因素可能导致乱码现象出现不同。体积较小的文件,乱码情况通常较轻;但体积较大的文件,乱码问题可能变得特别严重。当乱码问题出现时,我们往往需要花费很多时间去查找和解决,而且在这个过程中,每一次尝试都可能带来不确定的后果。
常见原因探究
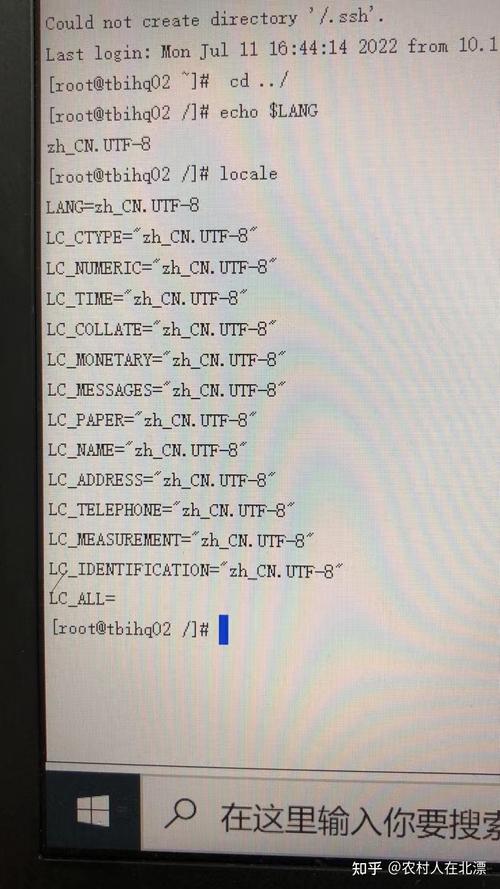
可能是系统字符集配置出现了故障。在Linux操作系统中,它默认采用的字符集并非UTF-8。以一个例子来说明,若系统被设置为GBK或其它编码方式,那么在尝试读取UTF-8编码的文件时,就会发生冲突,进而导致显示乱码。这就像两个人使用不同的语言交流,尽管他们所说的话是正确的,但对方却无法理解其含义。
编辑器在处理编码时有时会出错,导致显示乱码。若编辑器无法准确识别文件为UTF-8编码,就会按照其预设的编码规则去解析内容,这往往会导致乱码的出现。这种现象在非专业或未支持UTF-8编码的编辑器中更为常见,因为它们往往缺乏对UTF-8编码的精确解析能力。
文件传输影响
当文件在一套系统传输到另一套Linux系统时,如果在文件编码的某个环节出现了错误,就可能导致乱码的出现。例如,在网络传输阶段,如果网络协议或者传输工具对文件的编码进行了不正确的转换,原本的UTF-8编码就有可能被破坏。
而且,不同系统之间的环境差异可能在传输过程中引发问题。有些服务器在接收文件时,会自动按照自己的编码规则进行处理,这可能会使原本的UTF-8文件变得面目全非。所以,即便我们接收到的文件原本是正常的,也可能出现乱码现象。
编程交互问题
在编程界,一旦代码在处理文件编码环节出错,就会导致采用UTF-8编码的文件出现乱码。举例来说,像Python、Java这样的编程语言,如果在读取文件时没有正确设定文件的UTF-8编码格式,程序就可能会错误地解析文件里的数据。
某些框架和库在处理UTF-8编码时可能存在不足。使用这些工具处理文件时,可能会遭遇兼容性问题,从而引发文件乱码。这种现象会使编写的程序难以正常运行,同时也会让代码调试变得更加复杂。
解决方法尝试
调整系统字符集设置是一项基本任务。我们通常通过编辑特定的配置文档来完成这一操作,例如,将字符集改为UTF-8格式。以CentOS系统为例,我们必须对/etc/sysconfig/i18n文件进行修改,将编码设定为LANG="en_US.UTF-8"。采用这种方法,系统能够精确地辨认并妥善处理那些采用UTF-8编码的文档。
在文本编辑软件里,我们可以在打开文件时自行选择编码方式。以Vim编辑器为例,输入:set fileencoding=utf-8这样的命令,就能更改编码,这通常能帮助解决一些乱码问题。不过,进行这一操作时,一定要记得保存文件linux deepin,以免编码设置失效。
测试验证结果
完成所有操作流程后,我们需要对所得结果进行验证。首先,我们需要重新打开文件,查看乱码是否已消失。然后,我们可以尝试复制文件内容并粘贴到其他地方linux utf8文件 乱码,以检查复制后的内容是否能够正常显示。如果文件是用特定软件处理的,我们就需要启动该软件,观察它是否能够正确处理该文件。
若发现数据中有异常字符,便需进行细致的审查。需逐一确认每项设置是否正确无误,并且可以参考其他故障排除的实例,通过对比不同处理流程,有的放矢地进行调整,直至完全消除乱码现象。
你所遇到的Linux UTF-8文件编码错误问题,具体是在何种情境下发生的?还请分享你的遭遇。若这篇文章对你有所启发,别忘了点赞并分享给更多人!
