在使用 Linux 系统的过程中,我们时常会遇到文件名包含中文字符时显示为乱码的情况,这无疑给我们的文件搜索和使用带来了诸多不便。这种现象不仅降低了我们的工作效率,还可能引起我们的焦虑情绪。下面,我将对这个现象进行详细的阐述。
问题表现
在 Linux 系统使用过程中,有时会碰到一些文件名由非正常字符组成,看起来像是乱码,但实际上这些文件名是用中文标注的。这种情况我们称之为中文乱码。例如,在图形界面或者使用某些特定工具浏览文件列表时,带有中文字符的文件名可能会显示为乱码。日常工作中,此类情形常令我们对文件的具体内容与意图感到迷茫,因而我们只得逐个查阅文件以核实,这无疑对工作效率造成了不小的负面影响。
此外,在使用命令行界面时,输入含有中文的文件名,常常会遇到一些问题。输入的汉字可能无法正确显示,或者根本无法被系统识别。当尝试执行相关操作命令时,系统会提示找不到文件。这种情况让人感觉像是系统在故意与我们作对,导致使用体验变得非常不顺畅。
产生原因
文件名中出现乱码现象,主要源于编码不兼容的问题。操作系统与软件之间可能存在差异,它们可能会采纳不同的字符编码规范。以Windows系统为例,它通常采用GBK编码,而Linux系统则默认使用UTF-8编码。在 Windows 系统中命名的中文文件,若被复制到 Linux 系统,若该系统未能准确进行编码转换,就可能会引发问题。

Locale环境变量若设置不当,中文文件名的显示效果可能会遭受影响。该变量主要负责设定系统的语言及编码环境,一旦其设置与实际使用的编码不匹配,便可能造成文件名无法准确显示为中文,进而引发乱码现象。
检查方法
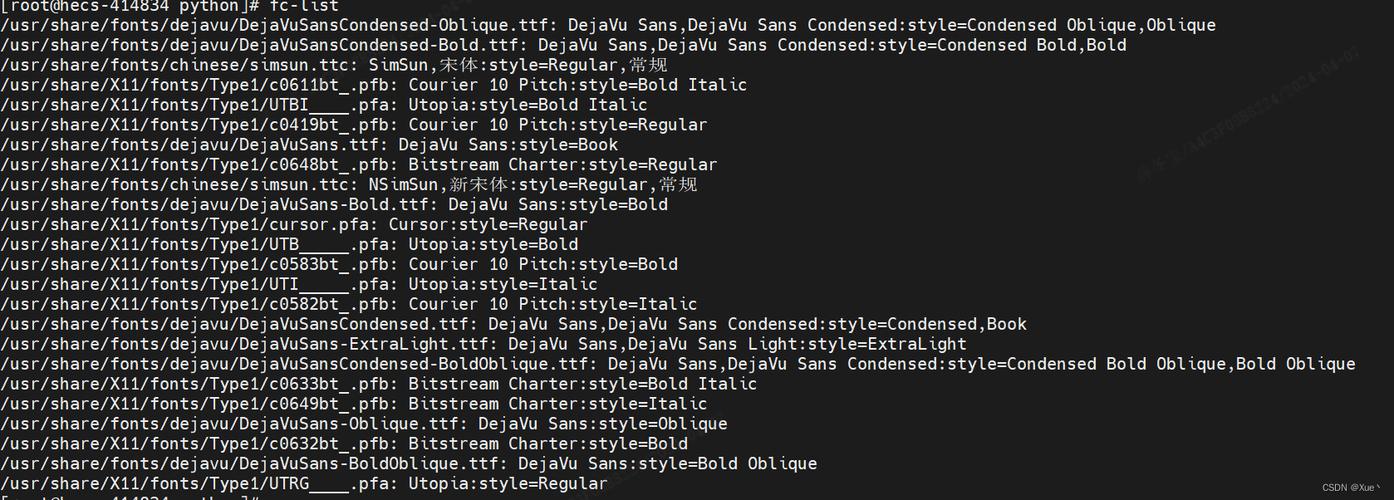
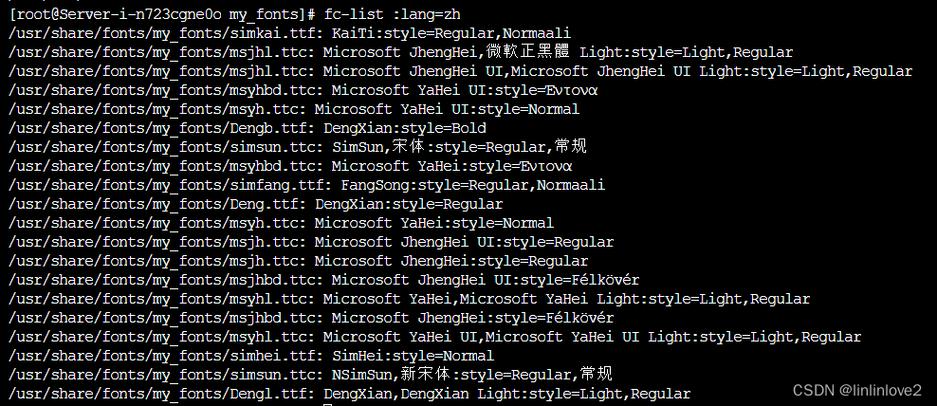
使用file命令可以对文件的编码格式进行识别。只需在命令行中输入“file 文件名”,系统就会自动进行分析,并显示编码的相关信息。如果文件是用某种特定的编码格式创建的,但本系统无法识别这种编码,可能会显示乱码。此外,通过执行“locale”命令linux文件名中文乱码,可以查看系统当前的Locale环境变量配置,以此来确认它是否与所需的编码格式相匹配。如果不一致,文件名显示就会有问题。
在执行命令审查的同时,我们能够利用图形界面工具来辅助进行检验。一些文件管理软件会在状态栏或属性信息中展示文件的编码详情,通过对这些信息的分析,我们能够辨别文件编码是否与系统配置相悖,进而锁定导致中文乱码问题的根源。
解决方法
解决这类问题,调整Locale环境变量是个常见的方法。首先,您需要编辑自己的bash配置文件,即打开那个名为~/.bashrc的文件。然后,在文件里加入两行新的内容:“export LC_ALL = en_US.UTF-8”以及“export LANG = en_US.UTF-8”。编辑完成之后,请记得将文件保存好。此外,为了让这些修改能够真正实施,您需要对整个系统进行重启。此次系统更新引入了新的编码设置,使用了UTF-8编码LINUX社区,这样就能有效解决许多中文文件名出现的乱码困扰了。
文件编码格式是可以进行转换的。举例来说,在命令行中输入“iconv -- f 原始编码 -- t 目标编码 源文件名 -- o 目标文件名”这样的命令,文件编码就会被转换成系统能够识别的格式,从而保证文件名能够正确显示中文字符。
临时方案
系统尚未安排进行大范围调整,所以我们目前能够调整终端的编码格式。可以通过运行“export LANG = zh_CN.UTF-8”这一指令来设定编码,这样在当前的会话中,编码环境就能临时变更,从而让中文文件名得以正常显示。但需注意,这种调整仅在当前会话中有效linux windows,一旦关闭终端后再重新打开linux文件名中文乱码,之前的设置便会失效。
更改文件的英文名称可以有效地防止文件名中出现乱码问题。虽然这样做可能会违反既有的命名规范,但它能确保文件在系统中的顺利运行。这种方法适用于文件数量较少,且对命名规范要求不是很严格的场合。
预防措施
在将文件从其他操作系统转移到 Linux 系统之前,务必要核实文件的编码格式。如果该文件是在 Windows 系统中创建的,最好先将编码转换成 UTF-8 格式,然后再复制到 Linux 系统。这样做可以有效减少乱码问题的发生。设定系统默认的字符编码及地区参数,从根本上消除了因编码不一致导致的文件名中文字符显示混乱的问题。通过采用统一的编码环境,能够有效降低在文件操作过程中对编码的频繁调整和适配的工作量。
面对文件名里出现的乱码困扰,您是否曾尝试过之前提到的解决方法?不妨点个赞,把这篇文章转发出去,同时,您的宝贵意见我们也非常欢迎。
