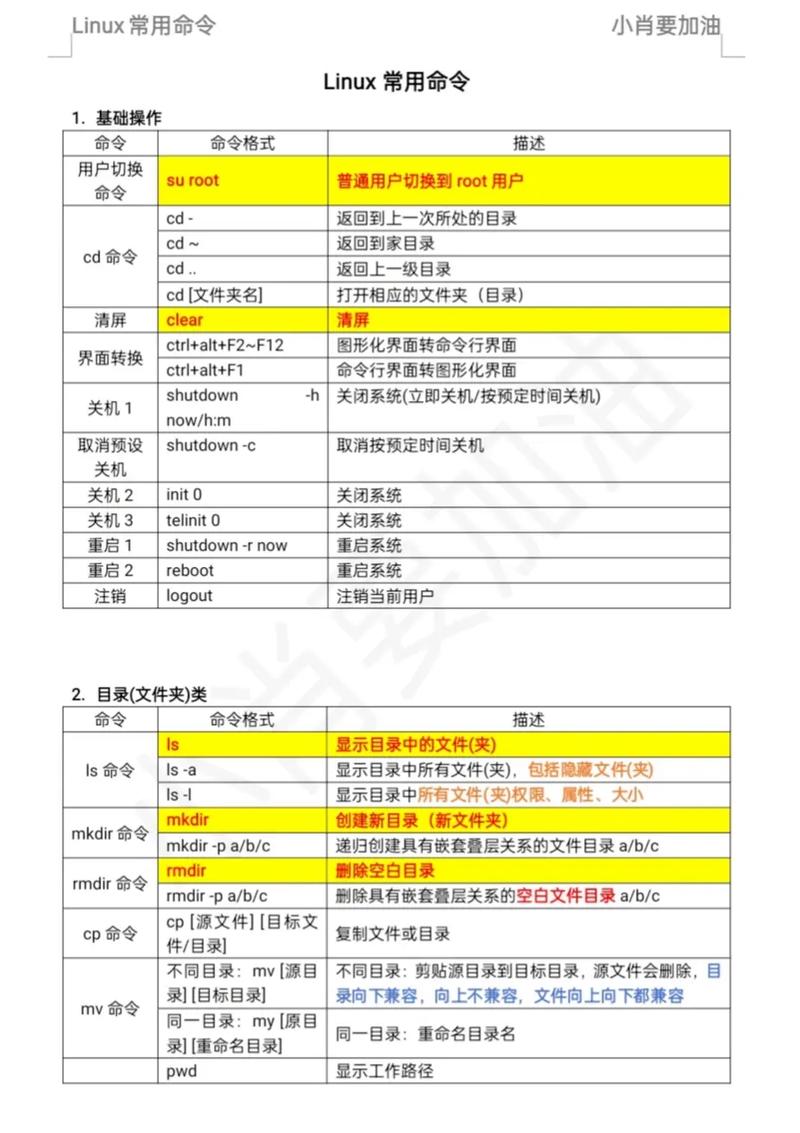
在Linux系统中进行行数统计是日常开发和运维工作中非常常见的需求。无论你是刚接触Linux命令行的新手,还是经验丰富的系统管理员,掌握高效的行数统计方法都能极大提升工作效率。本文将从基础命令到实战技巧,系统性地介绍Linux环境下的各种行数统计解决方案。
怎么用wc命令统计文件行数
wc命令是Linux中最基础的行数统计工具,它的名称来源于”word count”。使用wc -l加上文件名,就能快速得到文件的总行数。例如执行wc -l access.log,系统会返回该日志文件的总行数和文件名。
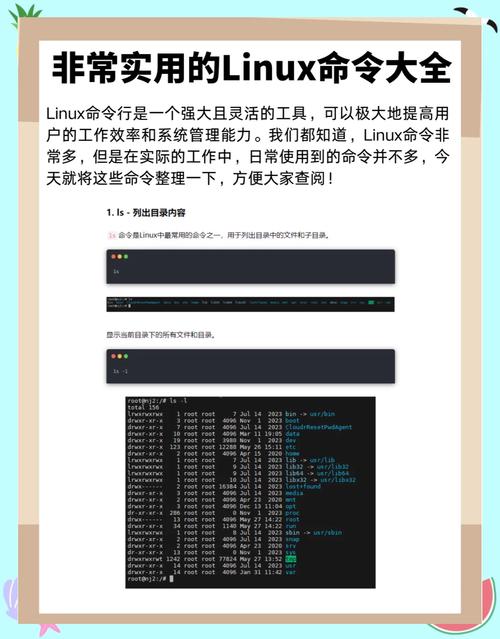
这个命令不仅简单直接,而且执行速度极快,特别适合处理大型文件。如果你只想显示行数而不显示文件名,可以使用wc -l < access.log这样的重定向方式,这在脚本编程中非常实用。
如何统计多个文件的总行数
当需要统计多个文件的行数总和时,wc命令同样能够轻松应对。只需在命令后面列出所有文件名linux怎么查看系统版本,比如wc -l file1.txt file2.txt file3.txt,系统就会分别显示每个文件的行数,并在最后一行给出总计。

这个功能对于统计项目代码量特别有用。结合通配符使用更加高效,例如wc -l <strong>.py可以统计当前目录下所有Python文件的行数,让代码统计工作变得异常简单。
如何统计目录下所有文件行数
统计整个目录的文件行数需要结合find命令来实现。find . -name "</strong>.c" -exec wc -l {} ;这条命令会递归查找当前目录下所有C语言源码文件linux 行数统计,并分别统计每个文件的行数。

如果你想要一个总的行数统计linux 行数统计,可以使用find . -name "<strong>.java" | xargs wc -l。这个组合命令会将找到的所有文件传递给wc命令,最终输出每个文件的详细行数以及总和,非常适合大型项目的代码统计。
怎么用grep统计匹配行数
grep命令的-c选项专门用于统计匹配特定模式的行数。例如grep -c "ERROR" app.log可以快速统计出日志文件中包含”ERROR”关键字的行数,这对于故障排查和日志分析非常有帮助。
结合正则表达式,grep能实现更复杂的行数统计需求。grep -c "^[0-9]" data.txt可以统计所有以数字开头的行数,这种灵活的匹配方式让行数统计不再局限于简单的计数。

如何统计代码文件的有效行数
统计代码有效行数需要过滤掉空行和注释行。组合使用grep的-v选项可以排除特定模式的行,grep -v "^$" main.py | grep -v "^#" | wc -l这条命令先排除空行,再排除以#开头的注释行,最终得到Python代码的有效行数。
对于多种注释格式的代码文件,可以使用扩展正则表达式。grep -v -E "^s</strong>$|^s<strong>//|^s</strong>#" source.c | wc -l能够过滤掉空行、C++风格的//注释和C风格的/*注释,提供更准确的有效代码行数统计。
怎样用awk进行行数统计
awk作为强大的文本处理工具,在行数统计方面也有独特优势。awk '{print NR}' file.txt | tail -n1通过输出行号并取最后一个值,也能得到总行数。这种方法虽然不如wc直接,但在复杂统计场景下更有价值。
awk还能实现条件统计,awk '/ERROR/{count++} END{print count}' logfile统计包含ERROR的行数。更重要的是,awk可以在统计行数的同时进行其他处理,比如awk '{count++; total+=$1} END{print count, total}' data.txt同时统计行数和第一列的总和。
在日常工作中,你会更倾向于使用哪种行数统计方法?欢迎在评论区分享你的经验和技巧,如果觉得本文对你有帮助中国linux,别忘了点赞分享给更多需要的朋友。
