Linux系统中,单词统计的应用广泛,方法多样。这项功能有助于我们把握文本文件的内容和结构,以及进行数据统计。以下将全方位地介绍在Linux环境下进行单词统计的详细情况。
常用工具
Linux系统里,单词统计工具众多,其中wc命令尤为出色。它不仅能统计单词数量,还能提供行数、字节数等详细信息。你只需在终端敲入“wc文件名”,便即刻获得所需数据。再者,grep命令配合相应参数,也能实现特定单词的统计。比如,若要查询文本中某个特定单词出现的频率,只需用grep配合正则表达式操作即可。这样一来,面对大量文本文件,我们也能迅速找到所需信息。
对于某些特殊的文件格式,或者在进行精确的单词统计时,其他工具便能发挥其作用。例如,在处理UTF-8编码且需保留格式的文件时,我们可能需要借助特定的文本处理工具,以确保单词数量的准确统计。
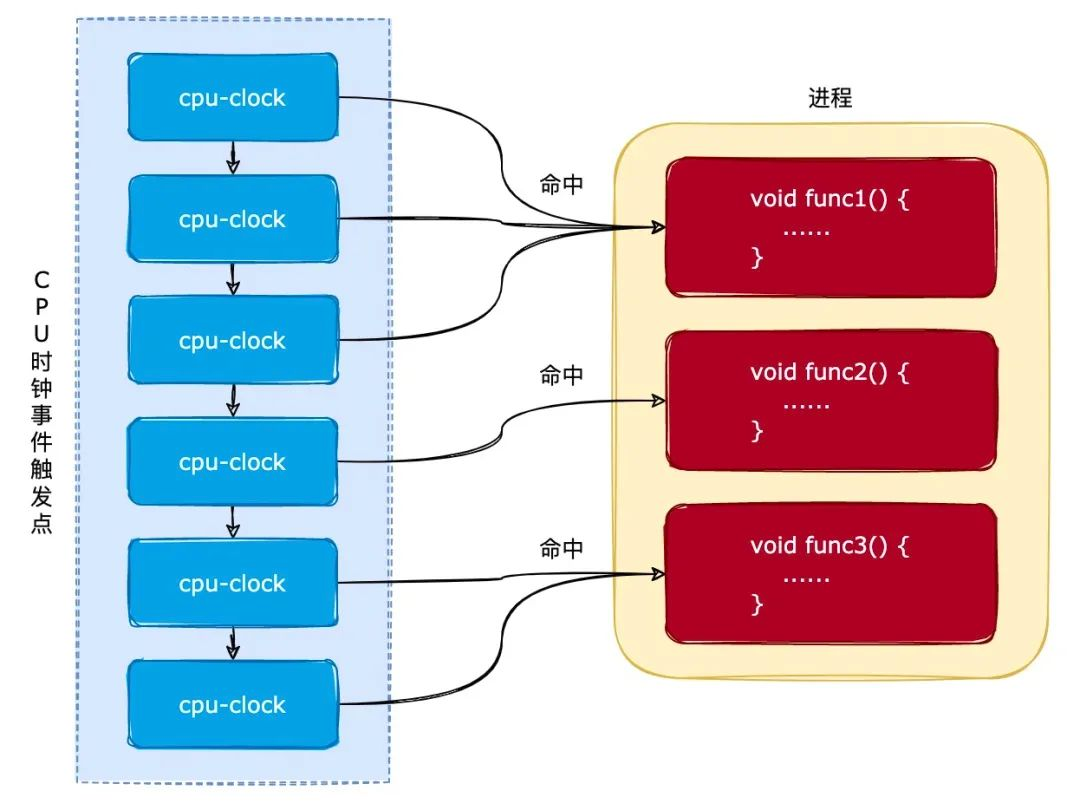
统计原理
Linux进行单词统计的原理是通过读取和分析文本文件中的字符。通常linux系统下载,它会依照既定规则来识别单词的界限。例如,空格和标点符号常被用作分隔单词的标志。然而,也存在一些特殊情况,如缩写词和含有特殊符号的单词。在统计过程中,必须留意这些特殊情况,以防出现误判。
各种工具在识别单词时各有千秋,细微的差别不容忽视。比如,有的工具会将一连串的符号视为单词的一部分,而有的则会将其分开处理。面对不同的需求和对结果的预期linux 单词统计,我们得挑选最合适的工具来进行单词统计。

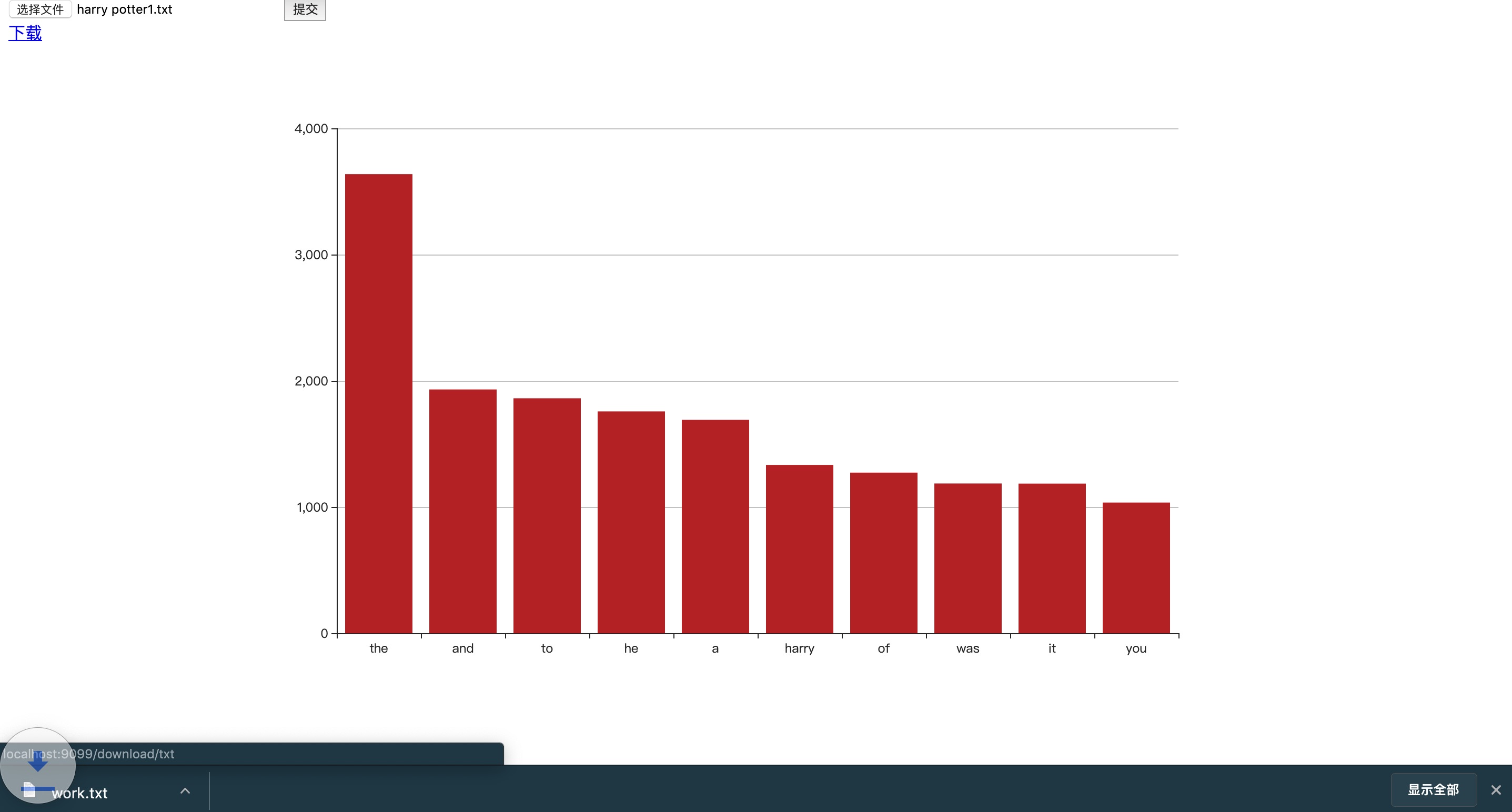
实际案例
在日志分析中,单词统计扮演着关键角色。如果我们手中有一份服务器日志,并希望计算某个特定错误信息中关键词出现的频次,那么我们可以利用wc或grep等工具迅速查明该问题出现的频率。
在文本编辑和校对环节中,这一点同样关键。若需核实长文中某一关键词出现的次数是否得当,我们可以借助Linux下的单词统计工具迅速获得答案,进而更有效地进行文章编辑。
与其他系统比较
与Windows系统不同,Linux在单词统计方面更倾向于采用命令行操作。这种方法对熟练用户而言,能带来更高的效率和便捷性;然而,对于初学者而言,可能需要一定的学习过程才能掌握。
Mac系统虽然属于Unix系统一类,但在单词统计功能的实现上,与Linux系统仍存在一些差异。比如,在某些工具的默认参数设置上,可能会产生不同的统计结果。
优化和难点
为了提升单词统计的效率linux多线程,我们可以考虑运用多进程或多线程技术。特别是在处理大文件时,这样的优化手段能够显著提升统计的速度。
然而,在单词统计的过程中,确实存在一些难题。正如之前提到的,对于那些不规则构成的单词,或者是包含多种语言混合的文本,进行准确的单词统计变得尤为复杂。这要求我们采用特定的算法和相应的处理方法。
总结与展望
Linux的单词统计功能非常强大,不过在使用时确实有几个要点需要留意。根据不同的使用环境,我们得挑选最合适的工具和技巧。
在使用Linux进行单词统计时,你是否遇到过一些棘手的问题?欢迎大家在评论区热烈讨论,积极参与。觉得这篇文章对你有帮助的话,不妨点个赞linux 单词统计,或者分享给更多人。
