其实我们可以通过requests来模拟浏览器发送恳求,并通过解析插口响应的结果来剖析获取想要数据,然而现实中的情况常常要比示例中的要复杂的多,互联网数据是企业特别重要的资源,因而数据保护也十分重要,再加之现今好多网站的数据都是针对每位用户有专门的推荐,因而数据绝大多数情况是动态执行下来的。那些都降低了获取网页数据的复杂程度。
例如像天猫,易迅这种小型互联网公司的网站,虽然我们通过模拟恳求获取到数据,有许多内容都是被加密的,直接剖析恳求反倒不是一种明智的选择。
为了解决这种问题,我们可以直接模拟浏览器运行的方法来实现,做到所见即所得,不管服务网站做了哪些样的加密,只要能在浏览器完整的显示,那就可以获取到相应的数据。这就须要使用一些模拟浏览器的库来完成linux phantomjs 安装,常见的有Seleniumlinux定时关机命令,PyV8,Ghost等。本文将详尽介绍怎样使用Selenium的使用。

Selenium
快速开始
Selenium是一款手动化测试工具,通过它可以驱动浏览器执行特定的动作,如点击、下拉、滑动等等,最重要的是可以获取到页面的数据linux怎么查看系统版本,真正做到了可见即可爬的疗效。因而对于一些动态的数据内容,只要能真实展示在浏览器上,那就可以获取到其数据。
在开始使用Selenium之前,须要做一些后置工作,安装Chrome浏览器,并配置好ChromeDriver,另外还须要安装三方库Selenium。(ChromeDriver须要注意版本须要和Chrome相对应,否则造成死机)。
# 安装Selenium库
pip install Selenium以下是获取豆瓣250影片的一个示例代码
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
# 打开网页
browser.get("https://movie.douban.com/top250")
# 获取节点
els = browser.find_elements(By.CLASS_NAME, "title")
for el in els:
txt = el.text
if not txt.startswith(" /"):
print(txt)
# 肖申克的救赎
# 霸王别姬
# 阿甘正传
# 泰坦尼克号
# 这个杀手不太冷
# 千与千寻
# 美丽人生
# 星际穿越
# 盗梦空间
# 辛德勒的名单
# 楚门的世界
# ......上面代码中,首先须要webdriver.Chrome()方式来获取到浏览器实例,此时会打开一个Chrome浏览器窗口,再通过调用browser.get方式访问目标网址获取网页数据,此时,就可以使用元素查找方式browser.find_elements指定查找类型和class名子来找到对应的元素标签。
获取豆瓣影片
获取浏览器对象及访问页面
其实绝大多数Selenium教程中还会用Chrome,虽然其支持的浏览器特别多包括Firefox,Edge(Edge因为历史缘由存在两个版本,在使用时须要分辨),Android等,甚至包括无界面浏览器PhantomJS。须要注意的是,每种浏览器都须要对应的驱动来支持。
from selenium import webdriver
# 获取Chrome
webdriver.Chrome()
# 获取Chromium内核Edge
webdriver.ChromiumEdge()
# 获取Edge
webdriver.Edge()
# 获取火狐
webdriver.Firefox()
# 获取IE浏览器
webdriver.Ie()在上方获取到浏览器对象后,就可以使用get方式来恳求页面了,只须要传入url地址即可。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.baidu.com")
print(browser.title)
# 百度一下,你就知道如上代码中,就成功访问了百度首页,并获取到了网站的标题。
节点操作
爬虫最重要的目的就是要网站内容,因而节点查找是一个十分重要的功能。Selenium提供了十分丰富的功能,包括可以填充表单,模拟点击等,但这种前提是找到对应的标签。
查找单个节点
Selenium查找节点有多种形式,可以通过id,xpath等等,以下是可选用形式的源码
# 可用的查找方法
class By:
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
# 以class_name查找

browser.find_element(By.CLASS_NAME, "title")
# 获取到的Selenium节点对象
#如上述代码中,使用find_element方式,并指定查找方法和查找的内容,即可返回Selenium的节点对象。须要注意的是,在Selenium原先的旧版本中会有find_element_by_id等方式,这种在新版本都早已被弃用,新版本中只有find_element一个方式拿来返回一个节点标签。
查找多个节点
查找多个节点和一个节点的方式一样,新版本Selenium中统一了查找的方式名使用find_elements来查找多个符合条件的节点。结果会被封装到一个包含WebElement属性的列表中。
els = browser.find_elements(By.CLASS_NAME, "title")
#[.....]节点交互
Selenium不仅可以获取页面节点数据外,还可以模拟浏览器执行一些动作,例如输入数据,清空文字,点击按键等。
from selenium import webdriver
from selenium.webdriver import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get("https://www.baidu.com")
ipt = browser.find_element(by="id", value="kw")
ipt.send_keys("python")
ipt.send_keys(Keys.ENTER)
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, "content_left")))
print(browser.current_url)
print(browser.title)
# https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=python&fenlei=256&rsv_pq=0xb4aec00d00057ed1&rsv_t=46e0VkiflVRYEgv5gB6emF74ekrhKovPPAVF1KVxwU6hiwWQjp2N4DNj6wzk&rqlang=en&rsv_enter=1&rsv_dl=tb&rsv_sug3=6&rsv_sug2=0&rsv_btype=i&inputT=142&rsv_sug4=142
# python_百度搜索如上述代码,使用Selenium完成手动在百度查找Python关键字。首先使用find_element方式找到输入框,再使用send_keys设置输入框关键字,并执行回车动作,使用WebDriverWait等待查询结果完成后结束程序。
获取节点信息
在上面获取到节点后,每位节点信息都被封装到了WebElement类中,因而可以通过这种提供的方式和属性来获取到节点相关信息,如属性,文本等内容。
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get("https://movie.douban.com/top250")
els = browser.find_elements(By.CLASS_NAME, "title")
# 获取节点文本
print(els.text)
# 获取节点class属性值
print(els.get_attribute("class"))
# 获取id值
print(els.id)
# 获取位置信息
print(els.location)
# 获取标签名
print(els.tag_name)
# 获取组件大小
print(els.size)
# 肖申克的救赎
# title
# 27BB114F62D2F51C406DA6460B739476_element_15
# {'x': 164, 'y': 296}
# span
# {'height': 16, 'width': 84}执行JavaScript
Selenium似乎支持诸多的浏览器操作,然而个别情况依旧没有提供,这时,我们就可以使用Selenium执行JavaScript来完成更多的操作。
from selenium import webdriver
browser = webdriver.Chrome()
# 使用JavaScript将页面拉倒最下方
browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")如上述代码中使用execute_script方式执行JavaScript代码,使页面被滑动到最下方。
使用JavaScript拉倒页面最下方
浏览器操作
Selenium提供了浏览器实例的操作方式,借此来提供更多的可操作空间。
浏览器响应等待
在网路访问中,恳求并不是立刻都会有响应,因而在访问网页后就须要等待页面响应完成后,才可以继续获取页面节点的数据。这儿边Selenium在查找DOM时假如没有找到对应节点,还会继续等待,当超时后都会抛出异常,然而程序默认时间为0,因而我们须要显示的更改一下等待时长。
browser.implicitly_wait(10)如上使用implicitly_wait方式设置了固定的时长10秒。
上面设置形式存在一个缺点,就是设置时间是一个固定值,这个时间都会很不容易把握。庆幸,还有一种方法来设置。代码如下:
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(browser, 10)
wait.until(EC.presence_of_element_located((By.ID, "content_left")))在上面代码中,我们初始化了一个WebDriverWait对象,并指定了最长等待时间,之后调用until方式,参数是一个条件
presence_of_element_locatedlinux phantomjs 安装,表示当节点中出现指定的内容时条件创立。
网页前进和退后
Selenium还可以模拟浏览器执行前进和退后的功能,这儿须要调用back和forward两个方式。
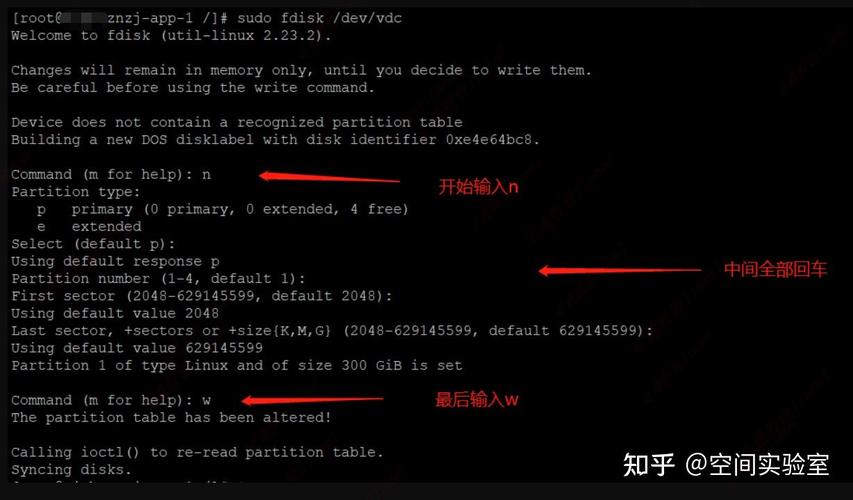
browser.get("https://www.baidu.com")
browser.get("https://youdao.com/")
browser.get("https://cn.bing.com")
# 网页后退
browser.back()
time.sleep(2)
# 网页前进
browser.forward()
time.sleep(2)须要注意的是,前进和退后只能执行一步,倘若有多步,则须要多次调用。
前进和退后
Cookies处理
Cookies作为网站的重要内容,Selenium也提供了完全的支持,包括对Cookies的获取,新增,删掉等操作
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.baidu.com")
# 获取所有的cookies
print(browser.get_cookies())
# 设置指定的cookies内容
browser.add_cookie({"name": "name", "value": "value"})
# 删除所有的cookies
browser.delete_all_cookies()
# [
# {'domain': '.baidu.com',
# 'expiry': 1737617054,
# 'httpOnly': False,
# 'name': 'ZFY',
# 'path': '/',
# 'sameSite': 'None',
# 'secure': True,
# 'value': 'mnlDLVQ3mvzbCJmjtPbxdVNxuFCaIaL6DLYdZZbtkR0:C'},
# {'domain': '.baidu.com',
# 'expiry': 1706167453,
# 'httpOnly': False,
# 'name': 'BA_HECTOR',
# 'path': '/',
# 'sameSite': 'Lax',
# 'secure': False,
# 'value': '2t81012h20ah8565ag208l84gsu4351ir1eou1t'},
# .....
# ]浏览器标签切换
假如打开了多个浏览器选项卡,Selenium也可以操作不同的选项卡。
import time
from selenium import webdriver
# 获取浏览器实例
browser = webdriver.Chrome()
# 访问百度
browser.get("https://www.baidu.com")
# 新打开一个标签页
browser.execute_script("window.open()")
time.sleep(2)
# 切换标签页
browser.switch_to.window(browser.window_handles[1])
# 打开有道搜索
browser.get("https://youdao.com/")
time.sleep(2)
# 重新切换回百度标签页
browser.switch_to.window(browser.window_handles[0])
切换标签
#python#
