Memwatch 是一款轻量级的内存调试工具,专门用于检测 C/C++ 程序中的内存泄漏和内存错误。在 Linux 环境下开发嵌入式或服务器应用时,内存问题往往隐蔽且难以复现,而 Memwatch 只需包含一个头文件即可工作,无需修改系统库,非常适合快速集成到现有项目中。本文将从实际使用角度出发,详细讲解 Memwatch 的安装配置、典型用法和常见问题,帮助开发者高效排查内存隐患。
Memwatch 怎么安装到 Linux 系统
Memwatch 本身不需要传统意义上的安装,它由两个文件组成:memwatch.h 和 memwatch.c。开发者可以从官方网站或开源代码仓库下载这两个文件,直接放入项目的源代码目录中。在编译时,只需在源文件中包含 memwatch.h,并将 memwatch.c 加入编译列表即可。例如使用 gcc 编译时,加上 -DMEMWATCH 和 -DMW_STDIO 两个宏定义,就能启用 Memwatch 的全部功能。对于交叉编译环境,同样适用这种零依赖的集成方式。
如果项目使用 Makefile 管理,可以在编译参数中添加 -DMEMWATCH,并在链接时指定 memwatch.o 对象文件。另外,Memwatch 默认会调用标准库的 printf 输出日志,若需要重定向输出或禁用某些检查,可以通过修改 memwatch.h 中的预定义宏来实现。对于大型项目,建议将 memwatch.c 编译成静态库,方便多模块共享。整个集成过程不超过五分钟,非常适合快速定位内存泄漏问题。
memwatch 检测内存泄漏的基本步骤
使用 Memwatch 检测内存泄漏分为三步:包含头文件、调用追踪宏、分析输出日志。首先在所有需要监控的源文件顶部添加 #include "memwatch.h",并确保该头文件先于其他系统头文件被包含。然后在程序入口处调用 mwInit() 初始化 Memwatch 内部数据结构,在程序退出前调用 mwTerm() 打印内存报告。对于 C++ 程序,需要将 new 和 delete 操作符重载,或者直接使用 mwMalloc、mwFree 等宏替代标准内存函数。

编译运行程序后,Memwatch 会生成一个名为 memwatch.log 的文件,里面记录了所有未释放的内存块信息linux中文乱码,包括分配时的文件名、行号和内存大小。例如日志中会显示 “leaked memory at line 128 (file main.c) size 32 bytes”。通过分析这些日志,开发者可以快速定位到具体代码行。如果程序正常结束但仍有内存未释放,Memwatch 会自动报告泄漏总量和每处泄漏的调用栈。建议在测试环境中反复运行程序,结合单元测试触发所有代码路径,确保检测覆盖全面。
memwatch 如何处理内存越界写问题
内存越界写是比泄漏更危险的错误,Memwatch 通过在每个分配的内存块前后添加“防护区”来检测这类问题。当调用 malloc 或 new 分配内存时,Memwatch 会额外分配若干个填充字节,并写入特定模式的数据。在调用 free 或 delete 释放内存时,Memwatch 会检查这些填充字节是否被修改。如果发现被改动,说明程序发生了缓冲区溢出或下溢,日志中会明确提示 “write overrun” 或 “write underrun”,并给出分配位置和越界偏移量。
为了更精准地捕获越界错误,开发者可以在编译时启用 -DMW_VERBOSE 宏,Memwatch 会在每次内存操作后主动校验防护区,而不是等到释放时才检查。这种方法虽然会略微降低性能,但在调试阶段非常有效。另外,Memwatch 还能检测到对已释放内存的读写操作,这类错误通常表现为访问野指针。通过分析日志中的 “free error” 信息,可以追踪到错误访问的原始分配位置。对于多线程程序,需要注意 Memwatch 不是线程安全的,需要自己加锁保护。
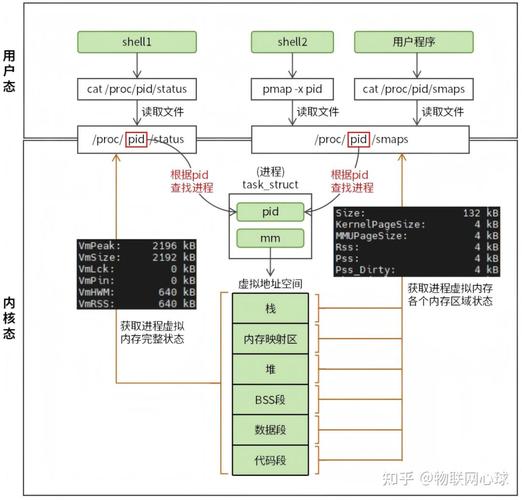
memwatch 日志文件在哪里查看
Memwatch 默认在当前工作目录下生成 memwatch.log 文件。如果程序通过 chdir 切换了工作目录,或者以守护进程方式运行,日志可能会写入其他位置。为了方便管理,可以在调用 mwInit() 之前调用 mwSetLogFile("自定义路径/memwatch.log") 来指定绝对路径。在嵌入式 Linux 环境下,如果没有文件系统,还可以通过 mwSetOutputFunction 将日志重定向到串口或网络输出。
查看日志时,建议使用 grep -E "leaked|overrun|underrun|free error" memwatch.log 过滤关键错误。正常退出且无内存问题的日志末尾会显示 “Memory statistics: 0 bytes in 0 blocks” 和 “No memory leaks detected”。如果程序崩溃来不及输出日志,可以在信号处理函数中调用 mwTerm() 强制刷新。对于长时间运行的服务程序,可以定期调用 mwStatistics() 打印当前内存状态,观察内存增长趋势。另外,Memwatch 还支持生成内存分配的调用计数图,便于分析热点分配。
memwatch 常见错误码含义及解决
Memwatch 在日志中使用数字错误码标识问题类型,常见的有 1、2、3 和 5。错误码 1 表示 “free error”,通常是对同一块内存重复释放,或者释放了未从 Memwatch 分配的内存。解决方法是在释放后将指针置为 NULL,并确保每次分配和释放配对。错误码 2 表示 “write overrun”,即向分配的内存块之后写入了数据,需要检查数组下标是否越界,或字符串拷贝是否超出了缓冲区长度。
错误码 3 表示 “write underrun”,发生在向内存块之前写入数据,常见于通过递减指针访问负偏移。错误码 5 表示 “allocation error”,通常是 malloc 失败导致返回 NULL,但程序未做空指针判断就继续使用。解决方法是增加内存分配失败的处理逻辑。此外,Memwatch 还会报告 “invalid pointer” 错误,说明传递给了 free 的地址不属于任何活跃分配块。遇到这些错误时,应结合日志中的文件和行号,重点审查对应代码的内存操作。建议使用 valgrind 与 Memwatch 交叉验证,确保问题彻底修复。
memwatch 和其他内存检测工具对比

相比 Valgrind,Memwatch 的优势在于轻量和跨平台。Valgrind 会模拟 CPU 执行指令,导致程序运行速度下降 20 到 50 倍,而 Memwatch 仅替换内存分配函数,性能损耗通常不超过 30%。对于资源受限的嵌入式系统memwatch linux 使用,Valgrind 可能无法运行,而 Memwatch 只需要几百 KB 内存即可工作。但 Memwatch 的缺点是检测能力有限,无法发现未初始化的内存读取,也不能追踪到深层函数调用的完整堆栈。
与 mtrace(glibc 自带)相比,Memwatch 提供了越界检测和错误码分类,功能更丰富。mtrace 只记录分配和释放的对应关系,对于越界访问无能为力。另一方面,Memwatch 不支持多线程环境下的自动保护,而 Valgrind 的 helgrind 工具可以检测数据竞争。因此在实际开发中memwatch linux 使用,建议在调试阶段优先使用 Valgrind 进行全量检查,在持续集成或嵌入式测试中使用 Memwatch 做快速回归。两者互补使用雨林木风linux,能最大化内存问题的发现效率。
你在使用 Memwatch 时遇到过最隐蔽的内存错误是什么?欢迎在评论区分享你的排查经验,记得点赞收藏,让更多 Linux 开发者少走弯路。
