本文作者按照自己的认知,讨论了人们为提升性能作出的种种努力,包括硬件层面的CPU、RAM、磁盘,操作系统层面的并发、并行、事件驱动,软件层面的多进程、多线程,网路层面的分布式等。
本文共分为七个部份:
天才冯·诺依曼与冯·诺依曼困局
分支预测、流水线与多核CPU
通用电子计算机的白斑:风波驱动
Unix进程模型的局限
DPDK、SDN与大页显存
现代计算机最亲昵的伙伴:局部性与豁达
分布式估算、超级计算机与神经网路共同的困局
(一)天才冯·诺依曼与冯·诺依曼困局
电子计算机与信息技术是近来几六年人类科技发展最快的领域,无可争议地改变了每位人的生活:从生活形式到战争形式,从烹调方法到国家整治方法,都被计算机和信息技术彻底地改变了。假如说核装备彻底改变了国与国之间交往的模式,这么计算机与信息技术则彻底改变了人类这个物种本身,人类的进化也步入了一个新的阶段。
简单地说,生物进化之前还有物理进化。但是细胞一经诞生,中心法则的分子进化就趋向停滞了:38亿年来,中心法则再没有新的变动,所有的蛋白质都由20种标准多肽连成,连核苷酸与多肽对应关系也沿用至今,所有现代生物共用一套标准遗传密码。正如中心法则是物理进化的产物,却由于开创了生物进化而停止了物理进化,人类是生物进化的产物,也由于开创了文化进化和技术进化而停止了生物进化——进化早已走上了更高的维度。——《进化的阶次|混乱博物馆》
本文目标
本文的目标是在我有限的认知范围内,讨论一下人们为了提升性能作出的种种努力,这儿面包含硬件层面的CPU、RAM、磁盘,操作系统层面的并发、并行、事件驱动,软件层面的多进程、多线程,网路层面的分布式,等等等等。事实上,上述名词并不局限于某一个层面,计算机从CPU内的门电路到显示器上浏览器中的某行字,是层层协作才得以实现的;计算机科学中的许多概念,都跨越了层级:风波驱动就是CPU和操作系统协作完成的。
天才冯·诺依曼
冯·诺依曼1903年12月28日出生于奥匈帝国伊斯坦布尔,1957年2月8日卒于英国,终年53岁。在他短暂的一生中,他取得了巨大的成就,远不止于世人熟知的「冯·诺依曼构架」。
约翰·冯·诺伊曼,出生于德国的英国籍犹太人数学家,现代电子计算机与博弈论的重要创始人,在泛函剖析、遍历理论、几何学、拓扑学和数值剖析等诸多物理领域及计算机学、量子热学和经济学中都有重大贡献。——约翰·冯·诺伊曼的维基百科
不仅对计算机科学的贡献,他还有一个称号不被大众所熟知:「博弈论之父」。博弈论被觉得是20世纪经济学最伟大的成果之一。(说到博弈论,我相信大多数人第一个想到的肯定跟我一样,那就是「纳什均衡」)
冯·诺依曼构架
冯·诺依曼因为在曼哈顿工程中须要大量的运算,因而使用了当时最先进的两台计算机MarkI和ENIAC,在使用MarkI和ENIAC的过程中,他意识到了储存程序的重要性,因而提出了储存程序逻辑构架。
「冯·诺依曼构架」定义如下:
优势
冯·诺依曼构架第一次将储存器和运算器分开,指令和数据均放置于储存器中,为计算机的通用性奠定了基础。似乎在规范中估算单元依旧是核心,但冯·诺依曼构架事实上造成了以储存器为核心的现代计算机的诞生。
注:请诸位在心中明晰一件事情:储存器指的是显存,即RAM。c盘理论上属于输入输出设备。
该构架的另一项重要贡献是用二补码代替十补码,急剧减少了运算电路的复杂度。这为晶体管时代超大规模集成电路的诞生提供了最重要的基础,让我们实现了明天手指上的AppleWatch运算性能远超初期小型计算机的创举,这也是摩尔定理得以实现的基础。
冯·诺伊曼困局
冯·诺依曼构架为计算机大提速铺平了公路,却也埋下了一个隐患:在显存容量指数级提高之后,CPU和显存之间的数据传输带宽成为了困局。
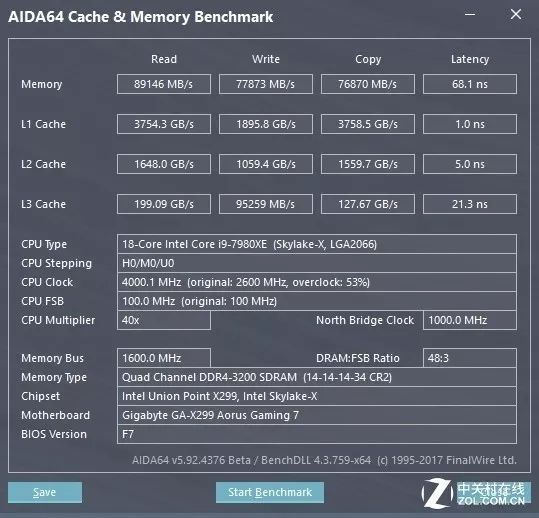
上图是i9-7980XE18核36线程的民用最强CPU,其配合开核过的DDR43200MHz的显存,测试出的显存读取速率为90GB/S。看上去很快了是不是?瞧瞧图中的L1Cache,3.7TB/S。
我们再来算算时间。这颗CPU最大主频4.4GHz,就是说CPU执行一个指令须要的时间是0.7273秒,即0.22ns(毫秒),而显存的延后是68.1ns。换句话说,只要去显存里取一个字节,就须要CPU等待300个周期,何其的浪费CPU的时间啊。
CPUL1L2L3五级缓存是使用和CPU同样的14纳米工艺制造的硅半导体,每一个bit都使用六个场效应管(浅显解释成二极管)构成,成本昂贵且十分占用CPU核心面积,故不能弄成很大容量。
除此之外,L1L2L3五级缓存对计算机速率的提高来始于计算机显存的「局部性」,相关内容我们以后会专门讨论。
(二)分支预测、流水线与多核CPU
CPU硬件为了提升性能,逐渐发展出了指令流水线(分支预测)和多核CPU,本文我们就将简单地阐述一下它们的原理和疗效。
指令流水线
在一台纯粹的图灵机中,指令是一个一个次序执行的。而现实世界的通用计算机所用的好多基础算法都是可以并行的,比如加法器和乘法器,它们可以很容易地被切分成可以同时运行的多个指令,这样就可以急剧提高性能。
指令流水线,说白了就是CPU电路层面的并发。
IntelCorei7自SandyBridge(2010)构架以来始终都是14级流水线设计。基于CedarMill构架的最后一代奔腾4,在2006年就拥有3.8GHz的超高频度,却由于其历时31级的流水线而成了为样子货,被AMD1GHz的芯片按在地上磨擦。
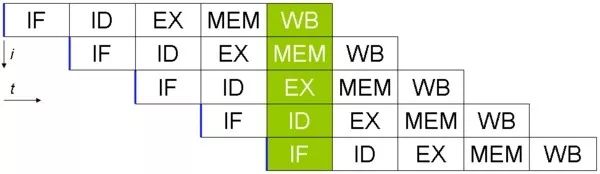
RISC机器的五层流水线示意图
右图形象地展示了流水线式怎么提升性能的。
缺点
指令流水线通过硬件层面的并发来提升性能,却也带来了一些难以避开的缺点。
分支预测
指令产生流水线之后,就须要一种高效的调控来保证硬件层面并发的疗效:最佳情况是每条流水线里的十几个指令都是正确的,这样完全不浪费时钟周期。而分支预测就是干这个的:
分支预测器猜想条件表达式两路分支中哪一路最可能发生,之后推断执行这一路的指令,来防止流水线停顿导致的时间浪费。并且,假如后来发觉分支预测错误,这么流水线中推断执行的这些中间结果全部舍弃,重新获取正确的分支路线上的指令开始执行,这就带来了十几个时钟周期的延迟,这个时侯,这个CPU核心就是完全在浪费时间。

辛运的是,当下的主流CPU在现代编译器的配合下,把这项工作做得越来越好了。
还记得那种让IntelCPU性能跌30%的漏洞补丁吗,那种漏洞就是CPU设计的时侯,分支预测设计的不健全引起的。
多核CPU
多核CPU的每一个核心拥有自己独立的运算单元、寄存器、一级缓存、二级缓存,所有核心共用同一条显存总线,同一段显存。
多核CPU的出现,标志着人类的集成电路工艺遇见了一个严苛的困局,无法再大规模提高单核性能,只能使用多个核心来聊以手淫。实际上,多核CPU性能的提高非常有限,远不如降低一点点单核频度提高的性能多。
优势
多核CPU的优势很显著,就是可以并行地执行多个图灵机,可以显而易见地提高性能。只不过因为使用同一条显存总线,实际带来的疗效有限,而且须要操作系统和编译器的密切配合才行。
正题:AMD64技术可以运行32位的操作系统和应用程序,所用的方式是仍然使用32显存的显存总线,每估算一次要取两次显存,性能提高也十分有限,不过用处就是可以使用小于4GB的显存了。你们应当都没忘掉第一篇文章中提及的冯·诺依曼构架拥有CPU和显存通讯带宽不足的弱点。(注:AMD64技术是和Intel交叉授权的专利,i7也是如此设计的)
劣势
多核CPU劣势虽然愈加显著,而且人类也没有办法,谁不想用20GHz的CPU呢,谁想用这八核的i7呀。
超线程技术
Intel的超线程技术是将CPU核心内部再分出两个逻辑核心,只降低了5%的裸面积,就带来了15%~30%的性能提高。
追忆过去
Intel肯定追忆摩尔定理提出时侯的黄金年代,只借助工艺的进步,才能一三年就性能翻倍。AMD肯定追忆K8的黄金一代,1G战4G,靠的就是把显存控制器从南桥芯片移到CPU内部,提高了CPU和显存的通讯效率,自然性能倍增。而昨天,人类的技术早已抵达了一个困局,只能通过不断的提高CPU和操作系统的复杂度来获得微弱的性能提高,呜呼叹惜。
不过我们也不能舍弃希望,AMDRXVAGA64主板拥有2048位的内存显存,理论极限还是很惊悚的,这可能就是未来显存的发展方向。
(三)通用电子计算机的白斑:风波驱动
Event-Driven(风波驱动)这个词这几年随着Node.js®的大热也成了一个热词,虽然早已成了「高性能」的代名词,殊不知风波驱动虽然是通用计算机的疤痕,是一种与生俱来的能力。本文我们就要一起了解一下风波驱动的价值和本质。
通用电子计算机中的风波驱动
首先我们定义当下最火的x86PC机为典型的通用电子计算机:可以写文章,可以打游戏,可以上网聊天,可以读U盘,可以复印,可以设计三维模型,可以编辑渲染视频,可以作路由器,还可以控制巨大的工业机器。这么,这些计算机的风波驱动能力就很容易理解了:
假定Chrome正在播放Youtube视频,你按下了按键上的空格键,视频暂停了。这个操作就是风波驱动:计算机获得了你单击空格的风波,于是把视频暂停了。
假定你正在跟人聊QQ,他人发了一段话给你,计算机获得了网路传输的风波,于是将信息提取下来显示到了屏幕上linux系统官网,这也是风波驱动。
风波驱动的实现方法
风波驱动本质是由CPU提供的,由于CPU作为控制器+运算器,他须要随时响应意外风波,比如前面事例中的按键和网路。

CPU对于意外风波的响应是借助ExceptionControlFlow(异常控制流)来实现的。
强悍的异常控制流
异常控制流是CPU的核心功能,它是以下听上去就很牛批的功能的基础:
时间片
CPU时间片的分配也是借助异常控制流来实现的,它让多个进程在宏观上在同一个CPU核心上同时运行,而我们都晓得在微观上在任一个时刻,每一个CPU核心都只能运行一条指令。
虚拟显存
这儿的虚拟显存不是Windows虚拟显存,是Linux虚拟显存,即逻辑显存。
逻辑显存是用一段显存和一段c盘上的储存空间放到一起组成一个逻辑显存空间,对外仍然表现为「线性链表显存空间」。逻辑显存引出了现代计算机的一个重要的性能观念:
显存局部性天然的让相邻指令须要读写的显存空间也相邻,于是可以把一个进程的显存放在c盘上,再把一小部份的「热数据」放到显存中,让其作为c盘的缓存,这样可以在增加极少性能的情况下,急剧提高计算机能同时运行的进程的数目,急剧提高性能。
虚拟显存的本质虽然是使用缓存+豁达的手段提高计算机的性能。
系统调用
系统调用是进程向操作系统索要资源的通道,这也是借助异常控制流实现的。
硬件中断
鼠标点击、鼠标联通、网络接收到数据、麦克风有声音输入、插入U盘这种操作全部须要CPU暂时停下手头的工作,来作出响应。
进程、线程
进程的创建、管理和销毁全部都是基于异常控制流实现的,其生命周期的钩子函数也是操作系统依赖异常控制流实现的。线程在Linux上和进程几乎没有功能上的区别。
编程语言中的trycatch
C++编译成的二补码程序,其异常控制句子是直接基于异常控制流的。Java这些硬虚拟机语言,PHP这些软虚拟机语言,其异常控制流的一部份也是有最底层的异常控制流提供的,另一部份可以由逻辑判定来实现。
基于异常控制流的风波驱动
虽然如今人们在谈论的风波驱动,是Linuxkernel提供的epoll,是2002年10月18号伴随着kernel2.5.44发布的,是Linux首次将操作系统中的I/O风波的异常控制流曝露给了进程,实现了本文开头提及的Event-Driven(风波驱动)。
Kqueue
FreeBSD4.1版本于2000年发布,起携带的Kqueue是BSD系统中风波驱动的API提供者。BSD系统现在早已满地开花,从macOS到iOS,从watchOS到PS4游戏机,都遭到了Kqueue的蒙荫。
epoll是哪些

操作系统本身就是风波驱动的,所以epoll并不是哪些新发明,而只是把原本不给用户空间用的api曝露在了用户空间而已。
epoll做了哪些
网路IO是一种纯异步的IO模型,所以Nginx和Node.js®都基于epoll实现了完全的风波驱动,获得了相比于select/poll巨量的性能提高。而c盘IO就没有那么辛运了,由于c盘本身也是单体阻塞资源:即有进程在写c盘的时侯,其他写入恳求只能等待计算linux网卡瓶颈,就是天王老娘来了也不行,c盘做不到呀。所以c盘IO是基于epoll实现的非阻塞IO,并且其底层仍然是异步阻塞,虽然这样,性能也早已十足了。Node.js的c盘IO性能远超其他解释型语言,过去几年在web前端强占了一些对c盘IO要求高的领域。
(四)Unix进程模型的局限
Unix系统1969年诞生于AT&T旗下的贝尔实验室。1971年,KenThompson(Unix之父)和DennisRitchie(C语言之父)共同发明了C语言,并在1973年用C语言重画了Unix。
Unix自诞生起就是多用户、多任务的分时操作系统,其引入的「进程」概念是计算机科学中最成功的概念之一,几乎所有现代操作系统都是这一概念的获益者。并且进程也有局限,因为AT&T是做电话交换起家,所以Unix进程在设计之初就是延续的电话交换这个业务需求:保证电话交换的效率,就够了。
1984年,RichardStallman发起了GNU项目,目标是创建一个完全自由且向上兼容Unix的操作系统。以后LinusTorvalds与1991年发布了Linux内核,和GNU结合在了一起产生了GNU/Linux这个当下最成功的开源操作系统。所以Redhat、CentOS、Ubuntu这种如雷贯耳的Linux服务器操作系统,她们的显存模型也是高度类似Unix的。
Unix进程模型介绍
进程是操作系统提供的一种具象,每位进程在自己看来都是一个独立的图灵机:独占CPU核心,一个一个地运行指令,读写显存。进程是计算机科学中最重要的概念之一,是进程使多用户、多任务成为了可能。
上下文切换
操作系统使用上下文切换让一个CPU核心上可以同时运行多个进程:在宏观时间尺度,比如5秒内,一台笔记本的用户会觉得他的桌面进程、音乐播放进程、鼠标响应进程、浏览器进程是在同时运行的。
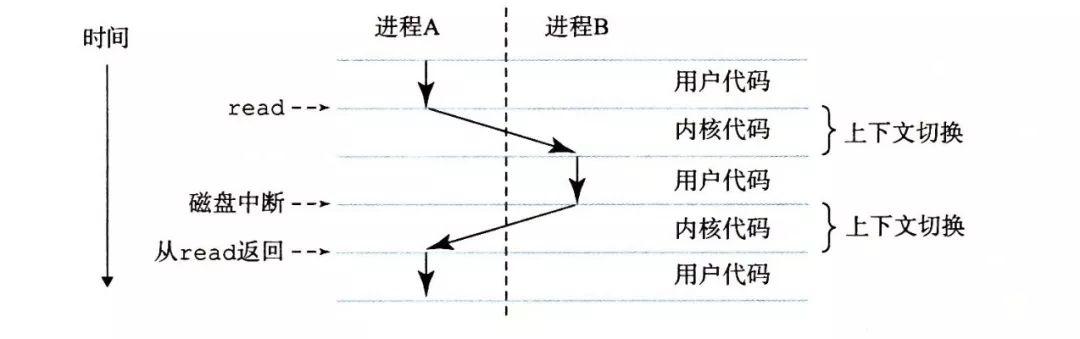
图片来自《CS:APP》
上下文切换的过程
以下就是Linux上下文切换的过程:
假定正在运行网易云音乐进程,你忽然想搜歌,假定焦点早已坐落搜索框内。
名词解释
Unix进程模型的局限
Unix进程模型非常的清晰,上下文切换使用了一个特别简单的操作就实现了多个进程的宏观同时运行,是一个伟大的杰作。并且它却存在着一个潜在的缺陷,这个缺陷在Unix诞生数六年以后才逐渐浮出了海面。
致命的显存
进程切换过程中须要分别写、读一次显存,这个操作在Unix刚发明的时侯没有发觉有哪些性能问题百度网盘LINUX,并且CPU裹挟着摩尔定理一路飞奔,2000年,AMD领先Intel七天发布了第一款1GHz的微处理器「AMDAthlon1GHz」,此时一个指令的执行时间早已低到了1ns,而其显存延后高达60ns,这造成了一个曾经不曾出现的问题:
上下文切换读写显存的时间成了整个系统的性能困局。
软件定义一切
我们将在下一篇文章阐述SDN(软件定义网路),在这儿我们先来看一下「软件定义一切」这个概念。当下,除了有软件定义网路,还有软件定义储存,甚至出现了软件定义基础构架(这不就是云估算嘛)。是哪些造成了软件越来越强势,开始倾入过去只有专业的硬件设备能够提供的高性能高稳定性服务呢?我觉得,就是通用计算机的发展造成的,准确地说,是CPU和网路的发展造成的。

当前的民用顶尖CPU的性能早已爆表,由于规模巨大,所以其价钱也要明显高于同性能的专用处理器:自建40G软路由的价钱大概是40G专用路由价钱的二非常之一。
(五)DPDK、SDN与大页显存
上文我们说到,现今的x86通用微处理器早已拥有了非常强悍的性能,得益于其庞大的销量,让它的价钱和专用CPU比也有着巨大的优势,于是,软件定义一切诞生了!
软路由
说到软路由,好多人都漏出了会心的笑容,由于其拥有低廉的价钱、超多的功能、够用的性能和科学上网能力。现今网上能买到的软路由计算linux网卡瓶颈,其本质就是一个x86PC加上多个网口,大多是基于Linux或BSD内核,使用Intel高端被动散热CPU构建出的百兆路由器,几百块能够实现百兆的性能,最重要的是拥有QOS、多路拔号、负载均衡、防火墙、VPN组网、科学上网等强悍功能,传统路由器摒弃科学上网不谈,其他功能也不是几百块就搞得定的。
软路由的弱点
软路由实惠,功能强悍,而且也有弱点。它最大的弱点虽然是性能:传统*UNIX网路栈的性能实在是不高。
软路由的NAT延后比硬路由显著更大,但是几百块的软路由NAT性能也不够,挪到百兆都难,而几百块的硬路由挪到百兆很容易。那如何办呢?改操作系统啊。
SDN
软件定义网路,其本质就是使用计算机科学中最常用的「虚拟机」构想,将传统由硬件实现的交换、网关、路由、NAT等网路流量控制流程交由软件来统一管理:可以实现硬件不动,网路结构顿时变化,防止了传统的停机维护调试的苦恼,也为大规模公有云估算铺平了公路。
虚拟机
虚拟机的思想自底向下完整地贯串了计算机的每一个部份,硬件层有三个场效应管虚拟出的SRAM、多个显存芯片虚拟出的一个「线性链表显存」,软件层有jvm虚拟机,PHP虚拟机(类库)。自然而然的,当网路成为了更大规模估算的困局的时侯,人们都会想,为何网路不能虚拟呢?
OpenFlow
最开始,SDN还是基于硬件来施行的。Facebook和Google使用的都是OpenFlow合同,作用在数据链路层(使用MAC地址通讯的那一层,也就是普通交换机工作的那一层),它可以统一管理所有网段、交换等设备,让网路构架实时地作出改变,这对这些规模的公司所拥有的巨大的数据中心特别重要。
DPDK
DPDK是SDN更前沿的方向:使用x86通用CPU实现10Gbps甚至40Gbps的超高速网段(路由器)。
DPDK是哪些
IntelDPDK全称为IntelDataPlaneDevelopmentKit,译音为「英特尔数据平面开发工具集」,它可以甩掉*UNIX网路数据包处理机制的局限,实现超高速的网路包处理。

DPDK的价值
当下,一台40G核心网管路由器动辄数十万,而40G网卡也不会超过一万块,而一颗性能足够的IntelCPU也只须要几万块,软路由的性价比优势是巨大的。
实际上,阿里云和腾讯云也早已基于DPDK研制出了自用的SDN,早已创造了很大的经济价值。
如何做到的?
