身为服务器领域的从业者,我深切认识到Linux系统于服务器环境里的核心地位,它不但是互联网基础设施的基石,更是企业数字化转型的关键支撑,多年同各类服务器打交道的经验使我明白,掌握Linux系统的选型、部署、维护以及优化,为每一位服务器管理人员必须具备的基本功,下文我将自实际工作角度,分享几个关键方面的经验。
服务器为什么要选择linux系统
在稳定性层面予以考量,Linux系统所拥有的开源特质以及模块化架构设计,致使其于服务器长时间运转期间展现出卓越表现。内核的健壮程度久经全球开发者群体的持续验证,能够切实防止因系统层面问题引发的服务中断情况。相较于其他系统而言,Linux在内存管理、进程调度等领域更为高效,格外契合7×24小时不间断的业务情形。

企业选择Linux的重要考量之中有成本控制,系统本身免费不算,开源生态还提供很丰富的免费工具以及解决方案,让软件授权费用大幅降低,再者,Linux对硬件要求相对宽松,旧型号服务器也能够流畅运行,硬件生命周期得以延长,企业整体的IT投入成本因而降低 。
linux系统服务器如何选择版本
倘若要挑选Linux发行版,就得全面考量业务需求以及技术团队能力。针对于Web服务器而言,Ubuntu Server跟CentOS Stream是挺好的选择,前者有着丰富的文档,易于让人上手,后者继承了CentOS的稳定性特质。要是运行数据库或者关键应用,Rocky Linux或者AlmaLinux能提供更长久的支持周期,适宜那种对稳定性有着极高要求的生产环境。
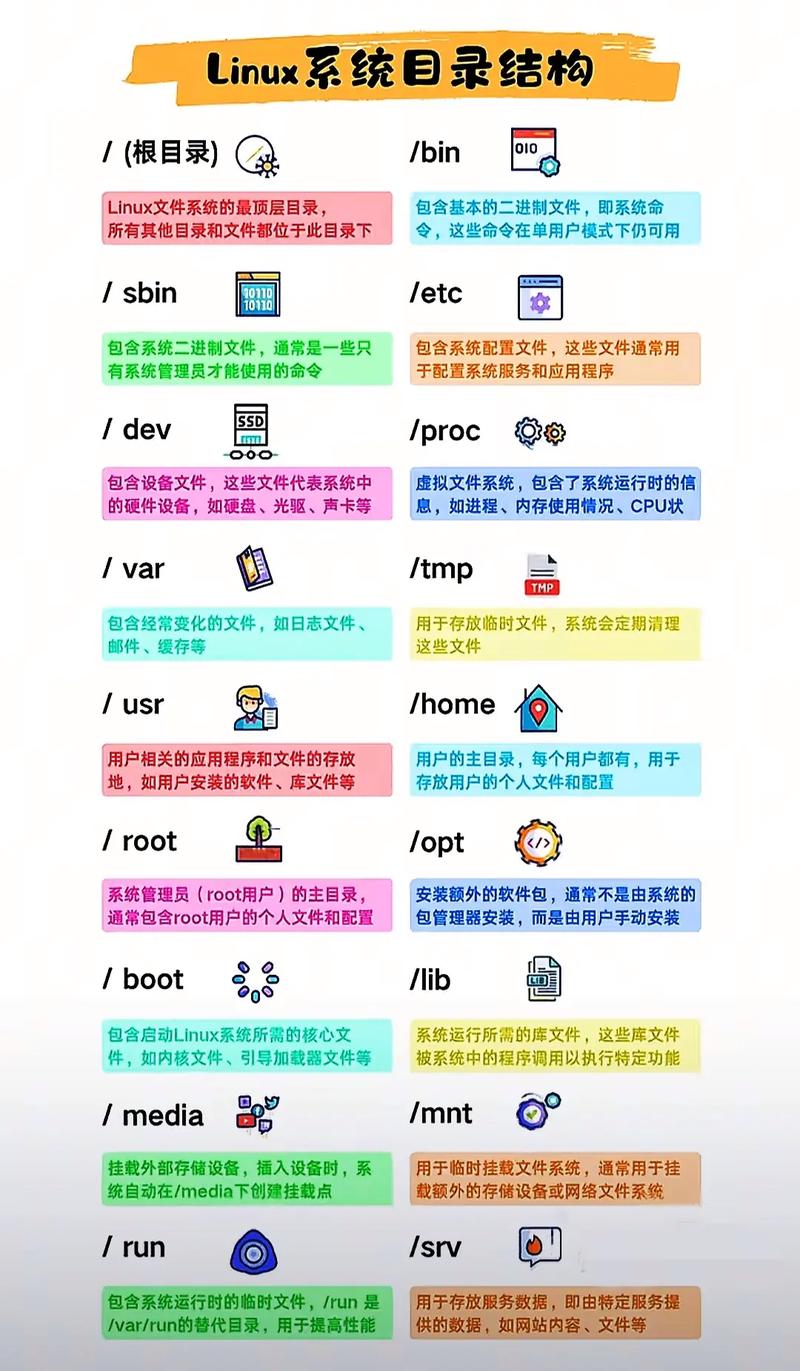
进行版本选择时是需要留意内核更新节奏以及硬件兼容性的,较新的内核版本对于最新硬件的支持状况会更好,然而却有可能将部分稳定性牺牲掉,建议生产服务器去选择LTS也就是长期支持版本,从而能够获取至少5年的安全更新支持。测试环境的话是能够使用滚动更新版本的服务器 linux系统,并且这可以提前熟练掌握新技术特性,进而为未来的升级做好相应准备。
linux服务器如何保障系统安全
最先要从最小化安装着手服务器安全保护工作,仅安装必需的软件包以及服务,以此来削减潜在攻击面,定期运行yum update或是apt update以实现系统状态的更新,尤其是安全补丁需要及时予以应用。在配置防火墙期间,除了默认的firewalld或者iptables之外,还能够结合fail2ban工具来自动封禁异常登录IP 。
权限管理属于安全的核心部分,要严格依照最小权限这个原则,给每个服务去创建独立的用户账号,要禁用root远程登录,转而使用普通用户搭配sudo提权,关键的配置文件要设置恰当的权限,敏感的数据要进行加密存储服务器 linux系统,要定期对系统日志展开审计,运用aide或者tripwire等工具去监控文件完整性的变化。
linux服务器日常维护有哪些要点
建立规范的巡检制度是日常所必需的维护,每天都要检查,系统负载、磁盘空间以及内存使用的状况,运用df -h、free -m等命令,去快速取得状态信息,对关键服务进程是否正常运行加以监控,配置logrotate定期轮转日志文件,防止日志体积过大而占满磁盘,每周开展一次完整的备份验证,以此确保灾难恢复的能力 。
性能监控类工具需进行合理配置,Zabbix或者Prometheus能够持续收集服务器里面的指标,设置恰当合理的告警阈值linux操作系统安装,定期去分析/var/log/messages以及dmesg输出,及时找寻到硬件故障的征兆,计划性重启之前要做好服务迁移预案,借助维护窗口应用内核更新,每一次变更都得记录详尽的操作日志 。
linux服务器性能如何优化调整
系统级的优化能够从内核参数的调整方面启动,依据服务器内存的大小来对swappiness值予以优化,进而削减不必要的交换行为,对文件系统挂载参数加以调整linux web服务器,像ext4文件系统能够添加noatime选项来减少磁盘写入,针对高并发的场景,要去修改网络相关的参数,例如增大TCP连接队列的长度,将TIME_WAIT状态回收予以优化。
实施应用层的优化之举,需展开具有针对性的剖析。针对Nginx或者Apache而言,得依据实际的访问模式,对工作进程的数量以及连接数的限制予以调整。对于数据库服务器来讲,要对缓存的大小以及查询的配置进行优化。运用诸如top、vmstat、iostat这类工具确定存在瓶颈之处,究竟是CPU、内存、磁盘IO方面的问题,还是网络方面的问题。牢记一点儿,优化应当基于实际的监控数据,防止毫无明确目标地进行调整。
linux服务器故障怎么快速排查

故障排查需依照系统化流程来进行,首先借助监控系统去明确故障所影响的范围,究竟是单台服务器,还是整个集群;接着登录服务器对基础状态予以检查,也就是查看网络是否连通,磁盘是否写满,关键进程是否存在;运用systemctl status去查看服务状态,利用journalctl -xe查看最近的系统日志信息。
涉及复杂问题时,需进行层层递进的深入剖析。针对内存问题,借助free以及vmstat来判定有没有泄漏情况发生。当CPU负载处于较高水平时,运用pidstat或者perf去确定热点进程所在位置。磁盘IO瓶颈借助iostat -x 1来观察await和util的值。对于网络问题,要联合ping、traceroute、tcpdump等多个工具共同开展协同分析。在每次故障被解决之后,都得撰写复盘报告,以此对应急预案予以完善。
于实际工作当中,每一个服务器环境皆存在其独有的特质。您于处理Linux服务器的进程里碰到的最为棘手的系统问题是啥东西?是经由怎样的方式最终予以解决的呢?欢迎于评论区去分享您的实战方面的经验经历,倘若觉着这些经验是有用处的,请进行点赞给予支持并且分享传播给更多的同行业人士。
