
作为互联网软件开发人员,你肯定在高并发场景里栽过“线程”的坑吧?
例如先前做秒杀功能,为了处理瞬时涌向的恳求,你想着多创建点线程扛压力,结果线程刚开到几万,服务器就报“内存溢出”——这时侯你是不是特疑问:为什么操作系统线程那么“金贵”,多建几个都不行?还有近来常听人说的“虚拟线程”,堪称能轻松支撑百万级数目,它究竟凭啥如此“廉价”?跟俺们平常用的操作系统线程(也就是平台线程)究竟啥关系?JVM又是如何把如此多虚拟线程管得服服帖帖的?
明天俺们就用大白话拆解那些问题,从开发中遇见的实际痛点切入,把虚拟线程的核心原理讲透,最后再给你们提提实操建议,看完你说不定能够在上次项目里用上这门技术了。
先聊个扎心的问题:为什么操作系统线程“建多了就崩”?
俺们先回到最实际的场景:你写了个插口处理用户恳求,用线程池管理线程,原本跳着挺稳,结果一到活动日并发上来,线程数往下降到1万多,服务就开始卡顿,再往上甚至直接崩了。你查日志发觉是“OutOfMemoryError”,这时侯你可能会想:不就是个线程吗中国linux,为什么如此占显存?
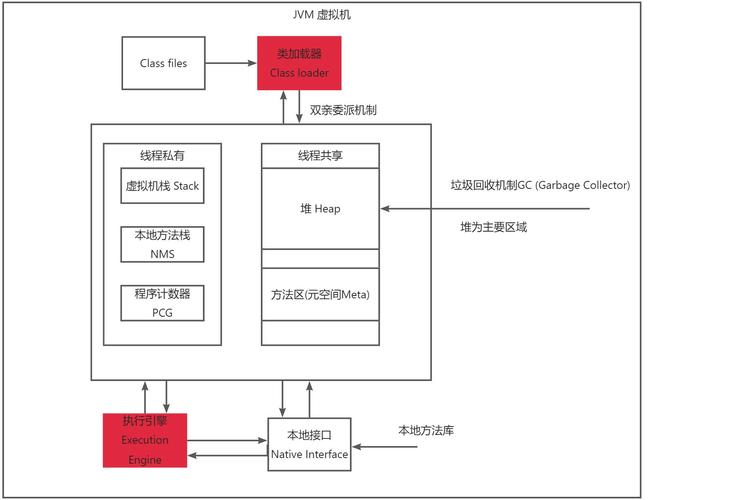
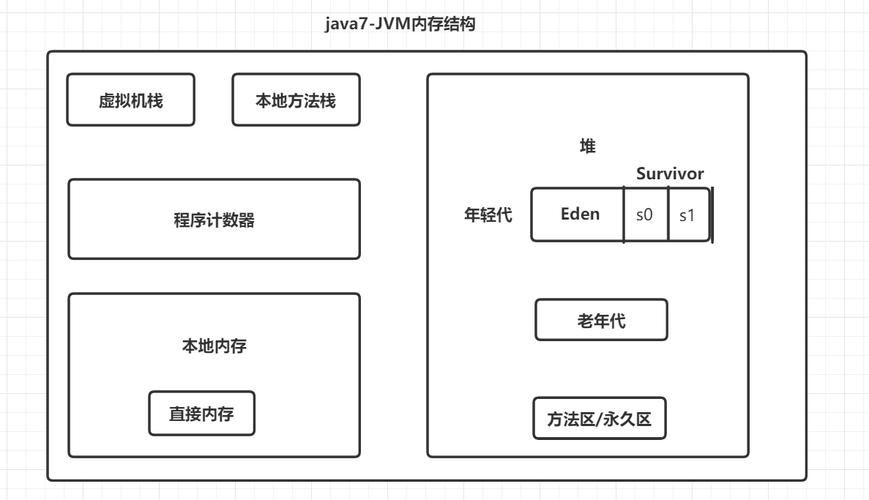
虽然问题出在操作系统线程的“重量级”上。俺们平常说的“平台线程”,本质上是操作系统内核级的线程,每位线程都要占用两块关键资源:
一是线程栈显存。默认情况下,一个Java平台线程的栈显存就得占1MB(你没看错,是1兆),这还只是初始大小,要是线程里调用的方式层级深,栈就会扩容。你算笔账:1000个平台线程就是1000MB,也就是1GB显存;要是想建10万个,那光栈显存就须要100GB——这对大部份服务器来说,根本扛不住。
二是内核资源开支。每位平台线程都要对应操作系统内核里的一个“任务控制块(TCB)”,内核要负责线程的创建、调度、上下文切换。而操作系统的内核调度能力是有限的,例如Linux系统默认的进程数上限也就几万,线程数再多,内核调度不过来,才会出现“线程饥饿”,致使服务响应变慢。
还有个更隐蔽的问题:上下文切换成本。当多个平台线程竞争CPU时,操作系统须要频繁切换线程状态——保存当前线程的寄存器值、程序计数器,再加载下一个线程的信息。这个过程看着快,但次数多了才会占用大量CPU资源。例如你有1万个平台线程,CPU核心只有8个,那上下文切换的开支会远小于线程实际执行任务的开支linux系统安装教程,最后服务就卡在“切换”上了。
这就是为什么俺们平常用平台线程时,线程池核心数通常设成“CPU核心数+1”或者“2*CPU核心数”,根本不敢往高了设——不是不想,是操作系统线程“太金贵”,实在建不起、用不起。
虚拟线程是咋来的?它和平台线程不是“替代关系”
既然平台线程有那么多限制,那虚拟线程是为了“替代”它吗?虽然不是——咱们得先厘清楚虚拟线程的定位,不然原理越学越乱。
首先说背景:虚拟线程是Java19引入的预览特点,Java21即将转正,它的设计目标很明晰——解决“高并发场景下线程数目不足”的问题,但它并没有准备把平台线程杀死,而是和平台线程产生“协作关系”。
你可以把它们的关系理解成“员工和小组长”:
为何要如此设计?由于俺们开发中大部份线程似乎都在“等”——比如线程发起数据库查询后,要等数据库返回结果;发起HTTP恳求后,要等对方服务响应。这段“等待时间”里,平台线程似乎是空闲的,但它还占着显存和内核资源,非常浪费。
虚拟线程就是把这段“等待时间”利用上去了:当虚拟线程执行IO操作时,JVM会把它“挂起”,之后把对应的平台线程腾下来,去运行其他虚拟线程。等IO操作完成,被挂起的虚拟线程再“恢复”,找个空闲的平台线程继续执行。
这样一来,一个平台线程能够“复用”给多个虚拟线程,相当于用少量“小组长”管了大量“员工”——这就是虚拟线程能支撑百万级数目的核心逻辑,也是它“廉价”的关键:它不占用独立的内核资源,栈显存也比平台线程小得多(默认几十KB,最大也就几MB)。
核心解决方案:虚拟线程的“廉价”密码和JVM的调度逻辑
俺们接出来拆解最关键的两个问题:虚拟线程究竟“廉价”在哪?JVM又是如何调度百万个虚拟线程的?这部份是原理核心,俺们尽量讲得浅显,不绕太多专业术语。
1.虚拟线程的“廉价”密码:3个关键设计
第一个密码:轻量级栈(用户态栈)。
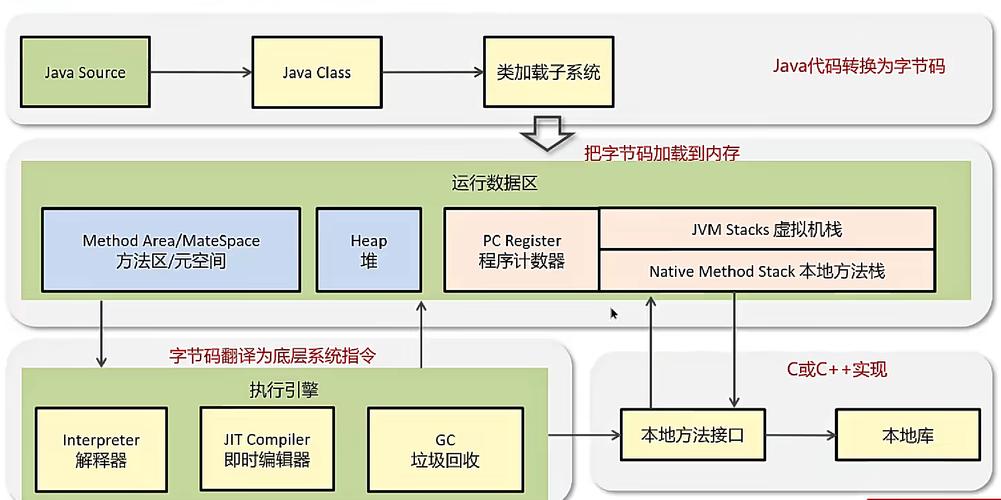
平台线程用的是“内核态栈”,由操作系统分配和管理,大小固定且不能太小(否则容易栈溢出);而虚拟线程用的是“用户态栈”,由JVM管理,大小是动态的——初始只有几十KB,当线程执行方式须要更多栈空间时,JVM再动态扩容;当方式执行完,栈空间又能回收。
例如一个虚拟线程执行“查询数据库”的逻辑,调用了3个方式,栈空间只须要存这3个方式的局部变量和返回地址,也就几十KB;而同样的逻辑,平台线程得占用1MB的初始栈显存——这么一对比,虚拟线程的显存占用直接降了一个数目级。
第二个密码:无内核资源独占。
每位平台线程都要占用操作系统的TCB、文件描述符等内核资源,而虚拟线程不直接对应内核线程,它的所有操作都通过JVM间接映射到平台线程上。这就好比:平台线程是“直接跟政府打交道的个体户”,要办各类护照(内核资源);虚拟线程是“个体户手下的临时工”,不用单独办证,跟随个体户干活就行。
没有了内核资源的禁锢,虚拟线程的创建和销毁速率也快得多——创建一个虚拟线程只须要几毫秒,而创建一个平台线程须要几微秒,速率差了上千倍。
第三个密码:IO等待时手动挂起,不占用平台线程。
这一点俺们上面提过,这儿再展开说细节:当虚拟线程执行到IO操作(例如Socket.read()、ResultSet.next()这种)时,JVM会测量到这个“阻塞操作”,之后做两件事:
一是把虚拟线程的“当前执行状态”(例如程序计数器、栈帧)保存到显存里,让它“挂起”;二是把它占用的平台线程“释放”,让这个平台线程去运行其他就绪的虚拟线程。
等IO操作完成(例如数据库返回结果了),JVM会把挂起的虚拟线程状态恢复,之后找一个空闲的平台线程,让它继续执行——这个过程叫“非阻塞IO映射”,完全在JVM层面完成,操作系统根本不晓得有虚拟线程的存在。
正是由于这个设计,虚拟线程的“等待时间”被充分借助,一个平台线程能支撑几十个甚至上百个虚拟线程,资源借助率直接拉满。
2.JVM的调度逻辑:如何管百万个虚拟线程?
你可能会问:既然一个平台线程能管多个虚拟线程,那JVM是如何安排那个虚拟线程该运行、哪个该挂起的?这儿要讲JVM的“调度器”设计,核心是“ForkJoinPool调度器”(Java里的一个线程池实现)。
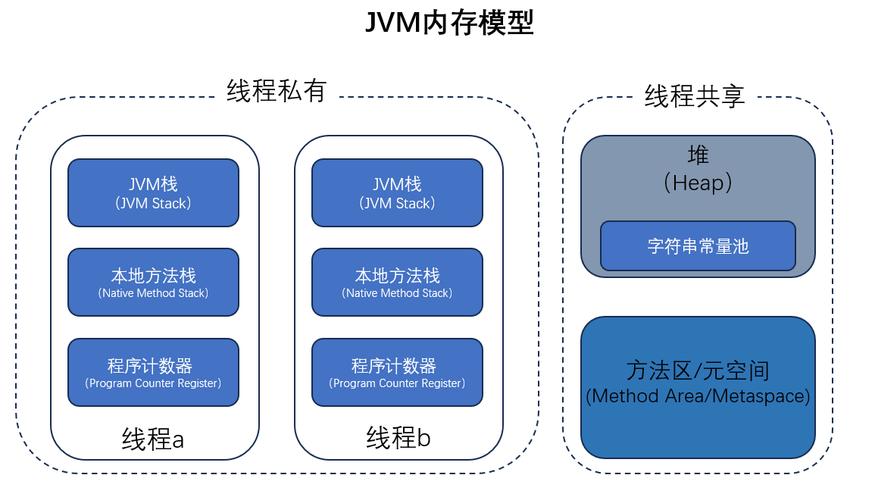
俺们可以把JVM的调度过程分成3步,用“员工干活”的事例再讲一遍:
第一步:给“小组长”分配任务池。JVM会初始化一个ForkJoinPool,这个池里的“工作线程”就是俺们说的“平台线程”(小组长)。默认情况下,ForkJoinPool的线程数等于CPU核心数,例如8核CPU就有8个工作线程——这就够了,由于CPU同一时间只能跑8个任务,多了也是切换。
第二步:给“员工”分配任务linux 栈溢出攻击原理,让小组长带活。当你创建一个虚拟线程(职工)并启动时,JVM会把它放在ForkJoinPool的“任务队列”里。每位工作线程(小组长)会从队列里拿虚拟线程linux 栈溢出攻击原理,之后执行它的代码。
第三步:职工“出差”时,小组长换个人带。当虚拟线程执行到IO操作(出差),JVM会把它从工作线程上“摘出来”,保存它的执行状态,之后把它放在“等待队列”里。这时侯工作线程(小组长)就空了,会去任务队列里再拿一个虚拟线程(另一个职工)继续干活。
等IO操作完成(出差回去),JVM会把“等待队列”里的虚拟线程移回“任务队列”,让它重新排队,等有空闲的工作线程了再继续执行。
这儿有个关键:JVM的调度是“用户态调度”,不须要操作系统参与。诸如虚拟线程的挂起、恢复、队列切换,都是JVM自己做的,速率比操作系统的“内核态调度”快得多——这也是百万级虚拟线程能顺畅运行的关键:调度成本低,不会给CPU带来额外负担。
举个实际的事例:假如你的服务有100万个虚拟线程,其中80万个都在等IO(例如查数据库、调插口),那只须要8个工作线程(对应8核CPU),能够把剩下20万个就绪的虚拟线程管好——因为这8个工作线程会不断从任务队列里拿线程执行,遇见IO阻塞就换一个,根本不会闲着。
总结:虚拟线程该如何用?俺们开发中要注意啥?
讲完原理,俺们再落地到实际开发——虚拟线程那么好用,俺们该如何用?有啥坑要避免?
首先说用法:Java21以后,创建虚拟线程非常简单,不用改太多代码。例如原先你用Thread创建线程:
Thread thread = new Thread(() -> {
// 业务逻辑
});
thread.start();如今想创建虚拟线程,只须要加个ofVirtual()方式:
Thread thread = Thread.ofVirtual().start(() -> {
// 业务逻辑
});或则用ExecutorService线程池,Java21提供了专门的虚拟线程池:
try (ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor()) {
// 提交100万个任务,每个任务对应一个虚拟线程
for (int i = 0; i {
// 业务逻辑,比如查询数据库、调用接口
});
}
}
是不是非常简单?不用改业务逻辑,只须要换个创建线程的方法,能够享受到百万级并发的能力。
之后说注意事项,这3个坑千万别踩:
第一个坑:把虚拟线程当“无限创建”的线程用。其实虚拟线程廉价,但100万个线程同时就绪,还是会占用显存——比如每位虚拟线程占100KB,100万个就是10GB显存,服务器还是会扛不住。所以还是要依照服务器显存大小,合理控制虚拟线程数目。
第二个坑:在虚拟线程里执行CPU密集型任务。虚拟线程的优势是“IO密集型任务”(例如查数据库、调插口),由于这类任务有大量等待时间,能让JVM复用平台线程。若果是CPU密集型任务(例如大量估算),虚拟线程会仍然占用平台线程,无法被挂起,这时侯虚拟线程和平台线程没啥区别,甚至由于调度开支,性能就会升高。
第三个坑:依赖ThreadLocal的代码要当心。ThreadLocal是绑定到“线程”的变量,原先用平台线程时,每位线程的ThreadLocal是独立的;但虚拟线程是复用平台线程的,假如你在虚拟线程里用ThreadLocal,可能会出现“线程安全问题”——比如前一个虚拟线程的ThreadLocal值,被后一个虚拟线程读到了。解决办法是用Java21新出的ThreadLocal.withInitial(),或则防止在虚拟线程里用ThreadLocal。
最后给你们提个小建议:假如你做的是网段、接口服务、消息消费这类IO密集型业务,如今就可以试试用虚拟线程替换原先的线程池——比如把消息消费者的线程池换成
newVirtualThreadPerTaskExecutor(),你会发觉同样的服务器配置,能处理的消息量直接翻好几倍。
其实,技术好不好用,还是要自己试过才晓得。你平常在项目里有没有碰到过线程不够用的问题?假如用虚拟线程,你认为能解决什么痛点?欢迎在评论区分享你的经历,俺们一起讨论实操方法,把这门技术用得更溜~
