在由数据所带动起来的相关业务情境当中,MySQL 数据库的高可用程度是极为关键的。对于众多转向 Linux 平台的技术团队而言,去搭建一个稳固且靠谱的 MySQL 集群,乃是确保业务连贯性以及数据安全性的关键任务。这并非仅仅只是单纯的软件安装,而是一项涉及架构挑选、系统设置以及故障处理的综合性项目。
MySQL集群的主要架构模式有哪些
MySQL集群主要运用两种核心架构,其一为佳主从复制,其二为组复制。主从复制是相当经典的模式,它凭借二进制日志达成数据异步同步,其结构简易,可是对于主库的单点故障欠缺原生应对举措。组复制是更为新颖的技术,它依据Paxos协议落实多节点数据的强劲一致性,还拥有自动故障检测与转移的能力。
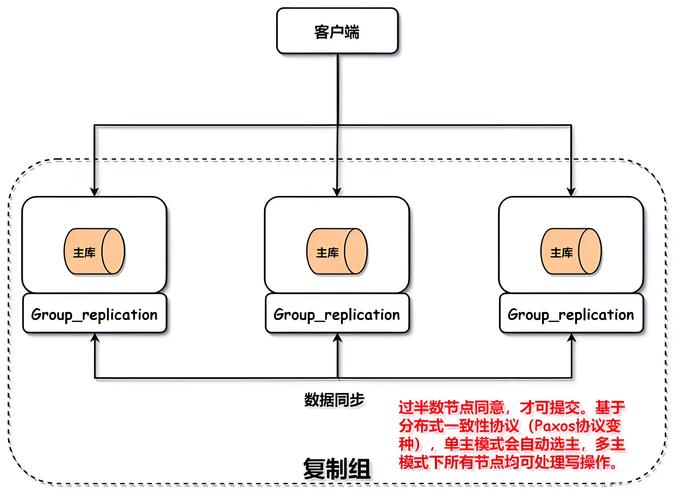
于选择架构之际,业务需求的权衡乃是必然需要考量的方面。在读取压力大并且允许存在秒级延迟的状况之时,主从架构搭配读写分离属于经济规划方面的举措。针对于数据一致性要求极其高的情形,就如同金融交易那样,采用组复制是必要的选择。在实际进行部署之前,于测试环境当中充分模拟网络分区以及节点宕机linux mysql集群搭建,并且评估其对于业务所产生的实际影响,这是一定要去做的。
如何规划Linux服务器的硬件和系统配置
就数据量以及并发量而言展开考虑并出发,针对硬件开展规划工作,给出的建议是数据库节点要配备高性能的SSD磁盘且要有充足的内存以及多核CPU,所要达到的内存容量应具备能够容纳活跃数据集的能力从而旨在减少磁盘I/O,在网络这一方面呢,要求集群节点之间呈现万兆互联的状况啊,并且要配置于同一个子网之中这般能够以此来降低网络延迟 。
系统配置起着稳定基础的作用,则其中,诸如 Linux 内核参数,像是提高文件描述符限制、优化网络缓冲区等,是需要做相应调整的,要关闭 NUMA 或者实施绑定,借此来防止内存访问产生不均衡的情况,另外,对于 MySQL 进程来讲必须设置合理的其 实是“资源限制(cgroups)”以及操作系统用户特定权限,进而以此达成可隔离以及是为“安全” 。
安装MySQL时需要特别注意哪些步骤
这里有个应当去做的建议,那就是前往MySQL官方仓库之处安装特定版本,举例来说具体版本精确到8.0,如此这般去做是为让能获取到最新的诸如组复制这类企业级功能。在进行安装之际,需要将所有节点的MySQL版本以及配置路径弄成统一的,以此来防止出现兼容性方面的问题。在完成初始化数据库之后,首先要做的事情是,要去设定强密码策略,而且创建专门用来进行集群同步的独立账户。
在配置文件当中,server -- id在全局范围需保持唯一,它是复制的身份标识。bind -- address要准确无误设为内网IP,以保障集群内部通信顺畅、可互相连通,同时要严谨限制外网访问。log_bin等与复制相关参数必须明确开启,它是数据同步起始源头。
怎样配置主从复制实现数据同步
早在最开始的时候,于主库那边创建了拥有复制权限的那个从库用户,紧接着,依靠mysqldump或者克隆插件去取得一致性数据快照,然后把它导入那个从库,这便是搭建的起始点,随后,要在从库执行CHANGE MASTER TO命令,该命令要指向主库的地址,以及二进制日志坐标,还有认证信息。
处于复制进程开启状态后,就得即刻瞅一瞅,Slave_IO_Running以及Slave_SQL_Running状态究竟是否为Yes。借助监控Seconds_Behind_Master指标,以此来去明白复制品延迟的状况。于日常的运维操作范畴之内,需要定时去校验主从数据的一致性,能够采用pt-table-checksum这类工具,且安好打理好主库上并行事务有概率引发的复制冲突 。
如何搭建更高可用的MySQL组复制集群
组复制集群存在着要求,这个要求是至少得有三个节点,在每个节点的配置文件里,要启用group_replication插件,还要配置group_replication_local_address(也就是集群通信地址)以及group_replication_group_seeds(即种子节点列表)。这属于一件精细的事linux 电子书,一旦有任何一个节点配置出现不一致的状况,就会导致加入失败。
开启之际,于一节点实施SET GLOBAL group_replication_bootstrap_group=ON这般操作,借此引导组,其余节点后续会进行加入动作。成功加入后,集群会自行开展主节点选举事宜。关键是要妥善配置故障检测及仲裁机制,确保网络分裂时linux mysql集群搭建,多数派持续提供服务,少数派自动被排除,防止“脑裂”发生。
MySQL集群的日常监控与故障如何排查
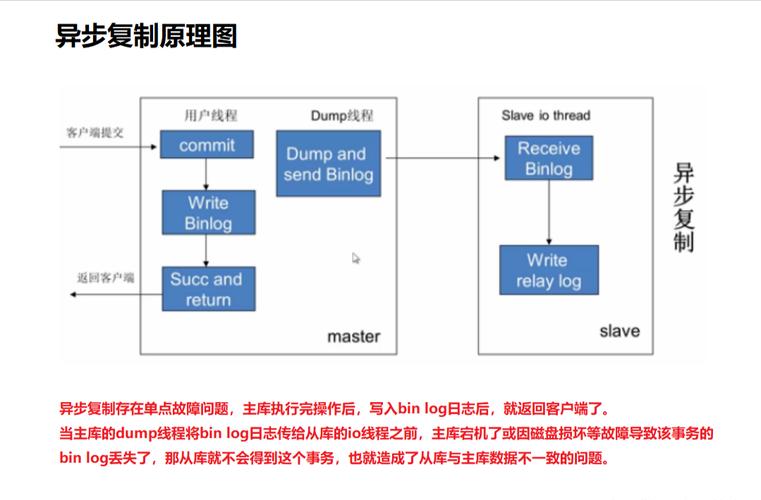
多层指标要予以覆盖来实施监控,操作系统层面得关注CPU,关注内存,关注磁盘IO,还得关注网络流量,而数据库层面则需要对活跃线程数进行监控,对InnoDB缓冲池命中率进行监控,对复制延迟进行监控,还要对组复制成员状态进行监控,能够借助部署Prometheus加上Grafana来实现可视化告警。
遇到的故障当中,存在网络震颤造成复本中断的情况,存在从库使用有误的情况linux软件,存在脑裂这类状况。在开展排查此项工作时,首先要去瞧瞧错误日志,之后要通过SHOW SLAVE STATUS这个或者SELECT * FROM performance_schema.replication_group_members去查看状态。在网络方面所呈现出的问题上,要和运维一同展开协同来实施排查;当数据出现conflict这样的状况之际,依据错误编号来判定具体的SQL,进而开展重放或者跳过的操作。
敢问在您的生产环境里,到底是更倾向于选择技术成熟的主从复制呢 ,还是去接受拥有自动容灾能力的组复制呀 ?真心希望您在评论区分享您架构选型的考量以及实践经验呢 ,要是本文对您有帮助的话 ,请大方地进行点赞以及转发哟 。
