深度学习的环境搭建对不少人来说是一座山,尤其当你面对的是CentOS这种默认不带图形界面的服务器系统。很多人觉得装个显卡驱动、配个CUDA、再装个PyTorch就能跑,真正动手就会发现坑一个接一个。我这些年摸爬滚打下来永久免费linux服务器,把最实用的流程整理出来,希望能帮你少走弯路。
检查硬件和系统基础
在动手之前,先确认你的机器到底能不能跑深度学习。CentOS系统对硬件的支持有时候比较奇怪,特别是显卡这一块。第一步就是看显卡型号,执行lspci | grep -i nvidia,如果啥都没显示,那你可能需要检查一下显卡是不是没插好,或者根本就是AMD的卡。深度学习框架虽然也支持AMD,但主流还是NVIDIA的CUDA生态centos 深度学习环境,所以如果你不是特别有经验,建议直接用N卡。
接着检查系统版本,cat /etc/centos-release。CentOS 7和8的安装方式差别很大,包管理工具都不一样。CentOS 8已经停止维护了,但很多人还在用,这时候需要注意更换yum源,不然很多包都装不上。我建议如果是新装系统,直接用CentOS 7.9以上版本,或者转向Rocky Linux、AlmaLinux这类兼容品。系统内核也别太老,uname -r看一下,低于3.10的版本可能不支持新驱动。
还有一个经常被忽略的问题:BIOS里的Secure Boot。很多服务器默认开启,装了NVIDIA驱动后会直接黑屏或无法加载模块。如果你发现装完驱动重启后进不去系统,先进BIOS关掉Secure Boot再试。另外,内存和硬盘也要够用,深度学习训练动不动吃几十G内存,硬盘建议至少留100G以上,不然一个数据集都下不完。
安装显卡驱动和CUDA
驱动安装是整个环境搭建里最容易出岔子的一步。NVIDIA官方提供了runfile和rpm两种安装方式,我强烈推荐用runfile,因为rpm源经常和系统自带的nouveau驱动冲突,导致装完开机黑屏。先禁用nouveau:在/etc/modprobe.d/blacklist.conf里加上blacklist nouveau,然后执行dracut --force重建initramfs,重启之后验证lsmod | grep nouveau没有输出才算成功。
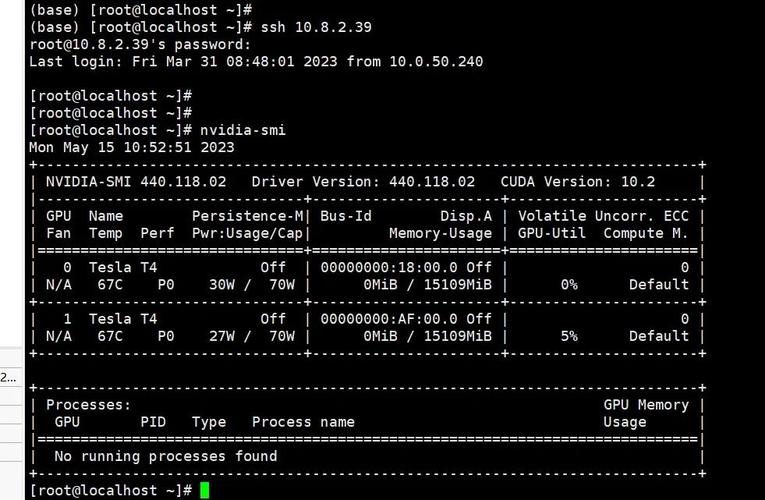
下载驱动前去NVIDIA官网选对型号和系统版本。CentOS 7对应的是RHEL 7的包,不要选成Ubuntu的。下载后赋予执行权限,直接运行./NVIDIA-Linux-x86_64-xxx.run,安装过程中会提示是否安装32位兼容库,一般不用选。安装完执行nvidia-smi,如果能看到显卡信息、驱动版本和CUDA版本,说明驱动装好了。这里有个细节:nvidia-smi显示的CUDA版本是驱动支持的最高版本,并不代表你已经安装了CUDA工具包。
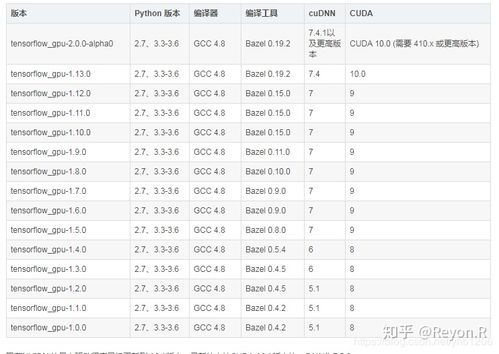
接下来装CUDA。很多人直接装最新版,但PyTorch和TensorFlow对CUDA版本有要求,建议先查一下你常用的框架支持哪个版本。比如PyTorch 2.0以上对CUDA 11.8或12.1支持最好。去NVIDIA官网下载对应的runfile,注意不要选deb包。安装时不要勾选驱动选项,只装CUDA Toolkit。装完后在~/.bashrc里加两行环境变量:export PATH=/usr/local/cuda/bin:$PATH和export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH,然后source生效。测试一下nvcc -V,能看到版本号就对了。
配置Python环境和深度学习框架
CentOS自带的Python版本通常很老,CentOS 7默认是Python 2.7,这年头谁还用Python 2。建议用Miniconda来管理Python环境,它比Anaconda轻量,而且可以随意切换Python版本。下载Miniconda安装脚本,一路默认安装,装完后记得把conda加入PATH。然后创建一个新环境,比如conda create -n dl python=3.10,激活后再装框架。
PyTorch的安装命令在官网可以自动生成,根据你的CUDA版本选择对应的命令。比如CUDA 11.8就用conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia。装完后验证一下:在Python里执行import torch; print(torch.cuda.is_available()),返回True就说明一切正常。TensorFlow的安装也类似,不过它更依赖cuDNN,需要单独下载。去NVIDIA官网注册账号下载cuDNN,解压后把文件复制到CUDA目录下就行。
还有一个小细节:CentOS默认的glibc版本可能不满足某些框架要求,比如TensorFlow 2.10以上需要glibc 2.17以上,CentOS 7一般没问题,但如果你用的是CentOS 6就别想了。遇到这种问题要么升级系统,要么用Docker。另外,如果遇到缺少libcuda.so之类的报错RED HAT LINUX 9.0,检查一下/etc/ld.so.conf.d/里有没有CUDA的配置,没有的话手动加一条/usr/local/cuda/lib64,然后执行ldconfig。
常见问题和优化技巧
装完环境后第一次跑模型,很多人会遇到显存不足或者CPU跑满的问题。先检查一下是不是用了CPU版本的框架centos 深度学习环境,比如torch.cuda.is_available()返回False,八成是装了CPU only的版本,重新装GPU版就行。还有一种情况是驱动装好了但CUDA没装,这时候框架也能检测到显卡,但无法调用,报错信息里会提到CUDA driver version或runtime version不匹配。
内存不够也是个头疼的问题。CentOS服务器通常有很多服务在跑,比如httpd、mysql,这些会占用不少内存。训练前可以free -h看看剩余内存,如果少于8G,建议关掉不必要的服务,或者用sysctl vm.drop_caches=3清理缓存。对于显存,可以用nvidia-smi监控,如果发现被其他进程占用了,用fuser -v /dev/nvidia<strong>找出进程ID然后杀掉。
还有一点很多人不知道:CentOS的默认文件句柄限制很低,训练时如果数据集包含大量小文件,很容易报“Too many open files”的错误。临时解决用ulimit -n 65535,永久修改需要编辑/etc/security/limits.conf,加上</strong> soft nofile 65535和* hard nofile 65535。重启后生效。另外,如果训练过程中经常卡死,检查一下交换分区是否开启了,深度学习不建议用交换内存,直接关掉swapoff -a能提升稳定性。
CentOS深度学习环境的搭建没有想象中那么复杂,但每一步都需要细心。驱动、CUDA、框架三个环节环环相扣,任何一个版本不对都会导致整个环境瘫痪。照着这个流程走一遍,基本能解决大部分问题。如果遇到奇怪的报错,先看日志,再查版本兼容性,大多数坑都能填平。
