于容器化部署里,数据持久化乃一关键挑战。Docker SWarm身为原生的集群管理工具,其Volume机制是保障服务数据可靠性以及一致性的核心所在。它并非仅是单个Docker主机上Volume概念的单纯延伸,还涵盖有跨多个节点的数据储备、分发以及生命周期管理。领会Swarm Volume的运行原理与最佳实践,对构建强健的分布式应用甚为关键。
Swarm中Volume与本地Volume有何不同
单机Docker环境里,Volume是宿主机上被Docker管理的一个目录,其生命周期独立于容器。然而在Swarm集群中,服务有可能在任意节点创建副本。要是服务采用默认的本地Volume,那么每个副本写入的数据只会存在于其所在节点的本地目录里,不同副本间的数据会完全隔离,这通常并非期望达到的结果。
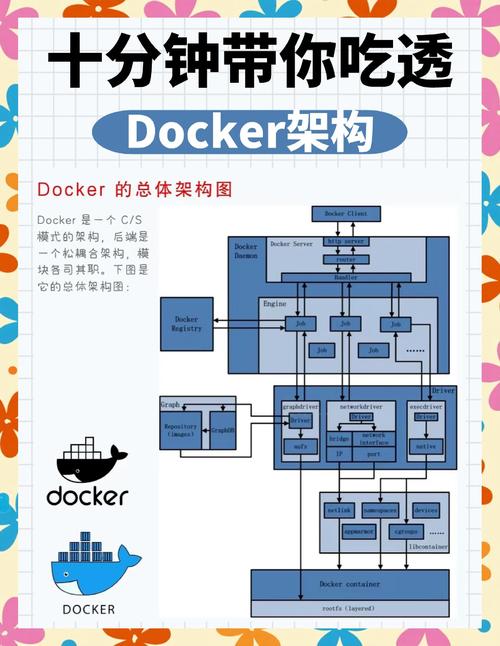
数据不一致问题,是由这种差异直接导致的。比如说,有一个Web应用的服务,它有5个副本,这5个副本分别运行在5台节点上。要是它们分别写入本地的/data Volume,那么当用户请求被负载均衡到不同节点那时,所看到的将会是5份不一样的数据。所以,Swarm中的Volume设计,必须要考虑数据的全局访问性。
如何为Swarm服务配置持久化数据卷
对Swarm服务去配置Volume嘛,得要在docker service create这个命令或者堆栈文件里头明明白白地进行定义哟。其关键所在于去使用--mount这么个参数呐,并且还要指定type为volume呢。有一个典型的命令格式是这样子的哈:docker service create --name myapp --mount source=mydata,target=/app/data nginx:latest 。此时,于每个服务任务,也就是容器启动之际,会把名为mydata的卷,挂载至容器的/app/data这个路径。
更值得去推举的做法乃是运用Docker Compose格式的堆栈文件来开展声明式部署,在docker-stack.yml里,能够于服务定义之下运用volumes字段,明晰地表明卷挂载关系,这般的方式对版本控制颇为便利,并且利于重复部署,是管理复杂Swarm应用的标准方式。
Swarm Volume的数据如何实现跨节点共享
默认之下的本地Volume驱动没办法达成跨节点数据共享,达成这个得用支持分布式存储的Volume驱动docker swarm volume,最常碰见的方案是配置网络文件系统也就是NFS卷驱动,你得先于所有Swarm节点上安装NFS客户端,接着在创建Volume之际指定驱动为local,不过借由o选项去传递NFS服务器参数。

比如,在进行创建操作的时候,所采用的方式为:docker volume create --driver local --opt type=nfs --opt device=: 。 --opt o=addr=此后,任何会把 nfs - volume 挂载至容器的服务,其全部副本不管运行于哪一个节点red hat linux 下载,读和写都是同一份存储于 NFS 服务器上的数据,进而达成了真正的共享。
哪些Volume驱动适合Swarm生产环境
选取切实可信赖的共享存储驱动,这是针对生产环境而言的奠基之举呀。除开上述所提及的NFS之外呢docker swarm volume,企业级别的方案之中还涵盖着:云提供商所给予的块存储选项,像是AWS EBS以及Azure Disk这样的,不过一定要搭配特定的驱动才能够达成跨节点挂载的操作;还有分布式文件系统,例如Ceph这种借助RBD或者CephFS的,以及GlusterFS这一类,它们能够达成更为卓越的性能以及冗余的效果;另外还有商业存储产品相应提供的Docker插件呢。
进行抉择之际呀,得把性能、持久性、可用性、备份能力以及成本综合起来予以考量呢。比如说呀,在云环境当中呢,直接去运用云厂商所提供的托管存储服务并且搭配上CSI插件呀,通常来讲是集成度最为高的、运维最为简便的这样一种选择哟。关键之处在于呀,要保证所挑选的驱动能够给出Swarm集群范围之内统一的数据方面的视图呢。

Swarm中Volume的生命周期如何管理
Swarm里Volume的生命周期管理相较于单机而言更为复杂,借助docker volume create手动创建的卷系“全局对象”,其独立于任何服务,当删除服务时它不会自动被删除,在堆栈文件内运用顶级volumes声明创建的卷,于使用docker stack rm移除堆栈时,默认同样不会被删除,此乃为防止误删数据。
清理这些卷,得手动执行docker volume prune或者docker volume rm。有一种最佳实践,即在非生产环境里部署堆栈之际,能够加上--prune标志,像docker deploy --prune -c docker-stack.yml mystack,这会于移除未使用的服务卷之时一并清理关联的匿名卷,不过要谨慎运用标点。
Swarm Volume数据备份与恢复的正确方法
备份Swarm Volume的数据,关键之处在于备份其背后的持久化存储,对于NFS卷而言,直接备份NFS服务器上的目录就行,对于云盘来说,可以借助云快照功能,通用的办法是运行一个一次性任务容器,挂载需要备份的卷以及另一个用于存放备份文件的卷(或者主机目录)64位linux,在容器内运用tar或rsync命令来打包数据。
与之相反的是恢复,它属于逆向的操作行为。首先要做的是确保目标Volume是存在的,紧接着同样要运行一个承载任务的容器,把数据卷以及存放着备份文件的卷进行挂载,随后将备份内容解压到数据卷当中。必须要在应用服务已经停止或者处于只读状态的情况下开展恢复操作,以此来防止数据遭到损坏。定期对恢复流程的有效性展开测试,这和备份本身的重要程度是一样的,不可忽视。
于您的Swarm生产集群里,针对有状态服务的数据持久化这一情况,您究竟是更加倾向去运用像NFS这类的网络存储呢,还是依靠云厂商所提供的那个托管存储服务呢?原因是什么呢?欢迎在评论区域分享您的架构选型所具有的相关经验以及碰到的那些挑战,要是本文对您产生帮助的话,也敬请点赞予以支持。
