解决方法1
tcp_tw_reuse 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭 tcp_tw_recycle 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭
对于客户端
作为客户端因为有端口65535问题,TIME_OUT过多直接影响处理能力,打开tw_reuse 即可解决,不建议同时打开tw_recycle,帮助不大;tw_reuse 帮助客户端1s完成连接回收,基本可实现单机6w/s短连接请求,需要再高就增加IP数量; 3. 如果内网压测场景,且客户端不需要接收连接,同时 tw_recycle 会有一点点好处; 4. 业务上也可以设计由服务端主动关闭连接。 不像客户端有端口限制,处理大量TIME_WAIT Linux已经优化很好了,每个处于TIME_WAIT 状态下连接内存消耗很少, 而且也能通过tcp_max_tw_buckets = 262144 配置最大上限,现代机器一般也不缺这点内存。 粗暴点的话 直接发rst要是对数据可靠性没什么要求的话 疑问:tcp_tw_reuse如何打开?要编译linux内核?
tcp_tw_reuse可在客户端打开,服务端不用打开
tcp_tw_reuse仅在TCP套接字作为客户端,调用connect时起作用。绝大部分的TCP服务器,应该不会有大量主动连接的动作(或许会连接DB等,但一般也是长连接)。因此这个选项对于TCP服务来说,基本上是无用的,完全是没必要打开
解决方法2:优化程序,减少TCP链接的创建与关闭,同一台服务器,连接一次就好了,不要连接了又关闭,然后再连接
这边直接转载一篇文章吧:服务器TIME_WAIT和CLOSE_WAIT分析和解决办法
相应缩写
SYN:SYNchronize(同步)
ACK:ACKnowledge character(确认字符)
FIN:FINish(终止)
MSL:Maximum Segment Life(最大分段寿命)
RST:Reset(重置)
一、TCP 状态示意图
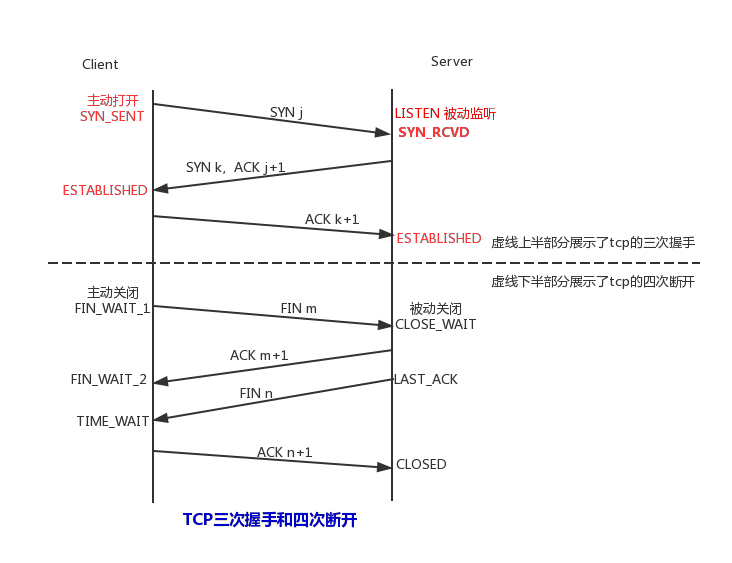
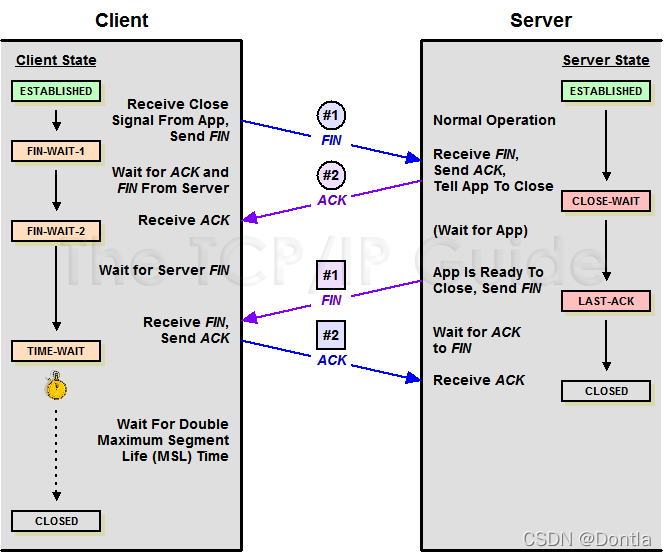
二、查询TCP连接数可以使用下面的Linux netstat命令
netstat -ant|awk '/^tcp/ {++state[$NF]} END {for(key in state) print (key,state[key])}'
我们hikflow_demo程序启动后:(果然程序有问题啊,这么多TIME_WAIT的。。。)
(启动后)
# netstat -ant|awk '/^tcp/ {++state[$NF]} END {for(key in state) print (key,state[key])}'
LISTEN 8
FIN_WAIT2 1
ESTABLISHED 3
SYN_SENT 45
CLOSE_WAIT 1
TIME_WAIT 11
(过了一段时间)
# netstat -ant|awk '/^tcp/ {++state[$NF]} END {for(key in state) print (key,state[key])}'
LISTEN 8
ESTABLISHED 4
CLOSE_WAIT 1
TIME_WAIT 111
(关闭程序后)
# netstat -ant|awk '/^tcp/ {++state[$NF]} END {for(key in state) print (key,state[key])}'
LISTEN 8
FIN_WAIT2 1
ESTABLISHED 3
TIME_WAIT 95
(关闭程序后过一段时间,可以看到TIME_WAIT不断减少,最终降为2)
# netstat -ant|awk '/^tcp/ {++state[$NF]} END {for(key in state) print (key,state[key])}'
LISTEN 8
ESTABLISHED 4
TIME_WAIT 2
常用的三个状态是:ESTABLISHED表示正在通信 、TIME_WAIT表示主动关闭、CLOSE_WAIT表示被动关闭。
三、服务器出现异常最长出现的状况是:
(1)服务器保持了大量的TIME_WAIT状态。
(2)服务器保持了大量的CLOSE_WAIT状态。
我们也都知道Linux系统中分给每个用户的文件句柄数是有限的,而TIME_WAIT和CLOSE_WAIT这两种状态如果一直被保持,那么意味着对应数目的通道(此处应理解为socket,一般一个socket会占用服务器端一个端口,服务器端的端口最大数是65535)一直被占用,一旦达到了上限,则新的请求就无法被处理,接着就是大量Too Many Open Files异常,然后tomcat、nginx、apache崩溃。。。
下面来讨论这两种状态的处理方法,网络上也有很多资料把这两种情况混为一谈,认为优化内核参数就可以解决linux关闭tcp连接命令,其实这是不恰当的。优化内核参数在一定程度上能解决time_wait过多的问题,但是应对close_wait还得从应用程序本身出发。
四、服务器保持了大量的time_wait状态
这种情况比较常见,一般会出现在爬虫服务器和web服务器(如果没做内核参数优化的话)上,那么这种问题是怎么产生的呢?
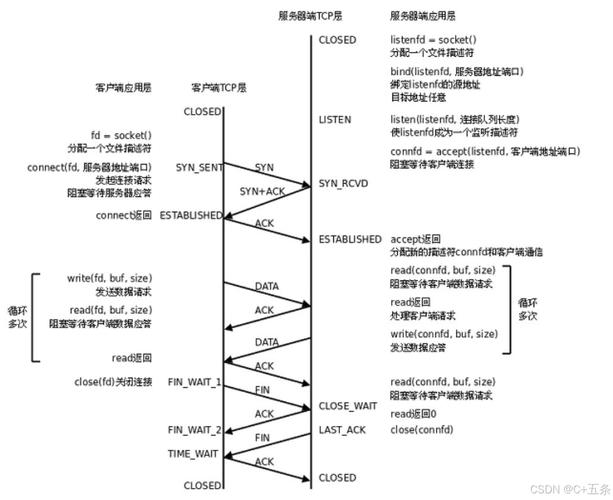
从上图可以看出time_wait是主动关闭连接的一方保持的状态,对于爬虫服务器来说它自身就是客户端,在完成一个爬取任务后就会发起主动关闭连接,从而进入time_wait状态,然后保持这个状态2MSL时间之后,彻底关闭回收资源。这里为什么会保持资源2MSL时间呢?这也是TCP/IP设计者规定的。
TCP要保证在所有可能的情况下使得所有的数据都能够被正确送达。当你关闭一个socket时,主动关闭一端的socket将进入TIME_WAIT状 态,而被动关闭一方则转入CLOSED状态,这的确能够保证所有的数据都被传输。当一个socket关闭的时候红旗linux安装,是通过两端四次握手完成的linux命令行和shell脚本编程宝典,当一端调用 close()时,就说明本端没有数据要发送了。这好似看来在握手完成以后,socket就都可以处于初始的CLOSED状态了,其实不然。原因是这样安排状态有两个问题linux关闭tcp连接命令, 首先,我们没有任何机制保证最后的一个ACK能够正常传输,第二,网络上仍然有可能有残余的数据包(wandering duplicates),我们也必须能够正常处理。
TIME_WAIT就是为了解决这两个问题而生的。
假设最后的一个ACK丢失,那么被动关闭一方收不到这最后一个ACK则会重发FIN。此时主动关闭一方必须保持一个有效的(time_wait状态下维持)状态信息,以便可以重发ACK。如果主动关闭的socket不维持这种状态而是进入close状态,那么主动关闭的一方在收到被动关闭方重新发送的FIN时则响应给被动方一个RST。被动方收到这个RST后会认为此次回话出错了。所以如果TCP想要完成必要的操作而终止双方的数据流传输,就必须完全正确的传输四次握手的四步,不能有任何的丢失。这就是为什么在socket在关闭后,任然处于time_wait状态的第一个原因。因为他要等待可能出现的错误(被动关闭端没有接收到最后一个ACK),以便重发ACK。
