在Linux系统里,碰到文件因存储介质出现坏块致使损坏的情况,这是好多从事运维工作的人员以及开发者会遭遇的棘手难题,而且这种情况通常表明数据完整性在物理层面遭遇了挑战,对于解决它而言linux 修复坏块文件,仅仅依靠软件命令是不行的,还有重中之重的是要去理解其背后所蕴含的原理,并且要采用一套从进行诊断开始,一直到完成修复,再到实施预防的完整策略,而在面对这类问题而去处理的时候,保持冷静并且优先于其他事情去备份还存在的数据是首要被秉持的原则 。
什么是硬盘坏块以及如何影响Linux文件
硬盘坏块为存储介质里没办法可靠进行读写数据的物理扇区,它们分成两种,物理坏块是因撞击、老化等硬件损伤致使,没办法修复,逻辑坏块是由写入中断、固件错误引发,能通过格式化重映射来解决,当文件数据正好存储在这些坏块之上时,就会出现损坏。
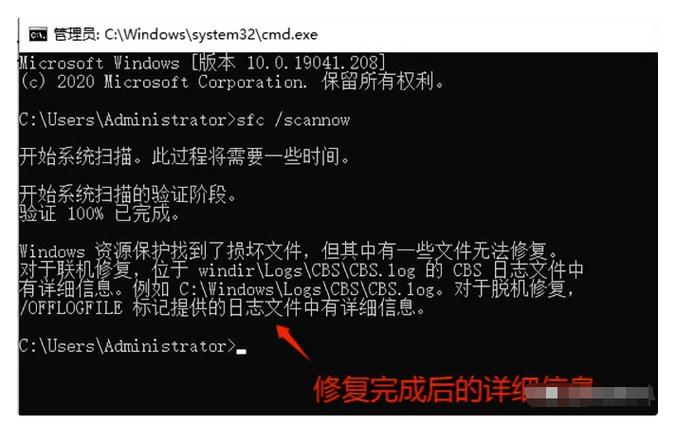
Linux系统里,读取特定文件时,I/O错误急剧增多,系统日志(/dev/sda)中,“I/O error”、“bad sector”等记录频繁出现。损坏的文件,可能无法打开,或者内容出现乱码、部分丢失。更严重的是,关键系统文件受损的话,可能导致服务异常,甚至系统无法启动,所以及时识别坏块来源相当重要。
如何检测Linux硬盘是否存在坏块
先要进行检测坏块这一步骤,这是修复工作开展的起始环节。有一种最为直接的工具,它就是badblocks命令。存在一种安全的选择方式,那便是采用只读模式去扫描整个磁盘,具体的命令形式像sudo badblocks -sv /dev/sda这样,这里面的-s起着显示进度的作用的标识,-v则是用于输出详细信息的标识。这个命令会将所有可疑的扇区编号都罗列出来,不过需要注意留意的是linux 修复坏块文件,要是进行长时间扫描的话,有可能会给已然存在问题的硬盘造成额外的压力。

除专用命令外,智能监控工具smartctl可给出更周全的预判,借助sudo smartctl -a /dev/sda能查看硬盘的SMART健康属性,尤其要留意“Reallocated_Sector_Ct”(重映射扇区数)以及“Current_Pending_Sector”(待定扇区数)的值,这些数值的不断增加是坏块出现并扩散的清晰信号,会提醒你要着手准备数据迁移或者更换硬盘。
发现坏块后如何立即挽救文件数据
要是一旦确定坏块已然存在,那么首要的行动并非是去修复,而是要抢救那数据。得马上停止针对受影响分区的写入操作,以此来防止数据被就此覆盖。倘若文件系统仍然是能够被挂载的,那就优先运用ddrescue工具去进行数据抓取。它所具备的优势在于碰到错误的时候会予以跳过然后继续,进而将数据恢复最大化。

比如说,运用sudo ddrescue /dev/sda1 /mnt/rescue/image.img /mnt/rescue/logfile.log把分区里的内容镜像到安全的地方。针对单个重要的文件,能够尝试使用cp命令搭配-f参数强制进行复制,有时候能够读取出没有损坏的部分。与此同时,检查系统自动生成的备份,像是/var/log下的日志轮替文件或者用户主目录的隐藏版本备份,它们有可能保留着健康的数据副本。
使用fsck工具尝试修复文件系统错误
数据抢救完毕之后,能够试着去修复文件系统层面存在的逻辑错误。“fsck”(也就是文件系统检查)属于标准工具。开展操作前必须要先卸载分区,就像执行“sudo umount /dev/sda1”这样的操作。随后依据文件系统的类型去运行对应的命令,举例来说对于ext4文件系统运用“sudo fsck -y /dev/sda1”,其中参数“-y”代表着自动确认修复。
对于fsck而言,它会试着去标记坏块,然后把数据迁移到健康的扇区上去。然而,必须要清醒地认识到这一点,它主要修复的其实是文件系统结构,像是inode、位图这类的逻辑不一致情况。只是对于物理坏块本身linux环境配置,它仅仅是把它添加进坏块列表,以此来避免后续再使用。要是fsck报告了大量错误,或者修复失败了,一般说明物理损坏已经很严重了,就不应该再依靠这个硬盘去存储重要数据了。
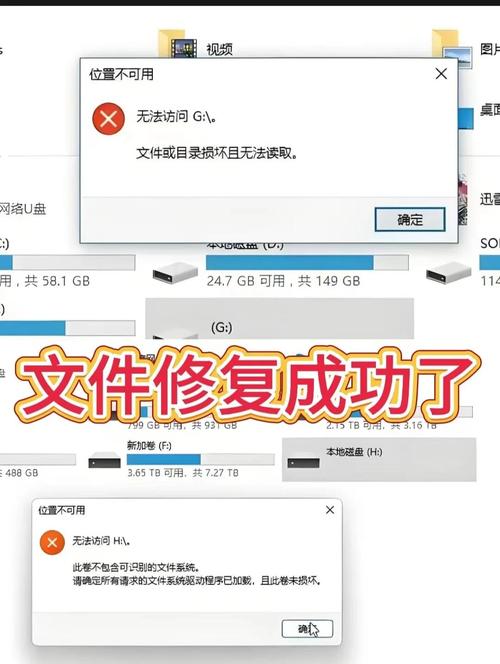
从备份中恢复损坏文件的可靠方法
往往最具成效的“修复”源自完好无损的备份,要是你存有定期的备份策略,此刻便是查验它的时候,去瞧瞧你的备份存储之处,那或许是外接硬盘、网络存储(NFS、Samba)亦或是云存储服务,依据备份时间点以及文件修改记录,寻觅到坏块出现之前彼时的最新版本。
恢复之际,建议先恢复至临时目录予以验证,待确认文件完整没错并且可用之后再去覆盖原位置。针对版本控制系统(诸如Git)所跟踪的代码或者文档,径直运用git checkout或者git restore命令便可回退到历史版本。针对没有备份的情形,此步骤的缺失恰恰突显了实施自动化备份方案(像使用rsync、BorgBackup工具制定定时任务)的极度重要性。
如何预防未来再次出现坏块导致文件损坏

核心在于监控的预防之意义表现为维护以及硬件管理,需定期譬如每月运行smartctl用来检查SMART状态redhat linux 9.0下载,并且要把关键属性监控此项任务纳入Zabbix、Prometheus等告警系统之中。要避免的行径则在于服务器长时间处于高温以及振动环境,因为这些均属于硬盘的杀手。
于文件系统层面,针对关键数据挑选拥有较强容错以及自愈能力的系统,像ZFS或者Btrfs,它们在冗余配置情形下支持数据校验与自动修复。最终,任何一块单独的硬盘都并非可靠的,对于重要数据以及服务,一定要运用RAID(比如RAID 1、RAID 6)或者分布式存储去给予冗余,以此保证单点物理故障不会致使数据丢失。
于实际开展的运维工作里头,你是更偏向借助强化监控预警去避开风险耶,还是在数据出现损坏之后转而依赖强大的备份策略来予以恢复?欢迎于评论区去分享你的经验以及观点,要是觉着本文具备助益,也请进行点赞支援并且分享给更多兴许有需要的伙伴嘎。 。
