在日常的服务器运维中,数据安全与读写性能永远是核心矛盾。我自己在这方面也摔过不少跟头,最深切的体会就是:用Linux系统做RAID,绝不是敲几行命令那么简单。它涉及到硬件的选型、阵列级别的权衡、还有后期故障的预判。今天,我就把这十多年积累下来的实战经验掰开揉碎了讲,希望能帮你在部署时少走一些弯路。
软RAID和硬RAID哪个好
很多刚接触Linux的朋友都会有这个困惑,到底是买昂贵的RAID卡,还是用系统自带的mdadm工具。从我经手过的上百台服务器来看,软RAID在绝大多数场景下其实更有优势。现在的CPU性能早已过剩,软RAID占用的那点计算资源几乎可以忽略不计,而且它完全不受硬件厂商绑定,硬盘随便插到任何一台Linux机器上都能直接识别阵列。
不过硬RAID也有它不可替代的场合。如果你跑的是数据库这类对写入延迟极其敏感的应用,带缓存和备用电池的硬RAID卡能显著提升性能。但要注意,低端几百块的RAID卡反而是灾难,一旦卡坏了,你必须找同型号的卡才能恢复数据。我的建议是,普通文件服务器选软RAID,关键数据库才考虑硬RAID。
不同场景选哪种RAID级别
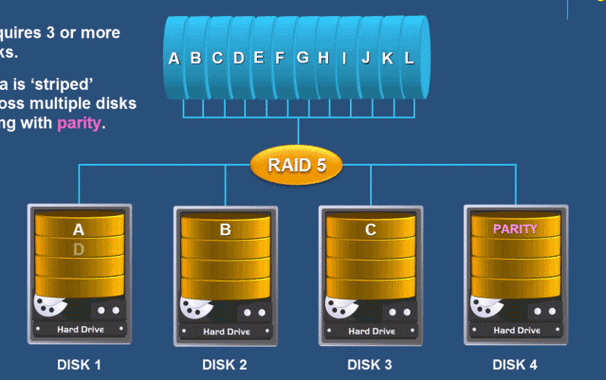
千万别以为RAID 10就是万能解药,不同业务场景对容量、性能和安全的侧重点完全不同。比如你搭建的是备份服务器,存储的都是压缩包,那么RAID 5或者RAID 6就很合适。RAID 6允许同时坏两块盘,虽然写入时会有校验计算的开销,但现在服务器CPU完全扛得住,性价比非常高。
如果跑的是虚拟机磁盘镜像或者数据库日志,那你必须上RAID 10。我曾经在一个Nginx日志服务器上图省事用了RAID 5,结果重建时第二块盘又坏了,整个阵列直接崩溃。RAID 10虽然只有一半的可用容量,但它的随机写入性能是RAID 5的好几倍,而且任意坏一块盘都不影响另一组。至于RAID 0,除非你存的是临时数据,否则千万别碰。
用mdadm命令组建阵列步骤
实际操作中,第一步是确认硬盘设备名,用lsblk或者fdisk -l查看新添加的硬盘,通常显示为sdb、sdc这样的名称。注意千万不要把系统盘也加进去了,我就见过有人把装系统的sda一起组RAID,结果重启后系统都起不来。确认无误后,用mdadm --create命令创建,比如组建RAID 10要用到--level=10和--raid-devices=4这两个参数。
创建完成后一定要记得生成配置文件,这条命令最容易被人忽略。执行mdadm --detail --scan >> /etc/mdadm/mdadm.conf,然后再更新initramfs,否则重启后阵列不会自动激活。还有格式化这一步,我建议用mkfs.ext4的时候加上-E stride参数,根据RAID的条带大小优化对齐,能让随机读写性能提升两成左右。最后挂载到/data或者/var/lib/mysql这样的目录linux系统做raid,写上/etc/fstab千万别用设备名,要用UUID。
硬盘故障如何更换修复
阵列建好了不代表万事大吉linux系统做raid,硬盘迟早会坏,提前演练过更换流程的运维才是合格的运维。先用mdadm --detail /dev/md0查看阵列状态,确认哪个设备号出现了Faulty标记。比如/dev/sdc坏了,正确的做法是用mdadm --manage /dev/md0 --fail /dev/sdc标记为故障,然后再--remove /dev/sdc把它踢出阵列。
接下来物理更换新硬盘,用fdisk把新盘的分区表做成和原来坏盘一模一样,只需要复制分区信息不需要格式化。然后用--add /dev/md0 /dev/sdc把新盘加回去,系统会自动开始重建。这时候用cat /proc/mdstat能看到重建进度,记得最好在业务低峰期操作。千万不要因为重建慢就重启机器,我有次手贱中断了重建,导致整块盘需要重新同步,耗时翻了一倍。
阵列性能瓶颈在哪里
很多人做完RAID就跑个dd测试,看到读写几百MB就以为没问题了,这是很大的误区。dd测的是顺序读写,而实际业务大多是随机读写。你应该用fio工具模拟真实场景,比如测试4K随机写,命令是fio --rw=randwrite --bs=4k。如果发现IO延迟超过10毫秒,那问题很可能出在条带大小和块大小的匹配上。
另外缓存策略被严重低估了。对于软RAID,Linux默认的I/O调度器是mq-deadline或者kyber,如果是NVMe固态盘做RAIDlinux运维面试题linux命令行和shell脚本编程宝典,建议把调度器改成none直接走内核轮询。还有文件系统挂载参数,noatime和nodiratime能减少不必要的元数据写入,如果是XFS文件系统,largeio和swalloc这两个挂载选项也能提升大文件性能。排查的时候多用iostat -x 1看真实利用率,别猜。
数据恢复的可能性有多大
RAID不是备份,这句话我至少对客户说过几百遍,但真正听进去的没几个。如果你的阵列因为两块盘同时故障而崩溃,千万别急着重建或者格式化。用ddrescure先把每块盘做成镜像文件,存到另一台机器上,然后再用mdadm --assemble --scan尝试组装,很多时候只是超级块信息错乱了。
如果真的无法恢复,可以试试磁盘编辑器。我曾经用WinHex逐个查看每个硬盘的校验块,手动推导RAID参数比如起始扇区、条带大小和盘的顺序。这个过程极其繁琐,但确实救回过一次公司三年的财务数据。不过说再多,最可靠的方案还是异地冷备,每天用rsync把重要数据拖到独立硬盘上。RAID只保在线可用,不保数据绝对安全。
读完这篇经验分享,我想问一句实在话:你对目前的生产环境服务器,做过一次毫无水分的RAID故障实战演练吗?
