在Linux系统中运行.cu文件,也就是CUDA源文件,对于很多想利用GPU加速计算的开发者来说至关重要。下面我将详细介绍在Linux系统运行.cu文件的相关内容。
CUDA环境安装
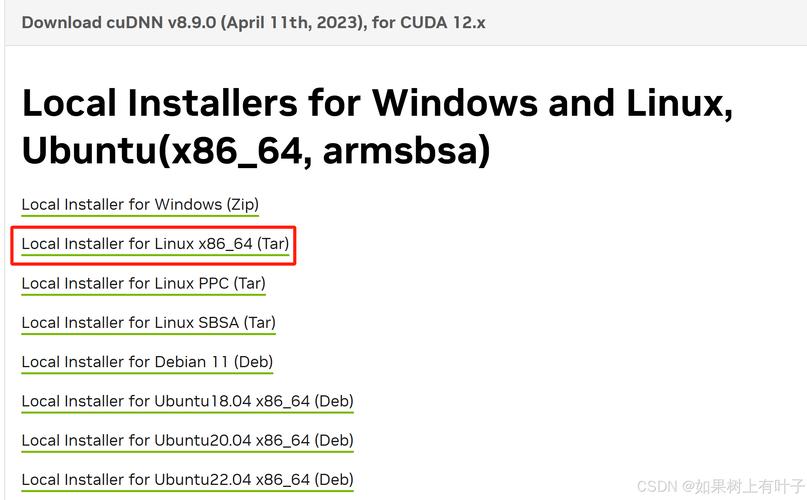
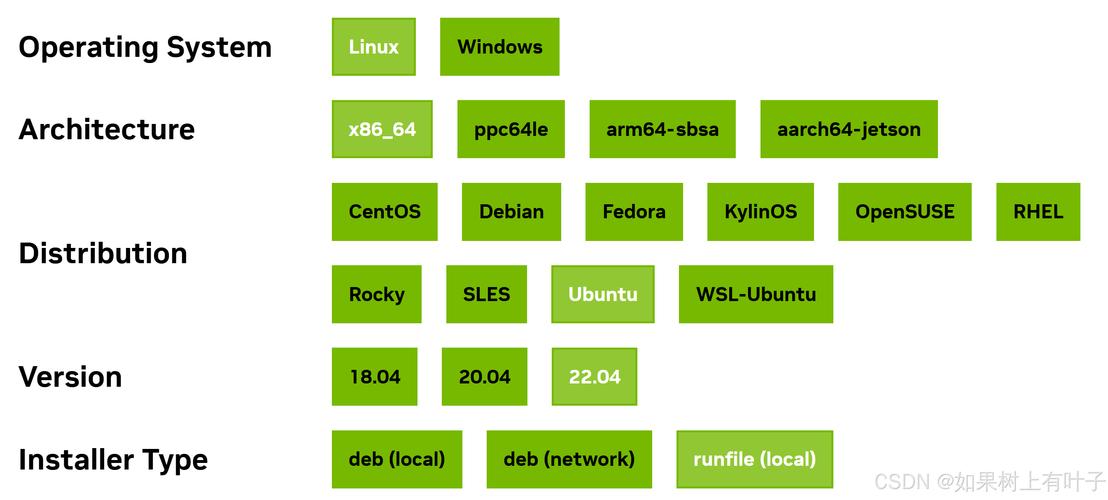
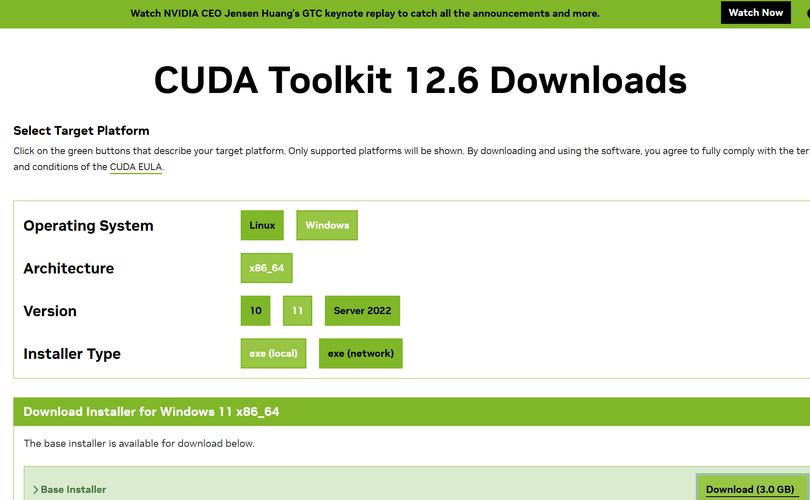
首先得确保你的Linux系统已经安装了CUDA工具包。要先确认系统是否满足CUDA的安装要求,比如合适的显卡驱动、系统内核版本等。可以去NVIDIA官方网站下载与显卡和系统匹配的CUDA版本,下载后按照官方的安装指南一步步操作。安装完成后,还需配置环境变量,像设置PATH和LD_LIBRARY_PATH,这样系统才能找到CUDA相关的库和工具。
编写.cu文件
准备运行.cu文件之前,得有一个可运行的CUDA程序。可以使用文本编辑器,如vim、nano等编写.cu文件。在文件里,要包含必要的头文件红帽linux,编写主函数和核函数。核函数就是在GPU上运行的代码,通常在括号里指定线程和块的数量。编写时要注意代码的规范性和逻辑性,避免出现语法错误。
编译.cu文件
编写好.cu文件后,就需要进行编译。可以使用nvcc工具,它是NVIDIA提供的CUDA编译器。在终端里,使用命令“nvcc -o output_file input_file.cu”,其中“output_file”是编译后生成的可执行文件的名称,“input_file.cu”是你编写的.cu文件。nvcc会把.cu文件编译成可在Linux系统上运行的二进制文件。
运行可执行文件
编译成功后,会生成一个可执行文件。在终端使用命令“./output_file”(这里的“output_file”就是上面生成的可执行文件的名称)就能运行这个程序了。运行前要确保当前用户有执行这个文件的权限,如果没有,可以使用“chmod +x output_file”命令赋予权限。运行过程中,如果程序有输入要求,要按照提示输入相应的数据。
调试运行问题
运行中可能会遇到各种问题。比如出现编译错误,要仔细查看终端给出的错误信息,定位到出错的行,检查代码是否有语法错误或逻辑错误。如果运行没有结果或者结果不对,要检查核函数的参数设置是否正确linux培训班,数据传递是否正常。调试时可以使用一些工具linux运行.cu,如cuda-gdb来帮助定位问题。
性能优化
想让.cu文件运行得更高效,就需要进行性能优化。可以优化核函数的并行性,合理设置线程和块的数量,减少线程间的同步开销。还可以优化内存访问模式,减少内存带宽的压力。另外,使用CUDA提供的一些高级特性,如共享内存、纹理内存等linux运行.cu,也能提高程序的性能。
你在运行.cu文件时遇到过什么特别难解决的问题吗?欢迎在评论区留言分享,觉得文章有用的话点赞并分享给身边的开发者朋友吧。
