在Linux服务器性能调优领域,NUMA(非统一内存访问)是一个无法绕开的核心概念。随着多核处理器成为主流,理解NUMA架构并掌握相关命令,对于解决高性能计算、虚拟化及数据库等场景下的内存性能瓶颈至关重要。NUMA通过将CPU和内存划分为多个节点,让每个CPU优先访问本地内存,从而提升扩展性,但配置不当反而会导致性能显著下降。
什么是Linux NUMA架构
现代多路服务器通常采用NUMA架构来克服传统SMP架构的内存访问瓶颈。每个NUMA节点包含若干CPU核心和本地内存,CPU访问本地内存速度很快,而访问其他节点的远程内存则延迟较高。这种设计在高负载下若未妥善管理,会导致应用程序大量跨节点访问内存,显著增加延迟。
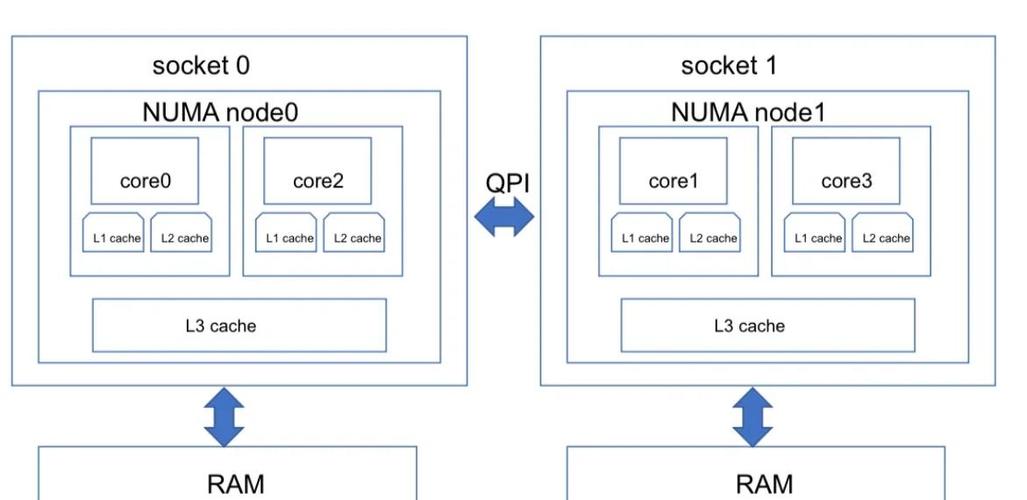
操作系统通过系统总线互联各个NUMA节点。例如一台双路服务器可能包含两个NUMA节点,每个节点各有16个CPU核心和64GB内存。理解这种物理拓扑是进行NUMA优化的基础,它解释了为什么简单的内存访问在不同位置会有截然不同的性能表现。
如何查看NUMA节点拓扑
使用numactl --hardware命令可以快速获取系统NUMA拓扑的完整信息。该命令会列出所有可用节点、每个节点的内存总量及空闲内存、节点间的距离表。距离值表示访问延迟的相对成本,本地节点距离通常为10,远程节点可能为20或更高。
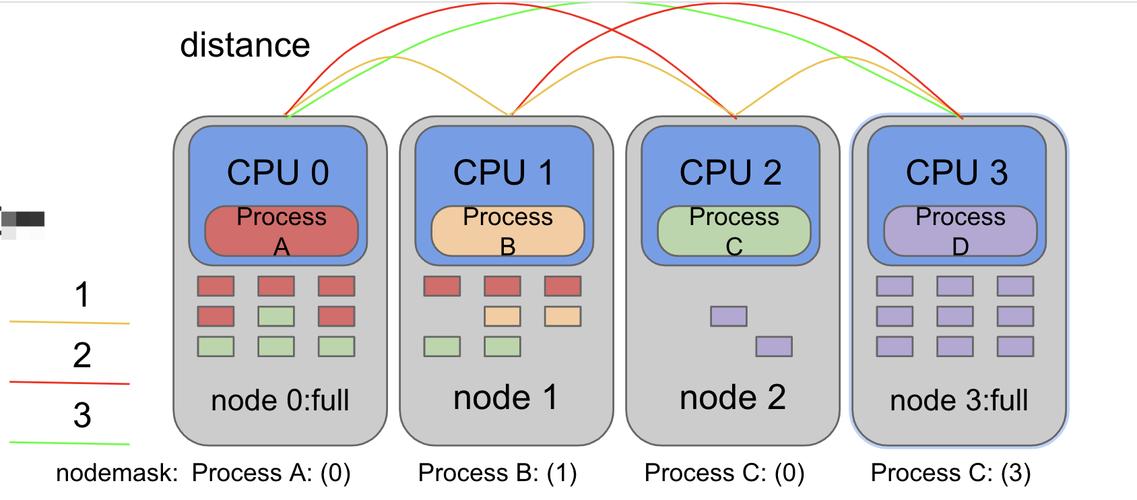
另一个实用工具是lscpu,它在”NUMA node(s)”行显示节点数量,并在底部详细列出每个CPU核心所属的节点。结合numastat命令可以查看各节点的内存分配统计,包括本地、远程分配次数和分配失败情况,为后续优化提供数据支撑。
为什么需要NUMA内存绑定
默认情况下Linux内核尝试将内存分配在运行进程的本地节点,但在高内存压力或进程迁移时,这种策略可能失效。当进程频繁访问远程内存时,延迟可能增加50%以上,对延迟敏感的应用这是不可接受的。
通过numactl --membind和--cpubind参数,可以将关键进程严格绑定到特定NUMA节点。例如数据库服务可以绑定到节点0,而Web服务绑定到节点1linux numa 命令,确保各自使用本地内存。这种手动干预虽然增加了管理成本linux numa 命令,但能带来显著且稳定的性能提升。
怎样使用numactl控制策略
numactl工具提供多种内存分配策略:--localalloc要求仅在本地节点分配(默认);--preferred优先使用指定节点;--interleave在所有或指定节点间轮询分配;--membind强制使用指定节点。
对于内存密集型应用,--interleave策略能有效平衡内存访问压力,特别适合跨节点访问频繁的场景。而--membind则适用于对延迟极其敏感的服务。实际使用时需结合--cpubind将进程的CPU执行也限制在特定节点linux视频,实现完全绑定。
如何监控NUMA性能表现
numastat是监控NUMA内存分配状况的首选工具linux设置默认网关,它显示各节点的numa_hit(本地分配成功)、numa_miss(被迫远程分配)等关键指标。理想情况下,numa_hit应远高于numa_miss,否则表明NUMA配置需要优化。
除了专用工具,/proc/vmstat中的numa_ptes_scanned等条目也提供额外信息。性能测试时应同时使用perf工具记录numa-misses事件,它能精确量化测试期间发生的远程内存访问次数,帮助定位性能瓶颈。
NUMA优化常见误区
过度绑定是常见错误之一,将所有进程严格绑定可能导致节点负载不均。实际上,对于内存需求不高的进程,内核的自动平衡机制可能更有效。优化前应先通过监控确认存在NUMA问题,而非盲目绑定。
另一个误区是忽视应用程序自身的NUMA感知能力。现代数据库和Java虚拟机大多内置了NUMA优化功能,如MySQL的innodb_numa_interleave和JVM的UseNUMA参数。启用这些参数往往比外部绑定更有效,因为它们能在应用层面做出更智能的决策。
在实际工作中,你是通过哪些迹象发现系统中存在NUMA性能问题的?欢迎在评论区分享你的诊断经验,如果觉得本文有帮助,请点赞支持并分享给更多同事!
