less file1 file2 file3
:n #切换到下一个文件
:p #切换到上一个文件
:x #切换到第一个文件
:d #从当前列表移除文件
显示文本背部内容--head
head命令的作用如同它的名子一样,用于显示文件的开头部份文本。
常见用法如下:
head -n 100 file #显示file的前100行
head -n -100 file #显示file的除最后100行以外的内容。
显示文本尾部内容--tail
和head命令类似,只不过tail命令用于读取文本尾部部份内容:
tail -100 file #显示file最后100行内容
tail -n +100 file #从第100行开始显示file内容
tail还有一个比较实用的用法,用于实时文本更新内容。例如说,有一个日志文件正在写,而且实时在更新,就可以用命令:
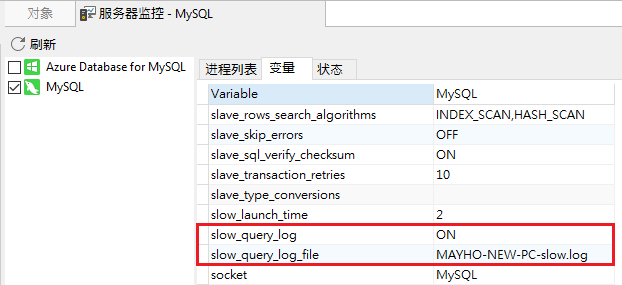
tail -f logFile
对于更新的日志内容,会实时复印到终端上linux查看log日志命令linux查看log日志命令,方面查看实时日志。
指定次序显示文本--sort
sort可用于对文本进行排序并显示,默认为字典倒序。
比如有一段文本test.txt内容如下:
vim
count
fail
help
help
dead
apple
1.倒序显示文本
使用命令:
sort test.txt
apple
count
dead
fail
help
help
vim
文本内容将以倒序显示。
2.逆序显示
相关参数-r:
sort -r test.txt
vim
help
help
fail
dead
count
apple
3.除去重复的行
我们可以观察到,上面的help有两行,假如我们不想见到重复的行呢?可以使用参数-u,比如:
sort -u test.txt
apple
count
dead
fail
help
vim
可以看见help行不再重复显示。
4.根据数字排序
假如依照字典排序linux vi命令,10将会在2的后面,因而我们须要根据数字大小排序:
sort -n file
因为本文篇幅有限,不在本文展开介绍,后续将单独介绍sort命令的妙用。
过滤显示文本--sed
sed是一个流编辑器,功能十分强悍,但本文只介绍文本查看相关功能。
1.显示匹配关键字行
有时侯查看日志,可能只须要查看包含个别关键字的日志行:
sed -n "/string/p" logFile
里面的命令表示复印包含string的行。
2.复印指定行
sed -n "1,5p" logFile #打印第1到5行
sed -n '3,5{=;p}' logFile #打印3到5行,并且打印行号
sed -n "10p" logFIle #打印第10行
去重显示文本--uniq
常见用法如下:
uniq file #去除重复的行
uniq -c file #去除重复的行,并显示重复次数
uniq -d file #只显示重复的行
uniq -u file #只显示出现一次的行
uniq -i file #忽略大小写,去除重复的行
uniqe -w 10 file #认为前10个字符相同,即为重复
文本编辑查看--vi
查看文件也很简单:
vi file
而从vi发展下来的被誉为编辑器之神的vim有着更加大大的功能,这儿不作展开。
总结
文本查看命令较多,可按照使用场景不同选择使用不同的命令。有些命令的用法较多,本文仅介绍精典用法,更多用法可使用man命令查看。好多命令可以结合其他命令使用,比如ps-elf|more,分页显示进程信息等等linux论坛,更多用法可自行探求。
