作为一线系统运维工程师centos系统管理centos系统管理,我每天打交道最多的就是CentOS系统。这篇文章主要围绕CentOS系统管理的核心实践展开,从日常维护到性能调优,从安全加固到故障排查,都是我这些年踩过坑、填过土后的真实经验。无论你是刚接触Linux的新手,还是有一定经验的运维,希望这些内容能帮你少走弯路。
系统更新怎么防止出问题
CentOS的稳定性很大程度上依赖于软件包的版本锁定。我见过太多案例,有人直接执行yum update -y后导致内核与驱动程序不兼容,服务直接起不来。我的建议是:非安全更新不要批量升级,使用yum update --security只打安全补丁。如果必须更新内核,务必先在一台测试机验证,并确保/boot分区预留足够空间。

生产环境建议配置yum版本锁定插件yum-plugin-versionlock。把关键软件如nginx、mysql的版本锁住,避免误操作导致升级。同时建立更新回滚预案,备份/etc目录和关键数据库。上周我刚帮客户恢复了一台误更新导致网络服务崩溃的服务器,就是靠事前做的/etc全量备份。
日志太大怎么清理干净
很多人上来就删/var/log/messages红旗linux6.0教程,这是错误做法。正确姿势是配置logrotate轮转策略。CentOS默认已安装logrotate,你只需要在/etc/logrotate.d/下写对应的配置文件。比如针对nginx日志,设置daily每天切割,保留30天,执行postrotate重载服务。

更激进的方案可以用systemd的journalctl限制日志体积。修改/etc/systemd/journald.conf,设置SystemMaxUse=200Mlinux,这样journal日志不会超过200MB。同时开启远程日志服务器,把重要日志实时传输出去。上周某台机器根分区写满就是被journal撑爆的,加了限制后问题彻底解决。
防火墙配置有哪些坑
很多初学者习惯关掉firewalld用iptables,甚至直接systemctl stop firewalld,这在等保评测中直接不及格。正确做法是学会firewalld的富规则。比如只允许某特定IP访问ssh,用firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address="192.168.1.100" port port="22" protocol="tcp" accept'。
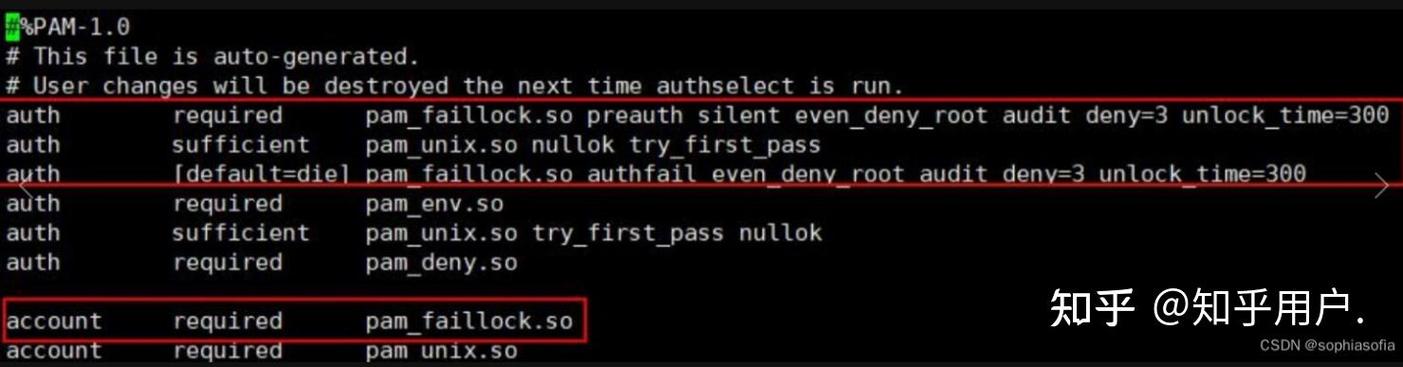
另一个坑是修改端口后忘记更新selinux策略。CentOS7开始selinux默认 enforcing,如果你把ssh端口改成2222,必须执行semanage port -a -t ssh_port_t -p tcp 2222。我处理过大量ssh无法连接的工单,八成是改了端口但selinux没放行,剩下两成是防火墙没reload。
磁盘满了如何快速定位
不要只盯着df -h看。有时df显示已用100%,但du统计目录总大小却对不上,这是文件被进程占用但已删除。用lsof | grep deleted找出那些还在占用磁盘空间的文件句柄,重启对应服务或清空文件。上周刚处理一个案例,nginx删除旧日志后没重载,导致40G磁盘空间无法释放。
定位大文件我用ncdu这个工具,交互式界面比du快得多。安装后用ncdu /逐层查看,立马找出哪个目录在吞噬空间。同时要养成习惯,docker容器用--log-opt限制日志大小,避免单个容器日志写爆宿主机的/var分区。
服务自启总失败怎么办
首先区分sysvinit和systemd。CentOS7全面转向systemd,不要再把脚本丢进/etc/rc.local了。检查服务自启用systemctl is-enabled,设置自启用systemctl enable。如果enable失败,通常是/etc/systemd/system/下的service文件写错了。重点关注After和Requires字段,确保网络挂载等依赖服务先启动。
还有一种情况是服务启动太快,依赖的端口或文件还没就绪。在service文件里加Restart=on-failure和RestartSec=10,让systemd帮你在失败后重试。上次部署Java应用,每次开机mysql还没完全启动,springboot就开始连接,加上重启策略后问题解决。这是微服务架构下非常实用的技巧。
如何快速排查系统负载高

不要一上来就重启服务器。首先用uptime确认平均负载,再用top看CPU使用率,区分是sy(内核态)高还是us(用户态)高。sy高通常与磁盘IO或网络驱动有关,用iostat -x 1看await和svctm;us高就定位到具体进程,用strace -p PID跟踪系统调用,八成是程序逻辑问题。
内存方面别只看free -h,更要看cat /proc/meminfo里的MemAvailable。这是真实可用的内存。swap使用率高不一定是内存不足,可能是系统设置了vm.swappiness过高。生产环境建议设为10,避免过度使用swap。还有个小技巧:用perf工具分析CPU热点函数,我靠这个定位过两次nginx模块编译参数导致的性能回退。
你在日常运维CentOS时,遇到过最让你抓狂的问题是什么?是内核崩溃还是网络中断?欢迎在评论区分享你的“救火”经历,觉得本文有用请点个赞、转给身边的同事,后续我会继续分享更多实战案例。
