在Linux系统上部署Oracle集群是一项复杂但至关重要的技术工作,它能为关键业务系统提供高可用性和可扩展性。成功的安装不仅需要严格遵循官方文档步骤,更需要对操作系统、存储、网络和Oracle软件本身有深入的理解。本文将从实际经验出发,系统性地拆解整个安装过程的核心要点和常见陷阱。
为什么要在linux上安装oracle集群
高可用性是现代企业数据架构的基石。Oracle集群(Oracle RAC)通过在多个服务器节点上运行同一个数据库,实现了硬件和软件的冗余。这意味着即使单个服务器或实例发生故障,整个数据库服务仍然可以继续运行,从而将计划内或计划外的停机时间降到最低。
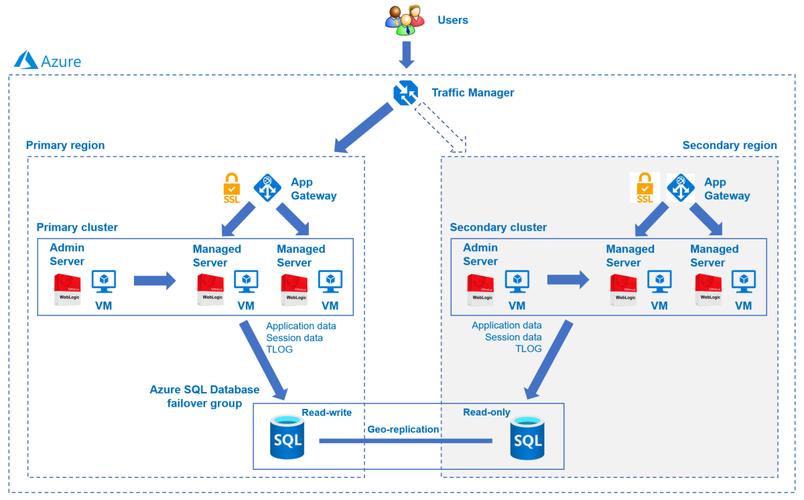
除了高可用性,Oracle集群还提供了优异的横向扩展能力。当业务负载增长时,可以通过向集群中添加新的服务器节点来线性地提升数据库的整体处理能力,如联机事务处理(OLTP)性能。这使得它非常适合那些对业务连续性要求极高、且数据量和访问量不断增长的应用场景。
安装oracle集群前需要准备什么
充分的准备工作是成功的一半。首先,你需要确认所有服务器节点的硬件配置满足Oracle的最低要求,这包括足够的内存、CPU核心数以及兼容的处理器架构。其次,必须规划并配置好共享存储,这是集群数据同步的基础,通常使用ASM(自动存储管理)来管理共享磁盘组。
软件层面的准备同样繁琐。确保所有节点安装的是Oracle官方认证的Linux发行版和内核版本linux命令,并已安装所有必要的操作系统包和依赖。此外查看系统版本linux,需要为Oracle软件和数据库创建专用的操作系统用户和组(如oracle、oinstall、dba),并统一配置好用户环境变量、资源限制和目录权限。
如何规划oracle集群的网络配置
网络规划是集群稳定运行的血管。Oracle集群要求至少配置两张独立的物理网卡,分别用于公网(Public)和私网(Private)通信。公网用于客户端应用连接和节点管理,私网则专门用于集群内部节点间的心跳(Cache Fusion)通信和数据同步,这对网络延迟和带宽有严格要求。
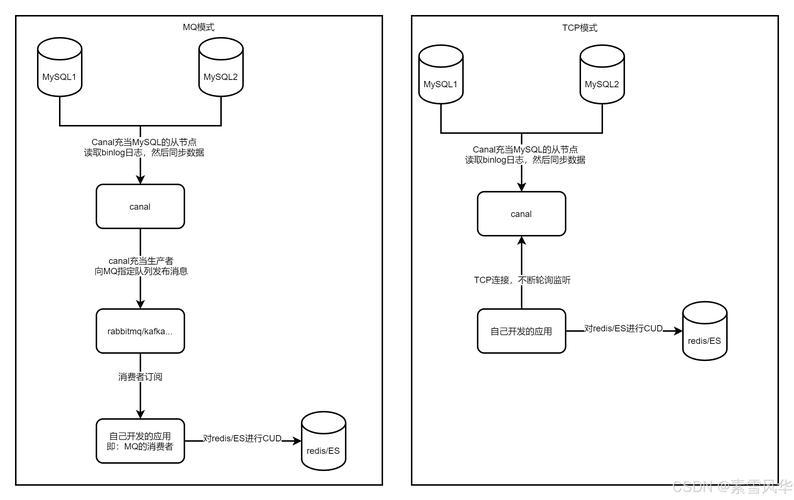
私网必须使用专用交换机或VLAN进行隔离,绝对不能与公网流量混合,以避免网络拥塞导致集群脑裂。每个节点的网卡名称、IP地址、主机名解析(通过/etc/hosts或DNS)必须在所有节点上保持完全一致。还需要正确配置SCAN(Single Client Access Name)以简化客户端的连接。
如何安装oracle集群软件
安装集群软件是整个流程的核心步骤。首先,在所有节点上以相同路径解压Oracle Grid Infrastructure的安装包。运行安装程序后,选择“为集群安装和配置Grid Infrastructure”。在配置步骤中,需要指定集群名称、扫描名称和端口,并添加所有集群节点的信息。
安装程序会运行一系列预检查,包括操作系统参数、内核版本、存储权限等。必须确保所有检查项全部通过。之后,安装程序会复制文件、链接Oracle二进制文件,并在最后执行root脚本。务必按照提示,依次在每个节点上以root身份执行指定的脚本,这是完成集群软件安装的关键。

如何创建oracle集群数据库
集群软件安装完毕后,就可以在其上创建数据库了。使用DBCA(Database Configuration Assistant)工具,选择“创建数据库”并勾选“Oracle Real Application Clusters database”选项。在节点选择页面,将希望运行数据库实例的所有节点都添加进来。
接下来是关键存储配置,强烈推荐使用ASM。你需要指定用于存储数据文件、快速恢复区(FRA)的ASM磁盘组。然后,像创建单实例数据库一样,配置数据库名称、字符集、内存管理参数(如SGA、PGA大小)等。DBCA会完成所有创建工作,并在每个选定的节点上启动一个数据库实例。
oracle集群安装后如何测试
安装完成绝不意味着大功告成,全面的测试至关重要。首先,测试节点隔离功能:可以尝试突然关闭一个节点的公网或私网,观察集群是否能正确将该节点驱逐(evict),而其他节点上的数据库实例继续提供服务,且没有数据损坏。
进行应用层面的故障转移测试。使用一个测试应用连接到数据库,然后在数据库运行期间linux安装oracle集群,手动关闭其中一个节点的数据库实例或重启整个服务器。观察应用连接是否能自动、平滑地迁移到其他存活节点的实例上,整个过程对前端应用应该是透明且感知时间极短的。
你在部署Oracle RAC集群时,遇到的最大挑战是什么?是共享存储的配置、网络延迟问题linux安装oracle集群,还是安装过程中的某个具体报错?欢迎在评论区分享你的经验和解决方案,如果觉得本文有帮助,请点赞并分享给更多需要的小伙伴。
